 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Self-Improvement of Large Language Models by Test-time Training with Verifier-Driven Sample Selection
May 26, 2025Learning to adapt pretrained language models to unlabeled, out-of-distribution data is a critical challenge, as models often falter on structurally novel reasoning tasks even while excelling within their training distribution. We introduce a new framework called VDS-TTT - Verifier-Driven Sample Selection for Test-Time Training to efficiently address this. We use a learned verifier to score a pool of generated responses and select only from high ranking pseudo-labeled examples for fine-tuned adaptation. Specifically, for each input query our LLM generates N candidate answers; the verifier assigns a reliability score to each, and the response with the highest confidence and above a fixed threshold is paired with its query for test-time training. We fine-tune only low-rank LoRA adapter parameters, ensuring adaptation efficiency and fast convergence. Our proposed self-supervised framework is the first to synthesize verifier driven test-time training data for continuous self-improvement of the model. Experiments across three diverse benchmarks and three state-of-the-art LLMs demonstrate that VDS-TTT yields up to a 32.29% relative improvement over the base model and a 6.66% gain compared to verifier-based methods without test-time training, highlighting its effectiveness and efficiency for on-the-fly large language model adaptation.
Balancing Computation Load and Representation Expressivity in Parallel Hybrid Neural Networks
May 26, 2025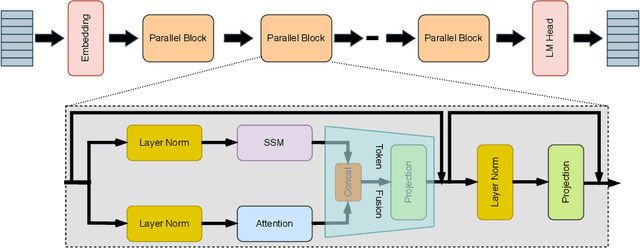
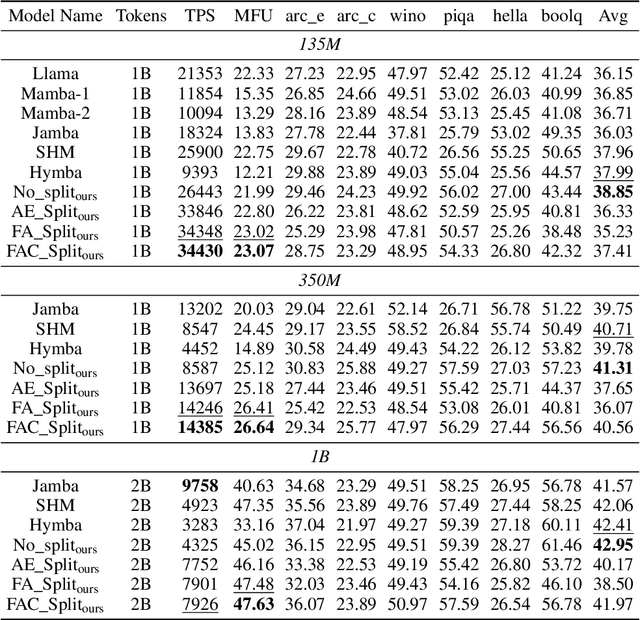
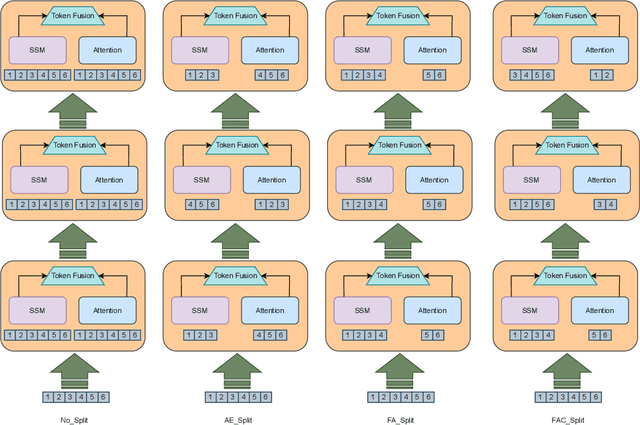
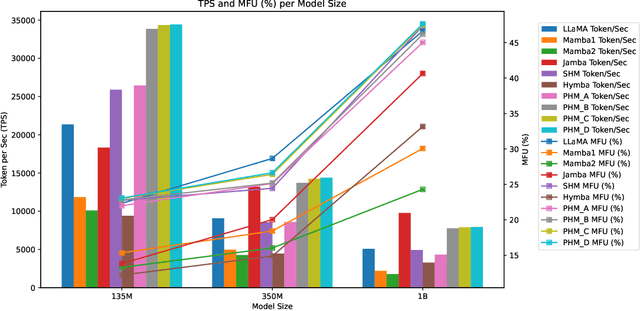
Attention and State-Space Models (SSMs) when combined in a hybrid network in sequence or in parallel provide complementary strengths. In a hybrid sequential pipeline they alternate between applying a transformer to the input and then feeding its output into a SSM. This results in idle periods in the individual components increasing end-to-end latency and lowering throughput caps. In the parallel hybrid architecture, the transformer operates independently in parallel with the SSM, and these pairs are cascaded, with output from one pair forming the input to the next. Two issues are (i) creating an expressive knowledge representation with the inherently divergent outputs from these separate branches, and (ii) load balancing the computation between these parallel branches, while maintaining representation fidelity. In this work we present FlowHN, a novel parallel hybrid network architecture that accommodates various strategies for load balancing, achieved through appropriate distribution of input tokens between the two branches. Two innovative differentiating factors in FlowHN include a FLOP aware dynamic token split between the attention and SSM branches yielding efficient balance in compute load, and secondly, a method to fuse the highly divergent outputs from individual branches for enhancing representation expressivity. Together they enable much better token processing speeds, avoid bottlenecks, and at the same time yield significantly improved accuracy as compared to other competing works. We conduct comprehensive experiments on autoregressive language modeling for models with 135M, 350M, and 1B parameters. FlowHN outperforms sequential hybrid models and its parallel counterpart, achieving up to 4* higher Tokens per Second (TPS) and 2* better Model FLOPs Utilization (MFU).
