 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Knowledge Graphs to Provide Side Information for Improved Recommendation Accuracy
Jan 07, 2021
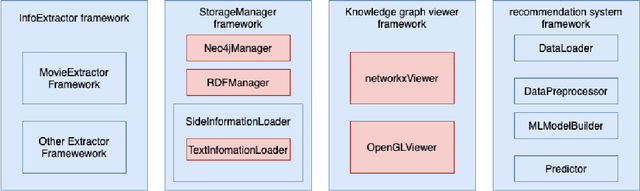

Personalized recommendations are popular in these days of Internet driven activities, specifically shopping. Recommendation methods can be grouped into three major categories, content based filtering, collaborative filtering and machine learning enhanced. Information about products and preferences of different users are primarily used to infer preferences for a specific user. Inadequate information can obviously cause these methods to fail or perform poorly. The more information we provide to these methods, the more likely it is that the methods perform better. Knowledge graphs represent the current trend in recording information in the form of relations between entities, and can provide additional (side) information about products and users. Such information can be used to improve nearest neighbour search, clustering users and products, or train the neural network, when one is used. In this work, we present a new generic recommendation systems framework, that integrates knowledge graphs into the recommendation pipeline. We describe its software design and implementation, and then show through experiments, how such a framework can be specialized for a domain, say movie recommendations, and the