 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLTA: Enhancing Vision-Language Pre-training through Textual Augmentation
Aug 31, 2023



Vision-language pre-training (VLP) methods are blossoming recently, and its crucial goal is to jointly learn visual and textual features via a transformer-based architecture, demonstrating promising improvements on a variety of vision-language tasks. Prior arts usually focus on how to align visual and textual features, but strategies for improving the robustness of model and speeding up model convergence are left insufficiently explored. In this paper, we propose a novel method ViLTA, comprising of two components to further facilitate the model to learn fine-grained representations among image-text pairs. For Masked Language Modeling (MLM), we propose a cross-distillation method to generate soft labels to enhance the robustness of model, which alleviates the problem of treating synonyms of masked words as negative samples in one-hot labels. For Image-Text Matching (ITM), we leverage the current language encoder to synthesize hard negatives based on the context of language input, encouraging the model to learn high-quality representations by increasing the difficulty of the ITM task. By leveraging the above techniques, our ViLTA can achieve better performance on various vision-language tasks. Extensive experiments on benchmark datasets demonstrate that the effectiveness of ViLTA and its promising potential for vision-language pre-training.
3D Automatic Segmentation Method for Retinal Optical Coherence Tomography Volume Data Using Boundary Surface Enhancement
Aug 05, 2015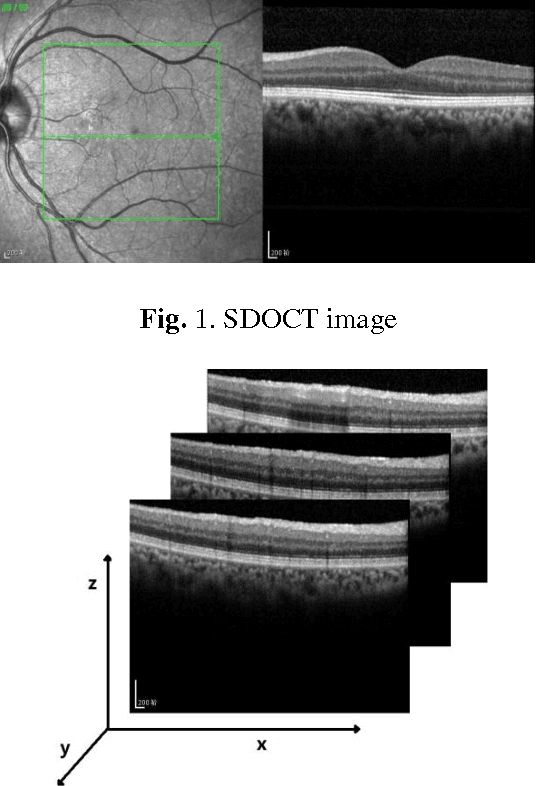
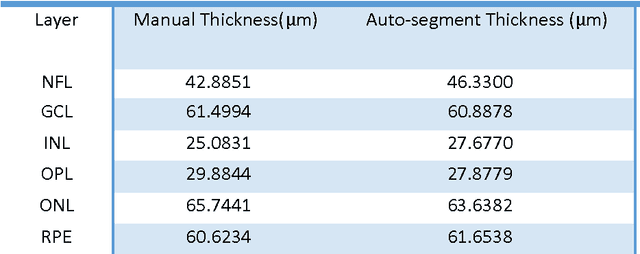
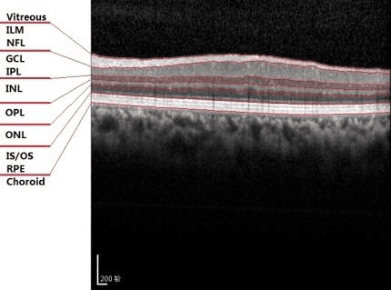
With the introduction of spectral-domain optical coherence tomography (SDOCT), much larger image datasets are routinely acquired compared to what was possible using the previous generation of time-domain OCT. Thus, there is a critical need for the development of 3D segmentation methods for processing these data. We present here a novel 3D automatic segmentation method for retinal OCT volume data. Briefly, to segment a boundary surface, two OCT volume datasets are obtained by using a 3D smoothing filter and a 3D differential filter. Their linear combination is then calculated to generate new volume data with an enhanced boundary surface, where pixel intensity, boundary position information, and intensity changes on both sides of the boundary surface are used simultaneously. Next, preliminary discrete boundary points are detected from the A-Scans of the volume data. Finally, surface smoothness constraints and a dynamic threshold are applied to obtain a smoothed boundary surface by correcting a small number of error points. Our method can extract retinal layer boundary surfaces sequentially with a decreasing search region of volume data. We performed automatic segmentation on eight human OCT volume datasets acquired from a commercial Spectralis OCT system, where each volume of data consisted of 97 OCT images with a resolution of 496 512; experimental results show that this method can accurately segment seven layer boundary surfaces in normal as well as some abnormal eyes.