GC-KBVQA: A New Four-Stage Framework for Enhancing Knowledge Based Visual Question Answering Performance
May 25, 2025Knowledge-Based Visual Question Answering (KB-VQA) methods focus on tasks that demand reasoning with information extending beyond the explicit content depicted in the image. Early methods relied on explicit knowledge bases to provide this auxiliary information. Recent approaches leverage Large Language Models (LLMs) as implicit knowledge sources. While KB-VQA methods have demonstrated promising results, their potential remains constrained as the auxiliary text provided may not be relevant to the question context, and may also include irrelevant information that could misguide the answer predictor. We introduce a novel four-stage framework called Grounding Caption-Guided Knowledge-Based Visual Question Answering (GC-KBVQA), which enables LLMs to effectively perform zero-shot VQA tasks without the need for end-to-end multimodal training. Innovations include grounding question-aware caption generation to move beyond generic descriptions and have compact, yet detailed and context-rich information. This is combined with knowledge from external sources to create highly informative prompts for the LLM. GC-KBVQA can address a variety of VQA tasks, and does not require task-specific fine-tuning, thus reducing both costs and deployment complexity by leveraging general-purpose, pre-trained LLMs. Comparison with competing KB-VQA methods shows significantly improved performance. Our code will be made public.
DAS: A Deformable Attention to Capture Salient Information in CNNs
Nov 20, 2023

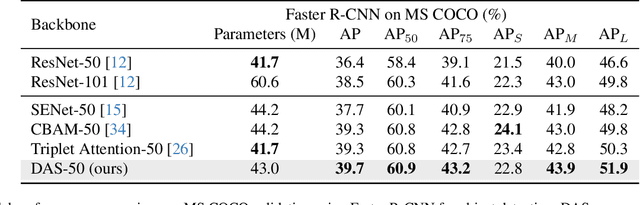

Convolutional Neural Networks (CNNs) excel in local spatial pattern recognition. For many vision tasks, such as object recognition and segmentation, salient information is also present outside CNN's kernel boundaries. However, CNNs struggle in capturing such relevant information due to their confined receptive fields. Self-attention can improve a model's access to global information but increases computational overhead. We present a fast and simple fully convolutional method called DAS that helps focus attention on relevant information. It uses deformable convolutions for the location of pertinent image regions and separable convolutions for efficiency. DAS plugs into existing CNNs and propagates relevant information using a gating mechanism. Compared to the O(n^2) computational complexity of transformer-style attention, DAS is O(n). Our claim is that DAS's ability to pay increased attention to relevant features results in performance improvements when added to popular CNNs for Image Classification and Object Detection. For example, DAS yields an improvement on Stanford Dogs (4.47%), ImageNet (1.91%), and COCO AP (3.3%) with base ResNet50 backbone. This outperforms other CNN attention mechanisms while using similar or less FLOPs. Our code will be publicly available.