improvements in recommendation results possible due to side information obtained from knowledge graphs representation of such information. Our framework supports different knowledge graph representation formats, and facilitates format conversion, merging and information extraction needed for training recommendation methods.
Toward Multimodal Interaction in Scalable Visual Digital Evidence Visualization Using Computer Vision Techniques and ISS
Aug 01, 2018



Visualization requirements in Forensic Lucid have to do with different levels of case knowledge abstraction, representation, aggregation, as well as the operational aspects as the final long-term goal of this proposal. It encompasses anything from the finer detailed representation of hierarchical contexts to Forensic Lucid programs, to the documented evidence and its management, its linkage to programs, to evaluation, and to the management of GIPSY software networks. This includes an ability to arbitrarily switch between those views combined with usable multimodal interaction. The purpose is to determine how the findings can be applied to Forensic Lucid and investigation case management. It is also natural to want a convenient and usable evidence visualization, its semantic linkage and the reasoning machinery for it. Thus, we propose a scalable management, visualization, and evaluation of digital evidence using the modified interactive 3D documentary system - Illimitable Space System - (ISS) to represent, semantically link, and provide a usable interface to digital investigators that is navigable via different multimodal interaction techniques using Computer Vision techniques including gestures, as well as eye-gaze and audio.
Fast Context-Annotated Classification of Different Types of Web Service Descriptions
May 31, 2018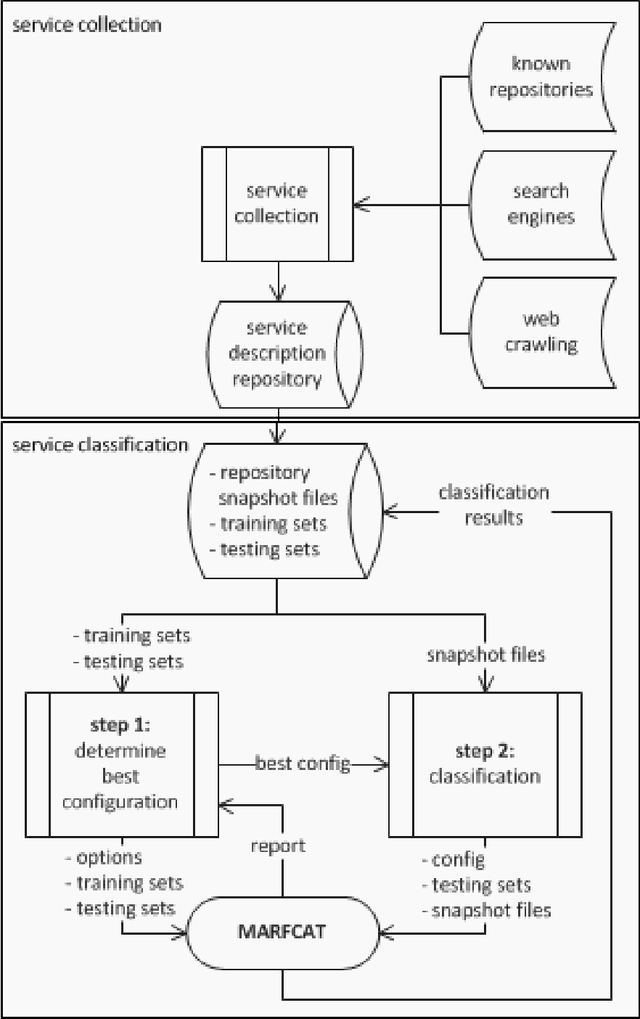

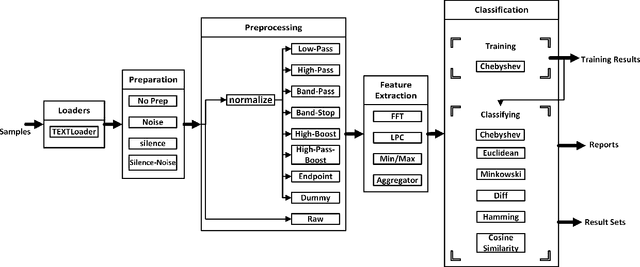

In the recent rapid growth of web services, IoT, and cloud computing, many web services and APIs appeared on the web. With the failure of global UDDI registries, different service repositories started to appear, trying to list and categorize various types of web services for client applications' discover and use. In order to increase the effectiveness and speed up the task of finding compatible Web Services in the brokerage when performing service composition or suggesting Web Services to the requests, high-level functionality of the service needs to be determined. Due to the lack of structured support for specifying such functionality, classification of services into a set of abstract categories is necessary. We employ a wide range of Machine Learning and Signal Processing algorithms and techniques in order to find the highest precision achievable in the scope of this article for the fast classification of three