MARFCAT: Transitioning to Binary and Larger Data Sets of SATE IV
May 10, 2013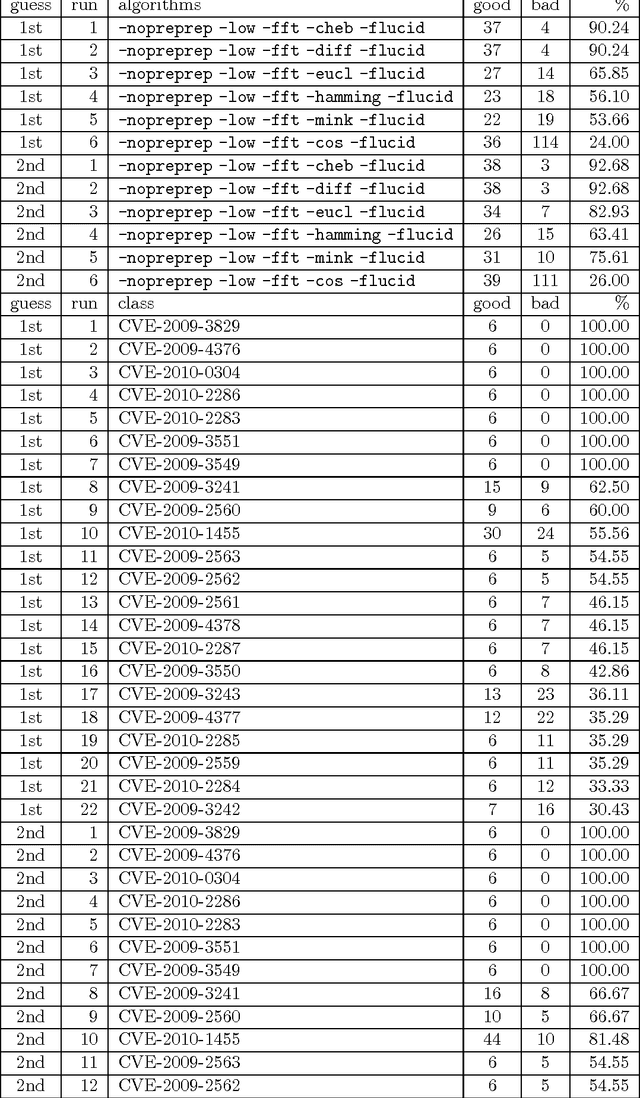
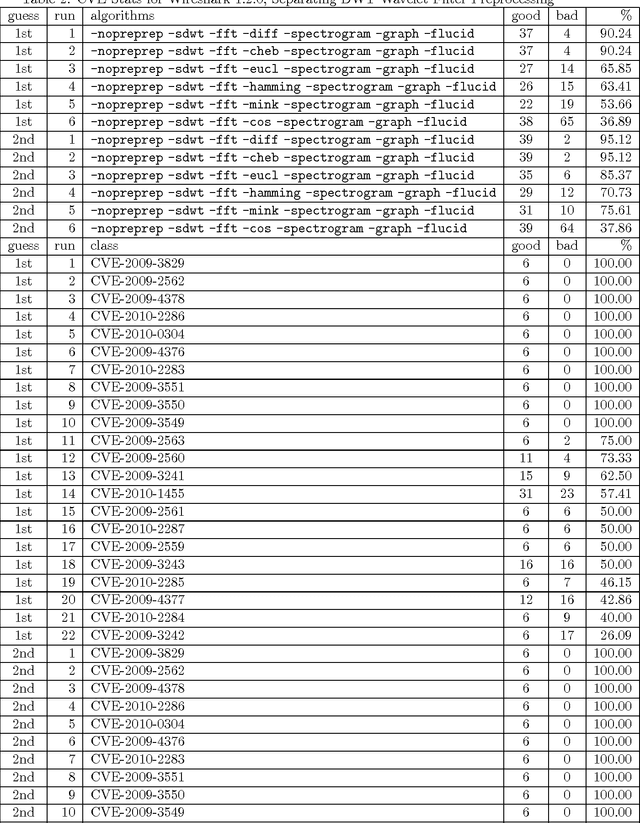

We present a second iteration of a machine learning approach to static code analysis and fingerprinting for weaknesses related to security, software engineering, and others using the open-source MARF framework and the MARFCAT application based on it for the NIST's SATE IV static analysis tool exposition workshop's data sets that include additional test cases, including new large synthetic cases. To aid detection of weak or vulnerable code, including source or binary on different platforms the machine learning approach proved to be fast and accurate to for such tasks where other tools are either much slower or have much smaller recall of known vulnerabilities. We use signal and NLP processing techniques in our approach to accomplish the identification and classification tasks. MARFCAT's design from the beginning in 2010 