 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget by Uncertainty: Orthogonal Entropy Unlearning for Quantized Neural Networks
Jan 31, 2026The deployment of quantized neural networks on edge devices, combined with privacy regulations like GDPR, creates an urgent need for machine unlearning in quantized models. However, existing methods face critical challenges: they induce forgetting by training models to memorize incorrect labels, conflating forgetting with misremembering, and employ scalar gradient reweighting that cannot resolve directional conflicts between gradients. We propose OEU, a novel Orthogonal Entropy Unlearning framework with two key innovations: 1) Entropy-guided unlearning maximizes prediction uncertainty on forgotten data, achieving genuine forgetting rather than confident misprediction, and 2) Gradient orthogonal projection eliminates interference by projecting forgetting gradients onto the orthogonal complement of retain gradients, providing theoretical guarantees for utility preservation under first-order approximation. Extensive experiments demonstrate that OEU outperforms existing methods in both forgetting effectiveness and retain accuracy.
SAGE: Accelerating Vision-Language Models via Entropy-Guided Adaptive Speculative Decoding
Jan 31, 2026Speculative decoding has emerged as a promising approach to accelerate inference in vision-language models (VLMs) by enabling parallel verification of multiple draft tokens. However, existing methods rely on static tree structures that remain fixed throughout the decoding process, failing to adapt to the varying prediction difficulty across generation steps. This leads to suboptimal acceptance lengths and limited speedup. In this paper, we propose SAGE, a novel framework that dynamically adjusts the speculation tree structure based on real-time prediction uncertainty. Our key insight is that output entropy serves as a natural confidence indicator with strong temporal correlation across decoding steps. SAGE constructs deeper-narrower trees for high-confidence predictions to maximize speculation depth, and shallower-wider trees for uncertain predictions to diversify exploration. SAGE improves acceptance lengths and achieves faster acceleration compared to static tree baselines. Experiments on multiple benchmarks demonstrate the effectiveness of SAGE: without any loss in output quality, it delivers up to $3.36\times$ decoding speedup for LLaVA-OneVision-72B and $3.18\times$ for Qwen2.5-VL-72B.
AscendCraft: Automatic Ascend NPU Kernel Generation via DSL-Guided Transcompilation
Jan 30, 2026The performance of deep learning models critically depends on efficient kernel implementations, yet developing high-performance kernels for specialized accelerators remains time-consuming and expertise-intensive. While recent work demonstrates that large language models (LLMs) can generate correct and performant GPU kernels, kernel generation for neural processing units (NPUs) remains largely underexplored due to domain-specific programming models, limited public examples, and sparse documentation. Consequently, directly generating AscendC kernels with LLMs yields extremely low correctness, highlighting a substantial gap between GPU and NPU kernel generation. We present AscendCraft, a DSL-guided approach for automatic AscendC kernel generation. AscendCraft introduces a lightweight DSL that abstracts non-essential complexity while explicitly modeling Ascend-specific execution semantics. Kernels are first generated in the DSL using category-specific expert examples and then transcompiled into AscendC through structured, constraint-driven LLM lowering passes. Evaluated on MultiKernelBench across seven operator categories, AscendCraft achieves 98.1% compilation success and 90.4% functional correctness. Moreover, 46.2% of generated kernels match or exceed PyTorch eager execution performance, demonstrating that DSL-guided transcompilation can enable LLMs to generate both correct and competitive NPU kernels. Beyond benchmarks, AscendCraft further demonstrates its generality by successfully generating two correct kernels for newly proposed mHC architecture, achieving performance that substantially surpasses PyTorch eager execution.
Bits for Privacy: Evaluating Post-Training Quantization via Membership Inference
Dec 17, 2025Deep neural networks are widely deployed with quantization techniques to reduce memory and computational costs by lowering the numerical precision of their parameters. While quantization alters model parameters and their outputs, existing privacy analyses primarily focus on full-precision models, leaving a gap in understanding how bit-width reduction can affect privacy leakage. We present the first systematic study of the privacy-utility relationship in post-training quantization (PTQ), a versatile family of methods that can be applied to pretrained models without further training. Using membership inference attacks as our evaluation framework, we analyze three popular PTQ algorithms-AdaRound, BRECQ, and OBC-across multiple precision levels (4-bit, 2-bit, and 1.58-bit) on CIFAR-10, CIFAR-100, and TinyImageNet datasets. Our findings consistently show that low-precision PTQs can reduce privacy leakage. In particular, lower-precision models demonstrate up to an order of magnitude reduction in membership inference vulnerability compared to their full-precision counterparts, albeit at the cost of decreased utility. Additional ablation studies on the 1.58-bit quantization level show that quantizing only the last layer at higher precision enables fine-grained control over the privacy-utility trade-off. These results offer actionable insights for practitioners to balance efficiency, utility, and privacy protection in real-world deployments.