DragD3D: Vertex-based Editing for Realistic Mesh Deformations using 2D Diffusion Priors
Oct 06, 2023Direct mesh editing and deformation are key components in the geometric modeling and animation pipeline. Direct mesh editing methods are typically framed as optimization problems combining user-specified vertex constraints with a regularizer that determines the position of the rest of the vertices. The choice of the regularizer is key to the realism and authenticity of the final result. Physics and geometry-based regularizers are not aware of the global context and semantics of the object, and the more recent deep learning priors are limited to a specific class of 3D object deformations. In this work, our main contribution is a local mesh editing method called DragD3D for global context-aware realistic deformation through direct manipulation of a few vertices. DragD3D is not restricted to any class of objects. It achieves this by combining the classic geometric ARAP (as rigid as possible) regularizer with 2D priors obtained from a large-scale diffusion model. Specifically, we render the objects from multiple viewpoints through a differentiable renderer and use the recently introduced DDS loss which scores the faithfulness of the rendered image to one from a diffusion model. DragD3D combines the approximate gradients of the DDS with gradients from the ARAP loss to modify the mesh vertices via neural Jacobian field, while also satisfying vertex constraints. We show that our deformations are realistic and aware of the global context of the objects, and provide better results than just using geometric regularizers.
Simulated Annealing in Early Layers Leads to Better Generalization
Apr 10, 2023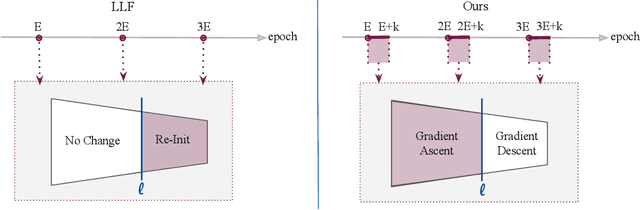
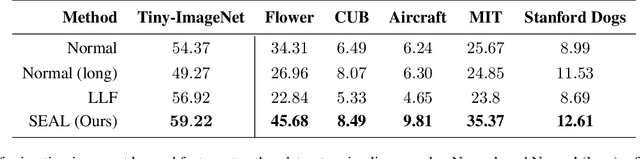
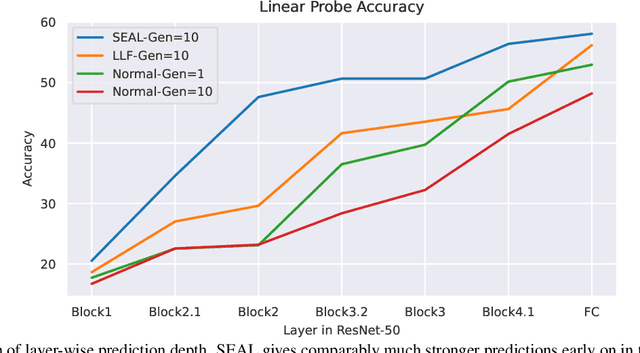
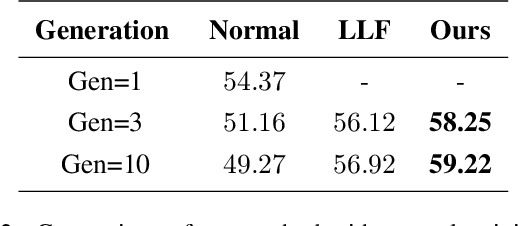
Recently, a number of iterative learning methods have been introduced to improve generalization. These typically rely on training for longer periods of time in exchange for improved generalization. LLF (later-layer-forgetting) is a state-of-the-art method in this category. It strengthens learning in early layers by periodically re-initializing the last few layers of the network. Our principal innovation in this work is to use Simulated annealing in EArly Layers (SEAL) of the network in place of re-initialization of later layers. Essentially, later layers go through the normal gradient descent process, while the early layers go through short stints of gradient ascent followed by gradient descent. Extensive experiments on the popular Tiny-ImageNet dataset benchmark and a series of transfer learning and few-shot learning tasks show that we outperform LLF by a significant margin. We further show that, compared to normal training, LLF features, although improving on the target task, degrade the transfer learning performance across all datasets we explored. In comparison, our method outperforms LLF across the same target datasets by a large margin. We also show that the prediction depth of our method is significantly lower than that of LLF and normal training, indicating on average better prediction performance.