made is independent of the language being analyzed, source code, bytecode, or binary. In this follow up work with explore some preliminary results in this area. We evaluated also additional algorithms that were used to process the data.
OCT Segmentation Survey and Summary Reviews and a Novel 3D Segmentation Algorithm and a Proof of Concept Implementation
Jun 09, 2012



We overview the existing OCT work, especially the practical aspects of it. We create a novel algorithm for 3D OCT segmentation with the goals of speed and/or accuracy while remaining flexible in the design and implementation for future extensions and improvements. The document at this point is a running draft being iteratively "developed" as a progress report as the work and survey advance. It contains the review and summarization of select OCT works, the design and implementation of the OCTMARF experimentation application and some results.
A 3D Segmentation Method for Retinal Optical Coherence Tomography Volume Data
Apr 28, 2012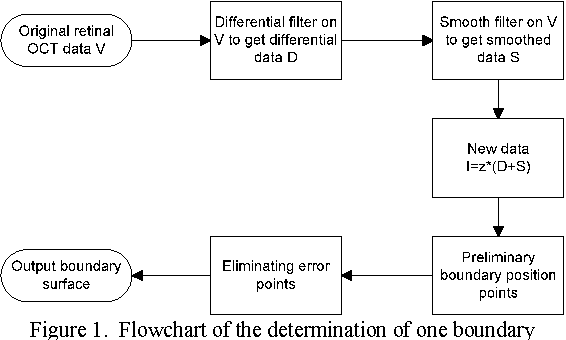
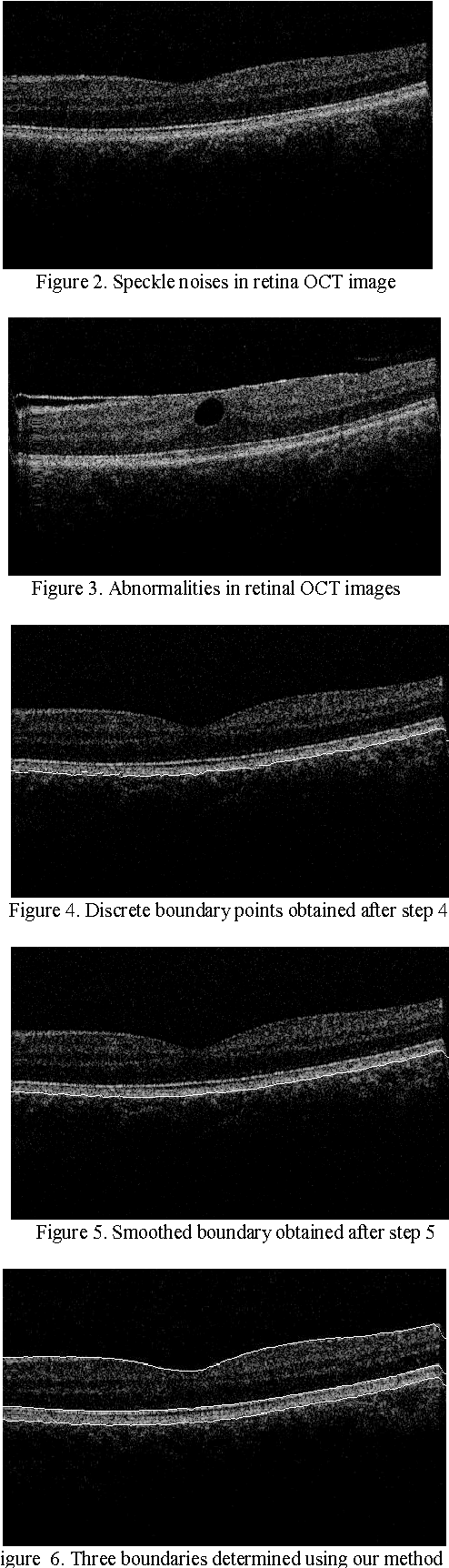
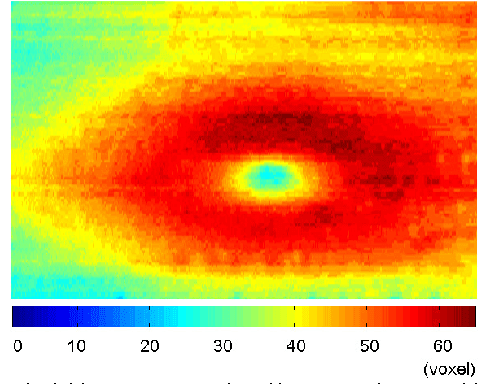
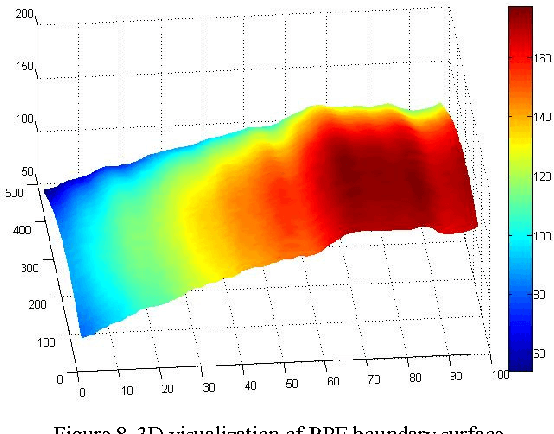
With the introduction of spectral-domain optical coherence tomography (OCT), much larger image datasets are routinely acquired compared to what was possible using the previous generation of time-domain OCT. Thus, the need for 3-D segmentation methods for processing such data is becoming increasingly important. We present a new 3D segmentation method for retinal OCT volume data, which generates an enhanced volume data by using pixel intensity, boundary position information, intensity changes on both sides of the border simultaneously, and preliminary discrete boundary points are found from all A-Scans and then the smoothed boundary surface can be obtained after removing a small quantity of error points. Our experiments show that this method is efficient, accurate and robust.
* 4 pages, 9 figures