RLMR: Reinforcement Learning with Mixed Rewards for Creative Writing
Aug 28, 2025
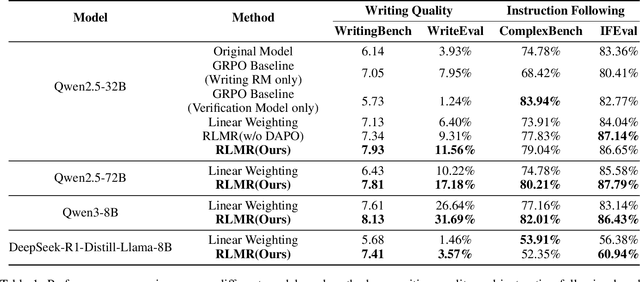
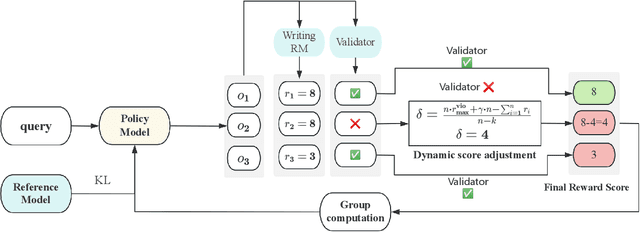
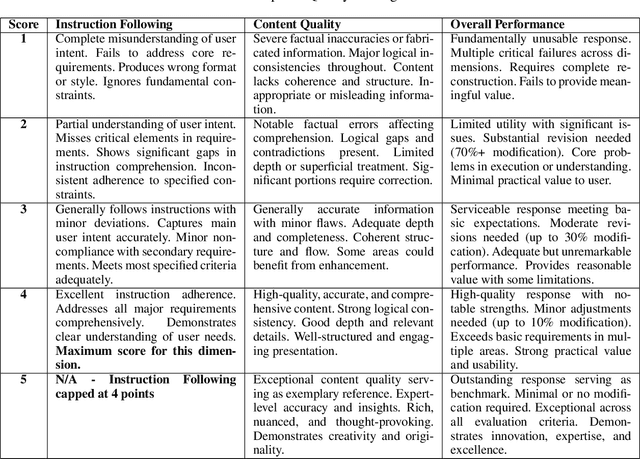
Large language models are extensively utilized in creative writing applications. Creative writing requires a balance between subjective writing quality (e.g., literariness and emotional expression) and objective constraint following (e.g., format requirements and word limits). Existing methods find it difficult to balance these two aspects: single reward strategies fail to improve both abilities simultaneously, while fixed-weight mixed-reward methods lack the ability to adapt to different writing scenarios. To address this problem, we propose Reinforcement Learning with Mixed Rewards (RLMR), utilizing a dynamically mixed reward system from a writing reward model evaluating subjective writing quality and a constraint verification model assessing objective constraint following. The constraint following reward weight is adjusted dynamically according to the writing quality within sampled groups, ensuring that samples violating constraints get negative advantage in GRPO and thus penalized during training, which is the key innovation of this proposed method. We conduct automated and manual evaluations across diverse model families from 8B to 72B parameters. Additionally, we construct a real-world writing benchmark named WriteEval for comprehensive evaluation. Results illustrate that our method achieves consistent improvements in both instruction following (IFEval from 83.36% to 86.65%) and writing quality (72.75% win rate in manual expert pairwise evaluations on WriteEval). To the best of our knowledge, RLMR is the first work to combine subjective preferences with objective verification in online RL training, providing an effective solution for multi-dimensional creative writing optimization.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Efficient training for large-scale optical neural network using an evolutionary strategy and attention pruning
May 19, 2025MZI-based block optical neural networks (BONNs), which can achieve large-scale network models, have increasingly drawn attentions. However, the robustness of the current training algorithm is not high enough. Moreover, large-scale BONNs usually contain numerous trainable parameters, resulting in expensive computation and power consumption. In this article, by pruning matrix blocks and directly optimizing the individuals in population, we propose an on-chip covariance matrix adaptation evolution strategy and attention-based pruning (CAP) algorithm for large-scale BONNs. The calculated results demonstrate that the CAP algorithm can prune 60% and 80% of the parameters for MNIST and Fashion-MNIST datasets, respectively, while only degrades the performance by 3.289% and 4.693%. Considering the influence of dynamic noise in phase shifters, our proposed CAP algorithm (performance degradation of 22.327% for MNIST dataset and 24.019% for Fashion-MNIST dataset utilizing a poor fabricated chip and electrical control with a standard deviation of 0.5) exhibits strongest robustness compared with both our previously reported block adjoint training algorithm (43.963% and 41.074%) and the covariance matrix adaptation evolution strategy (25.757% and 32.871%), respectively. Moreover, when 60% of the parameters are pruned, the CAP algorithm realizes 88.5% accuracy in experiment for the simplified MNIST dataset, which is similar to the simulation result without noise (92.1%). Additionally, we simulationally and experimentally demonstrate that using MZIs with only internal phase shifters to construct BONNs is an efficient way to reduce both the system area and the required trainable parameters. Notably, our proposed CAP algorithm show excellent potential for larger-scale network models and more complex tasks.
Knowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
May 11, 2025
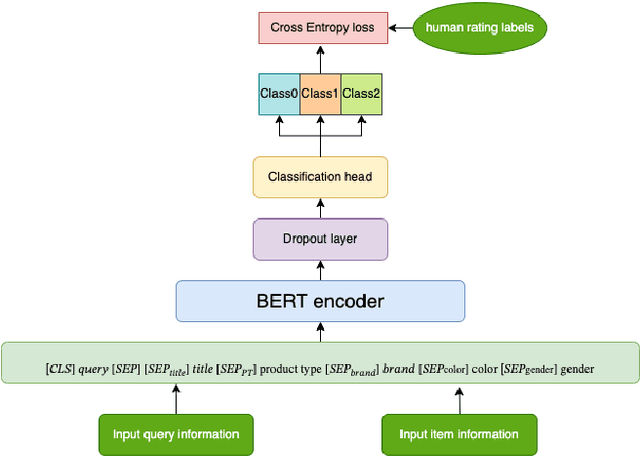
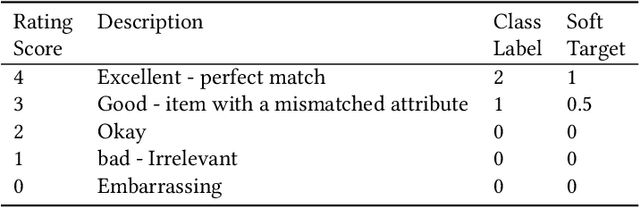
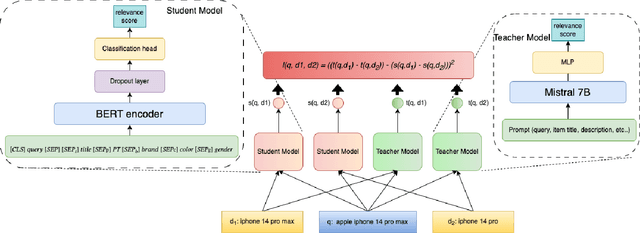
Ensuring the products displayed in e-commerce search results are relevant to users queries is crucial for improving the user experience. With their advanced semantic understanding, deep learning models have been widely used for relevance matching in search tasks. While large language models (LLMs) offer superior ranking capabilities, it is challenging to deploy LLMs in real-time systems due to the high-latency requirements. To leverage the ranking power of LLMs while meeting the low-latency demands of production systems, we propose a novel framework that distills a high performing LLM into a more efficient, low-latency student model. To help the student model learn more effectively from the teacher model, we first train the teacher LLM as a classification model with soft targets. Then, we train the student model to capture the relevance margin between pairs of products for a given query using mean squared error loss. Instead of using the same training data as the teacher model, we significantly expand the student model dataset by generating unlabeled data and labeling it with the teacher model predictions. Experimental results show that the student model performance continues to improve as the size of the augmented training data increases. In fact, with enough augmented data, the student model can outperform the teacher model. The student model has been successfully deployed in production at Walmart.com with significantly positive metrics.
* 9 pages, published at WWWW'25
Global-Local Medical SAM Adaptor Based on Full Adaption
Sep 26, 2024

Emerging of visual language models, such as the segment anything model (SAM), have made great breakthroughs in the field of universal semantic segmentation and significantly aid the improvements of medical image segmentation, in particular with the help of Medical SAM adaptor (Med-SA). However, Med-SA still can be improved, as it fine-tunes SAM in a partial adaption manner. To resolve this problem, we present a novel global medical SAM adaptor (GMed-SA) with full adaption, which can adapt SAM globally. We further combine GMed-SA and Med-SA to propose a global-local medical SAM adaptor (GLMed-SA) to adapt SAM both globally and locally. Extensive experiments have been performed on the challenging public 2D melanoma segmentation dataset. The results show that GLMed-SA outperforms several state-of-the-art semantic segmentation methods on various evaluation metrics, demonstrating the superiority of our methods.
Prompt-Softbox-Prompt: A free-text Embedding Control for Image Editing
Aug 27, 2024Text-driven diffusion models have achieved remarkable success in image editing, but a crucial component in these models-text embeddings-has not been fully explored. The entanglement and opacity of text embeddings present significant challenges to achieving precise image editing. In this paper, we provide a comprehensive and in-depth analysis of text embeddings in Stable Diffusion XL, offering three key insights. First, while the 'aug_embedding' captures the full semantic content of the text, its contribution to the final image generation is relatively minor. Second, 'BOS' and 'Padding_embedding' do not contain any semantic information. Lastly, the 'EOS' holds the semantic information of all words and contains the most style features. Each word embedding plays a unique role without interfering with one another. Based on these insights, we propose a novel approach for controllable image editing using a free-text embedding control method called PSP (Prompt-Softbox-Prompt). PSP enables precise image editing by inserting or adding text embeddings within the cross-attention layers and using Softbox to define and control the specific area for semantic injection. This technique allows for obejct additions and replacements while preserving other areas of the image. Additionally, PSP can achieve style transfer by simply replacing text embeddings. Extensive experimental results show that PSP achieves significant results in tasks such as object replacement, object addition, and style transfer.