type of service descriptions: WSDL, REST, and WADL. In addition, we complement our approach by showing the importance and effect of contextual information on the classification of the service descriptions and show that it improves the accuracy in 5 different categories of services.
Complete Complementary Results Report of the MARF's NLP Approach to the DEFT 2010 Competition
Apr 19, 2014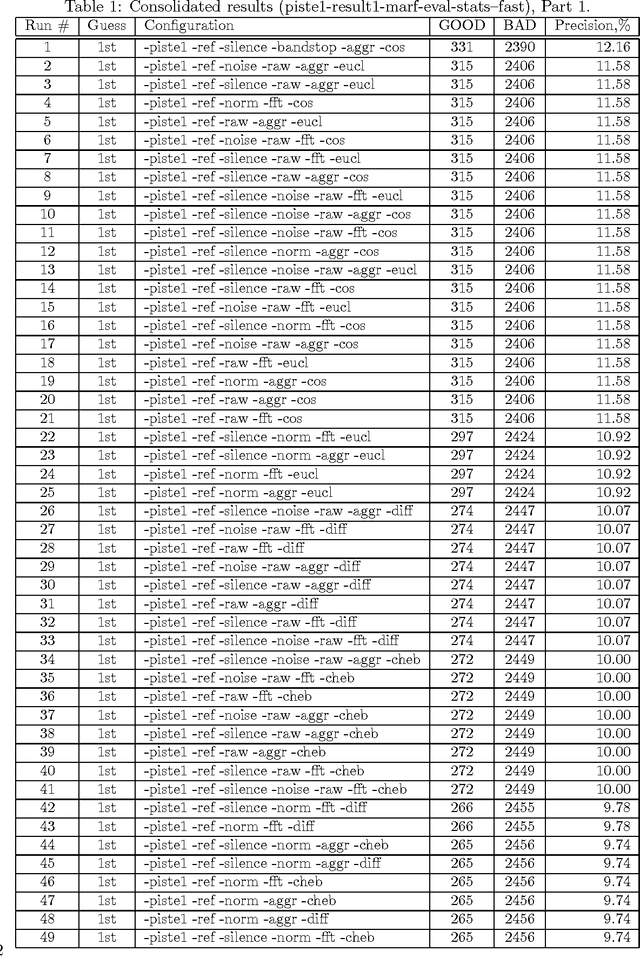
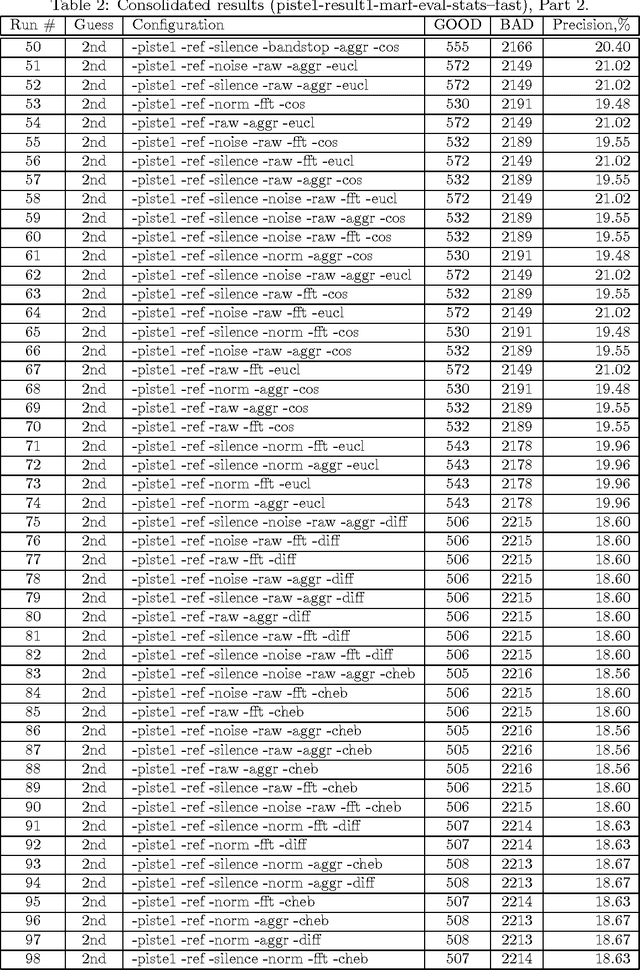
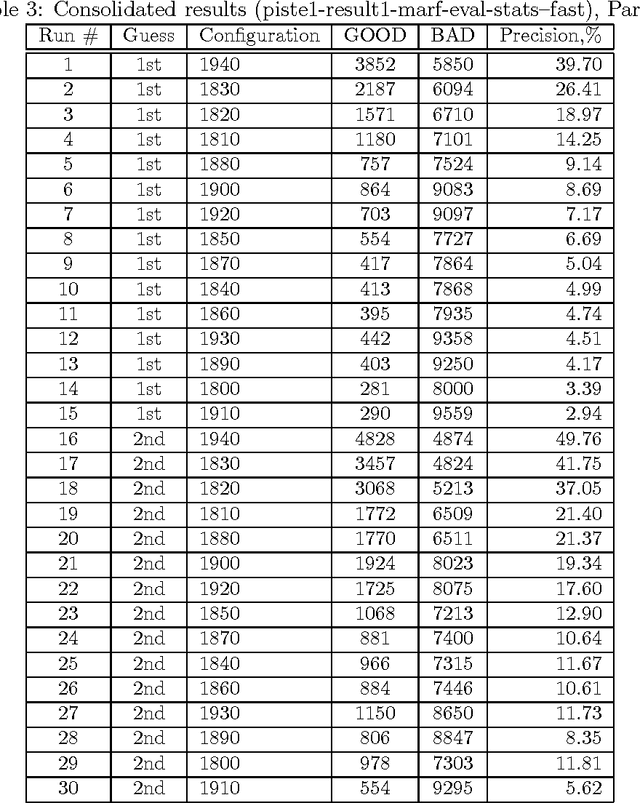
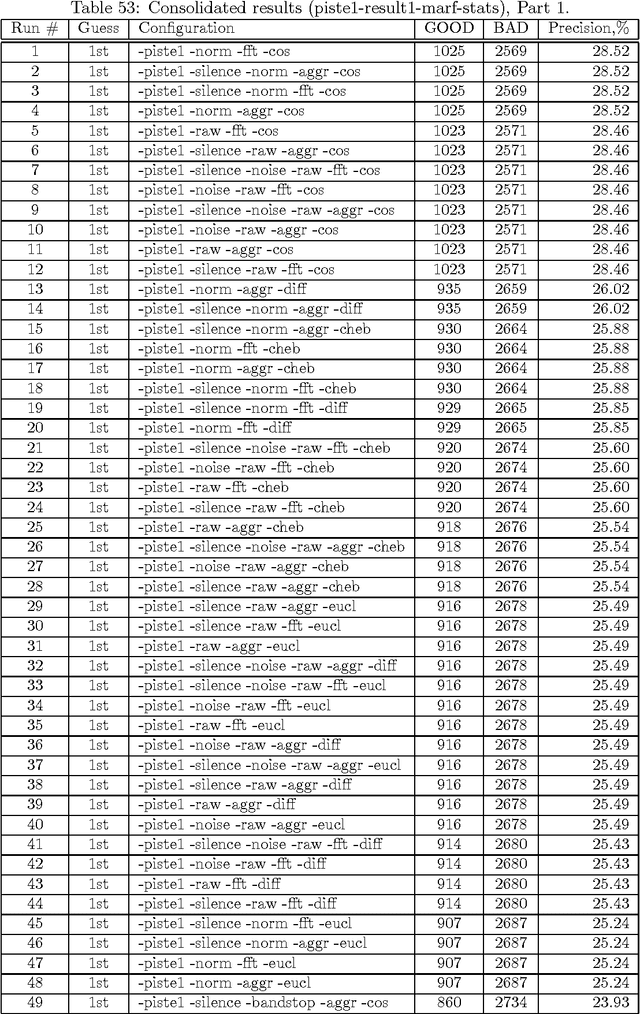
This companion paper complements the main DEFT'10 article describing the MARF approach (arXiv:0905.1235) to the DEFT'10 NLP challenge (described at http://www.groupes.polymtl.ca/taln2010/deft.php in French). This paper is aimed to present the complete result sets of all the conducted experiments and their settings in the resulting tables highlighting the approach and the best results, but also showing the worse and the worst and their subsequent analysis. This particular work focuses on application of the MARF's classical and NLP pipelines to identification tasks within various francophone corpora to identify decades when certain articles were published for the first track (Piste 1) and place of origin of a publication (Piste 2), such as the journal and location (France vs. Quebec). This is the sixth iteration of the release of the results.