Prototype-Sample Relation Distillation: Towards Replay-Free Continual Learning
Mar 26, 2023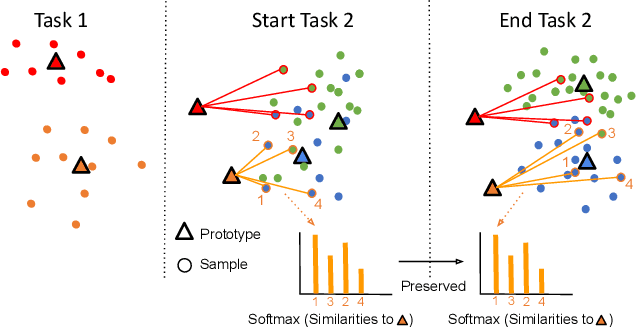



In Continual learning (CL) balancing effective adaptation while combating catastrophic forgetting is a central challenge. Many of the recent best-performing methods utilize various forms of prior task data, e.g. a replay buffer, to tackle the catastrophic forgetting problem. Having access to previous task data can be restrictive in many real-world scenarios, for example when task data is sensitive or proprietary. To overcome the necessity of using previous tasks data, in this work, we start with strong representation learning methods that have been shown to be less prone to forgetting. We propose a holistic approach to jointly learn the representation and class prototypes while maintaining the relevance of old class prototypes and their embedded similarities. Specifically, samples are mapped to an embedding space where the representations are learned using a supervised contrastive loss. Class prototypes are evolved continually in the same latent space, enabling learning and prediction at any point. To continually adapt the prototypes without keeping any prior task data, we propose a novel distillation loss that constrains class prototypes to maintain relative similarities as compared to new task data. This method yields state-of-the-art performance in the task-incremental setting where we are able to outperform other methods that both use no data as well as approaches relying on large amounts of data. Our method is also shown to provide strong performance in the class-incremental setting without using any stored data points.
Probing Representation Forgetting in Supervised and Unsupervised Continual Learning
Apr 05, 2022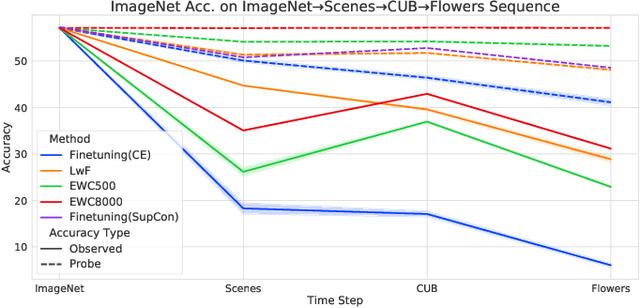
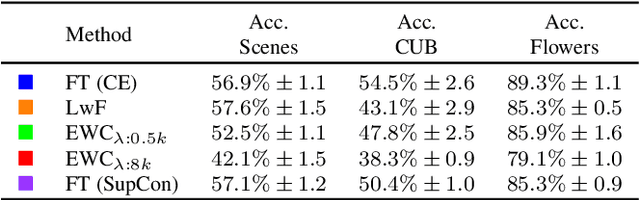
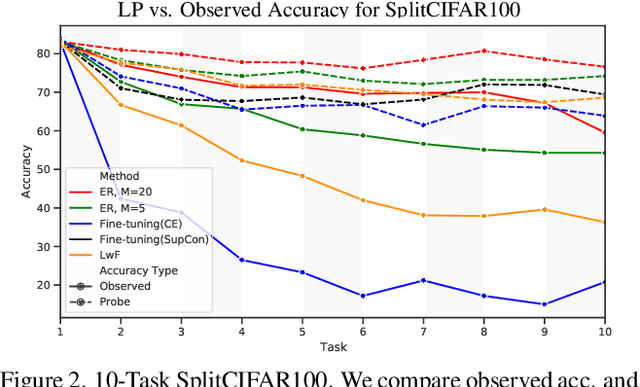
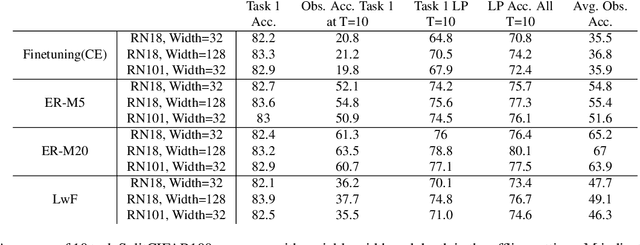
Continual Learning research typically focuses on tackling the phenomenon of catastrophic forgetting in neural networks. Catastrophic forgetting is associated with an abrupt loss of knowledge previously learned by a model when the task, or more broadly the data distribution, being trained on changes. In supervised learning problems this forgetting, resulting from a change in the model's representation, is typically measured or observed by evaluating the decrease in old task performance. However, a model's representation can change without losing knowledge about prior tasks. In this work we consider the concept of representation forgetting, observed by using the difference in performance of an optimal linear classifier before and after a new task is introduced. Using this tool we revisit a number of standard continual learning benchmarks and observe that, through this lens, model representations trained without any explicit control for forgetting often experience small representation forgetting and can sometimes be comparable to methods which explicitly control for forgetting, especially in longer task sequences. We also show that representation forgetting can lead to new insights on the effect of model capacity and loss function used in continual learning. Based on our results, we show that a simple yet competitive approach is to learn representations continually with standard supervised contrastive learning while constructing prototypes of class samples when queried on old samples.