MARFCAT: Transitioning to Binary and Larger Data Sets of SATE IV
May 10, 2013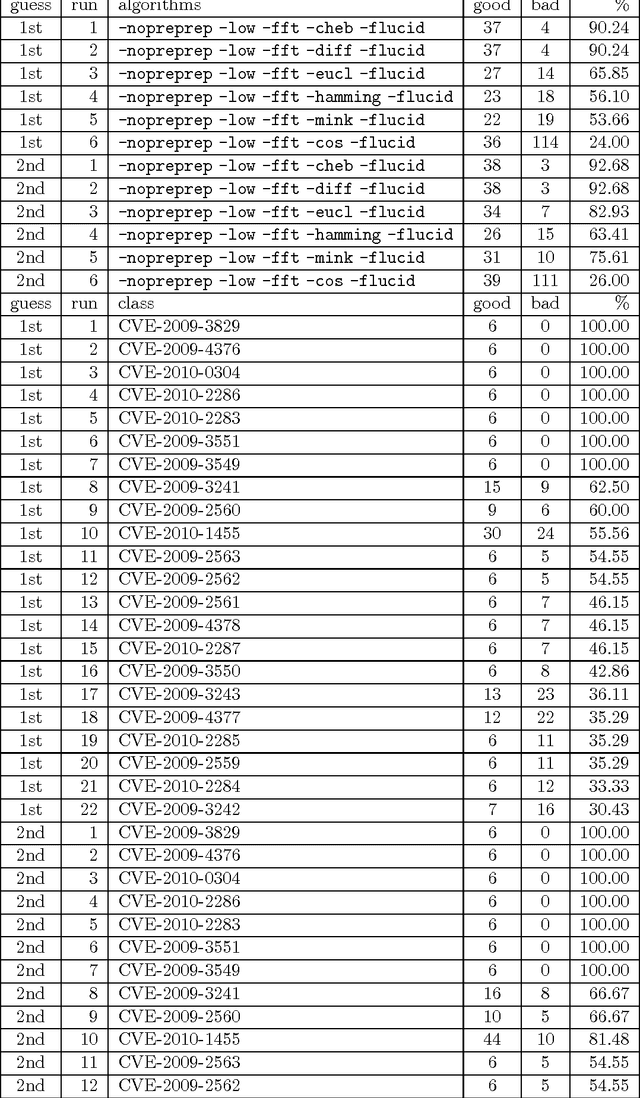
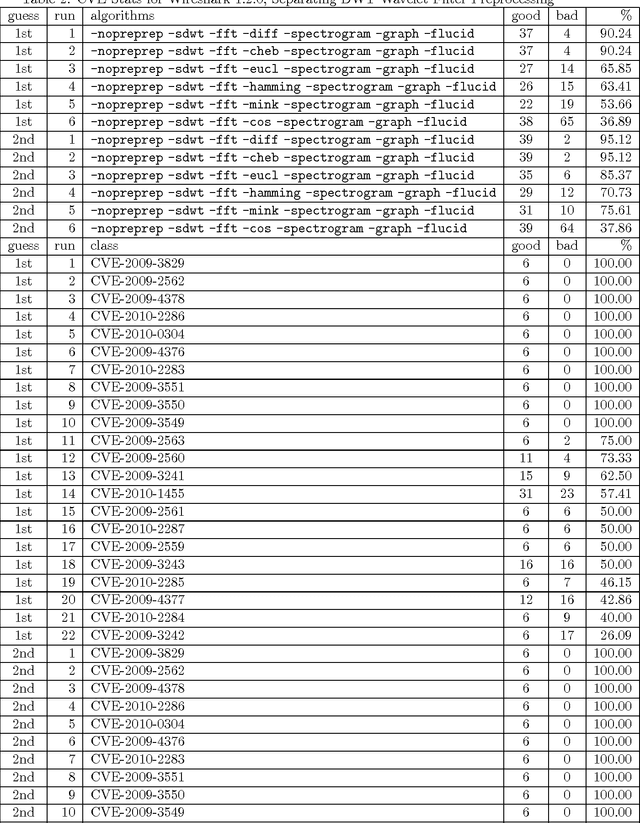
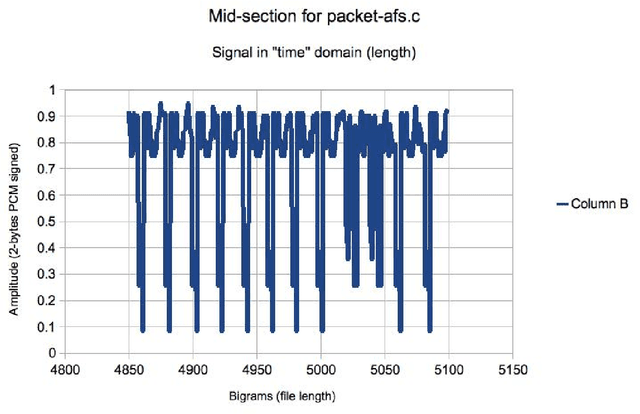

We present a second iteration of a machine learning approach to static code analysis and fingerprinting for weaknesses related to security, software engineering, and others using the open-source MARF framework and the MARFCAT application based on it for the NIST's SATE IV static analysis tool exposition workshop's data sets that include additional test cases, including new large synthetic cases. To aid detection of weak or vulnerable code, including source or binary on different platforms the machine learning approach proved to be fast and accurate to for such tasks where other tools are either much slower or have much smaller recall of known vulnerabilities. We use signal and NLP processing techniques in our approach to accomplish the identification and classification tasks. MARFCAT's design from the beginning in 2010 made is independent of the language being analyzed, source code, bytecode, or binary. In this follow up work with explore some preliminary results in this area. We evaluated also additional algorithms that were used to process the data.
OCT Segmentation Survey and Summary Reviews and a Novel 3D Segmentation Algorithm and a Proof of Concept Implementation
Jun 09, 2012



We overview the existing OCT work, especially the practical aspects of it. We create a novel algorithm for 3D OCT segmentation with the goals of speed and/or accuracy while remaining flexible in the design and implementation for future extensions and improvements. The document at this point is a running draft being iteratively "developed" as a progress report as the work and survey advance. It contains the review and summarization of select OCT works, the design and implementation of the OCTMARF experimentation application and some results.
Developing Autonomic Properties for Distributed Pattern-Recognition Systems with ASSL: A Distributed MARF Case Study
Dec 16, 2011

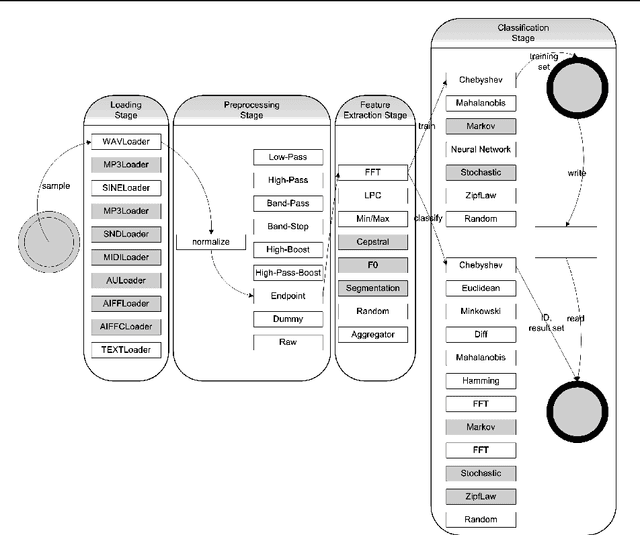

In this paper, we discuss our research towards developing special properties that introduce autonomic behavior in pattern-recognition systems. In our approach we use ASSL (Autonomic System Specification Language) to formally develop such properties for DMARF (Distributed Modular Audio Recognition Framework). These properties enhance DMARF with an autonomic middleware that manages the four stages of the framework's pattern-recognition pipeline. DMARF is a biologically inspired system employing pattern recognition, signal processing, and natural language processing helping us process audio, textual, or imagery data needed by a variety of scientific applications, e.g., biometric applications. In that context, the notion go autonomic DMARF (ADMARF) can be employed by autonomous and robotic systems that theoretically require less-to-none human intervention other than data collection for pattern analysis and observing the results. In this article, we explain the ASSL specification models for the autonomic properties of DMARF.