Tackling Online One-Class Incremental Learning by Removing Negative Contrasts
Mar 24, 2022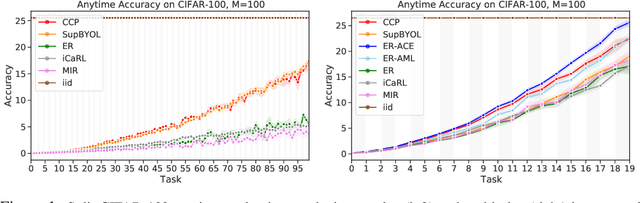


Recent work studies the supervised online continual learning setting where a learner receives a stream of data whose class distribution changes over time. Distinct from other continual learning settings the learner is presented new samples only once and must distinguish between all seen classes. A number of successful methods in this setting focus on storing and replaying a subset of samples alongside incoming data in a computationally efficient manner. One recent proposal ER-AML achieved strong performance in this setting by applying an asymmetric loss based on contrastive learning to the incoming data and replayed data. However, a key ingredient of the proposed method is avoiding contrasts between incoming data and stored data, which makes it impractical for the setting where only one new class is introduced in each phase of the stream. In this work we adapt a recently proposed approach (\textit{BYOL}) from self-supervised learning to the supervised learning setting, unlocking the constraint on contrasts. We then show that supplementing this with additional regularization on class prototypes yields a new method that achieves strong performance in the one-class incremental learning setting and is competitive with the top performing methods in the multi-class incremental setting.
Toward Multimodal Interaction in Scalable Visual Digital Evidence Visualization Using Computer Vision Techniques and ISS
Aug 01, 2018



Visualization requirements in Forensic Lucid have to do with different levels of case knowledge abstraction, representation, aggregation, as well as the operational aspects as the final long-term goal of this proposal. It encompasses anything from the finer detailed representation of hierarchical contexts to Forensic Lucid programs, to the documented evidence and its management, its linkage to programs, to evaluation, and to the management of GIPSY software networks. This includes an ability to arbitrarily switch between those views combined with usable multimodal interaction. The purpose is to determine how the findings can be applied to Forensic Lucid and investigation case management. It is also natural to want a convenient and usable evidence visualization, its semantic linkage and the reasoning machinery for it. Thus, we propose a scalable management, visualization, and evaluation of digital evidence using the modified interactive 3D documentary system - Illimitable Space System - (ISS) to represent, semantically link, and provide a usable interface to digital investigators that is navigable via different multimodal interaction techniques using Computer Vision techniques including gestures, as well as eye-gaze and audio.