* 28 pages; 16 figures; Submitted and accepted in 2010; to appear in "E. Vassev and S. A. Mokhov. Development and evaluation of autonomic properties for pattern-recognition systems with ASSL -- a distributed MARF case study. Transactions on Computational Science, Special Issue on Advances in Autonomic Computing: Formal Engineering Methods for Nature-Inspired Computing Systems, XV (LNCS7050)."
Towards a Heuristic Categorization of Prepositional Phrases in English with WordNet
Feb 04, 2010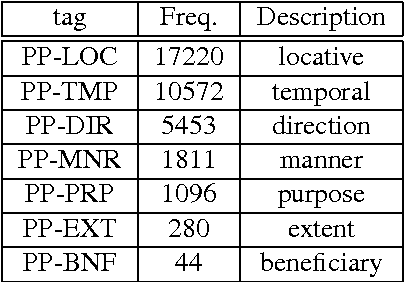


This document discusses an approach and its rudimentary realization towards automatic classification of PPs; the topic, that has not received as much attention in NLP as NPs and VPs. The approach is a rule-based heuristics outlined in several levels of our research. There are 7 semantic categories of PPs considered in this document that we are able to classify from an annotated corpus.
On Event Structure in the Torn Dress
Feb 04, 2010Using Pustejovsky's "The Syntax of Event Structure" and Fong's "On Mending a Torn Dress" we give a glimpse of a Pustejovsky-like analysis to some example sentences in Fong. We attempt to give a framework for semantics to the noun phrases and adverbs as appropriate as well as the lexical entries for all words in the examples and critique both papers in light of our findings and difficulties.
Writer Identification Using Inexpensive Signal Processing Techniques
Dec 30, 2009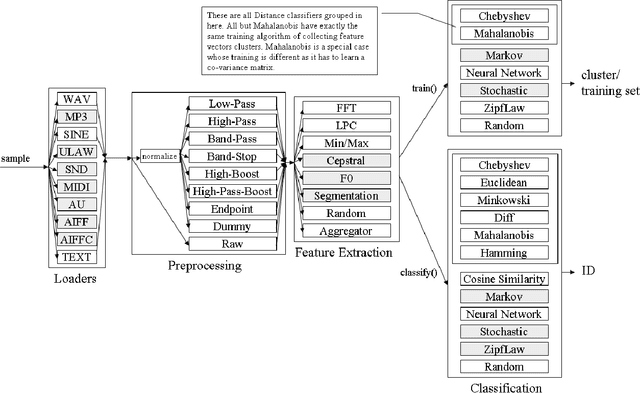
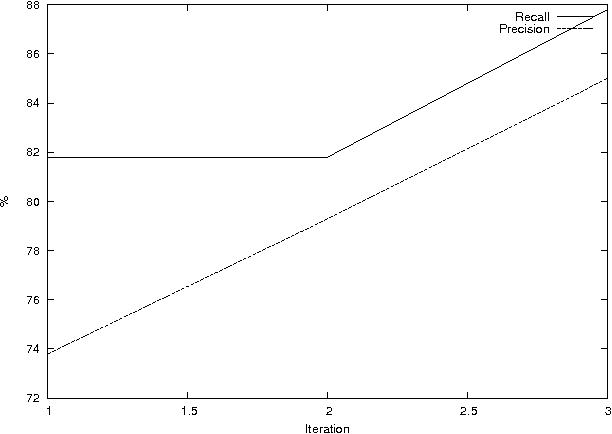
We propose to use novel and classical audio and text signal-processing and otherwise techniques for "inexpensive" fast writer identification tasks of scanned hand-written documents "visually". The "inexpensive" refers to the efficiency of the identification process in terms of CPU cycles while preserving decent accuracy for preliminary identification. This is a comparative study of multiple algorithm combinations in a pattern recognition pipeline implemented in Java around an open-source Modular Audio Recognition Framework (MARF) that can do a lot more beyond audio. We present our preliminary experimental findings in such an identification task. We simulate "visual" identification by "looking" at the hand-written document as a whole rather than trying to extract fine-grained features out of it prior classification.