 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuMural: Restoring Dunhuang Murals with Multi-scale Diffusion
Apr 13, 2025Large-scale pre-trained diffusion models have produced excellent results in the field of conditional image generation. However, restoration of ancient murals, as an important downstream task in this field, poses significant challenges to diffusion model-based restoration methods due to its large defective area and scarce training samples. Conditional restoration tasks are more concerned with whether the restored part meets the aesthetic standards of mural restoration in terms of overall style and seam detail, and such metrics for evaluating heuristic image complements are lacking in current research. We therefore propose DiffuMural, a combined Multi-scale convergence and Collaborative Diffusion mechanism with ControlNet and cyclic consistency loss to optimise the matching between the generated images and the conditional control. DiffuMural demonstrates outstanding capabilities in mural restoration, leveraging training data from 23 large-scale Dunhuang murals that exhibit consistent visual aesthetics. The model excels in restoring intricate details, achieving a coherent overall appearance, and addressing the unique challenges posed by incomplete murals lacking factual grounding. Our evaluation framework incorporates four key metrics to quantitatively assess incomplete murals: factual accuracy, textural detail, contextual semantics, and holistic visual coherence. Furthermore, we integrate humanistic value assessments to ensure the restored murals retain their cultural and artistic significance. Extensive experiments validate that our method outperforms state-of-the-art (SOTA) approaches in both qualitative and quantitative metrics.
TransformDAS: Mapping Φ-OTDR Signals to Riemannian Manifold for Robust Classification
Feb 04, 2025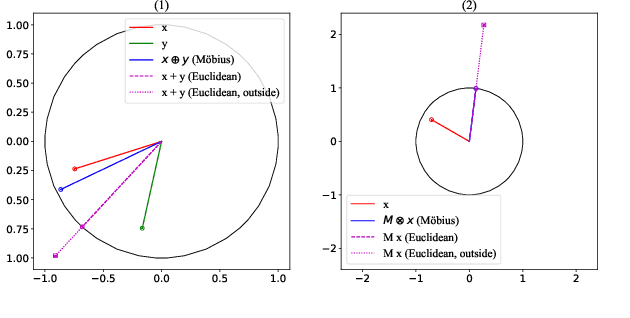
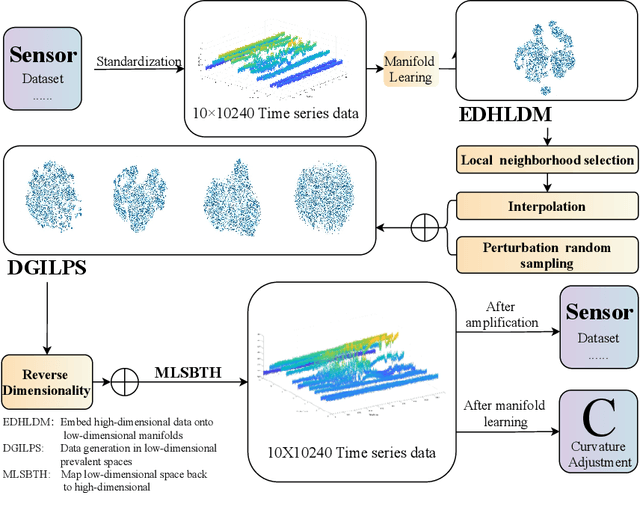
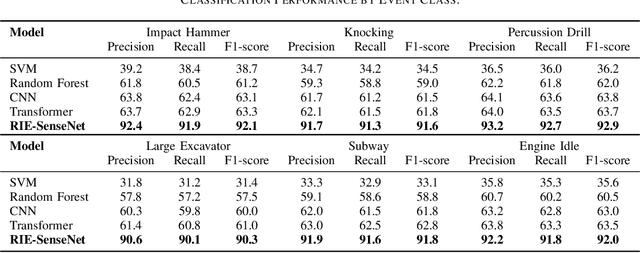
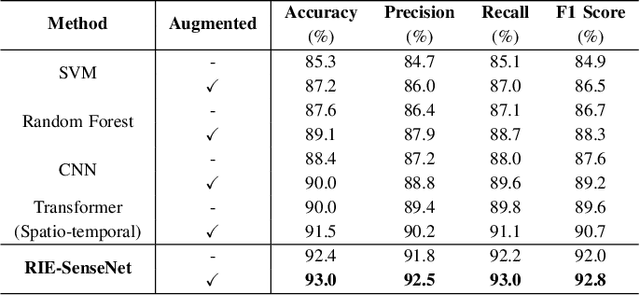
Phase-sensitive optical time-domain reflectometry ({\Phi}-OTDR) is a widely used distributed fiber optic sensing system in engineering. Machine learning algorithms for {\Phi}-OTDR event classification require high volumes and quality of datasets; however, high-quality datasets are currently extremely scarce in the field, leading to a lack of robustness in models, which is manifested by higher false alarm rates in real-world scenarios. One promising approach to address this issue is to augment existing data using generative models combined with a small amount of real-world data. We explored mapping both {\Phi}-OTDR features in a GAN-based generative pipeline and signal features in a Transformer classifier to hyperbolic space to seek more effective model generalization. The results indicate that state-of-the-art models exhibit stronger generalization performance and lower false alarm rates in real-world scenarios when trained on augmented datasets. TransformDAS, in particular, demonstrates the best classification performance, highlighting the benefits of Riemannian manifold mapping in {\Phi}-OTDR data generation and model classification.
Spectral Enhancement and Pseudo-Anchor Guidance for Infrared-Visible Person Re-Identification
Dec 26, 2024



The development of deep learning has facilitated the application of person re-identification (ReID) technology in intelligent security. Visible-infrared person re-identification (VI-ReID) aims to match pedestrians across infrared and visible modality images enabling 24-hour surveillance. Current studies relying on unsupervised modality transformations as well as inefficient embedding constraints to bridge the spectral differences between infrared and visible images, however, limit their potential performance. To tackle the limitations of the above approaches, this paper introduces a simple yet effective Spectral Enhancement and Pseudo-anchor Guidance Network, named SEPG-Net. Specifically, we propose a more homogeneous spectral enhancement scheme based on frequency domain information and greyscale space, which avoids the information loss typically caused by inefficient modality transformations. Further, a Pseudo Anchor-guided Bidirectional Aggregation (PABA) loss is introduced to bridge local modality discrepancies while better preserving discriminative identity embeddings. Experimental results on two public benchmark datasets demonstrate the superior performance of SEPG-Net against other state-of-the-art methods. The code is available at https://github.com/1024AILab/ReID-SEPG.
DAPONet: A Dual Attention and Partially Overparameterized Network for Real-Time Road Damage Detection
Sep 03, 2024Current road damage detection methods, relying on manual inspections or sensor-mounted vehicles, are inefficient, limited in coverage, and often inaccurate, especially for minor damages, leading to delays and safety hazards. To address these issues and enhance real-time road damage detection using street view image data (SVRDD), we propose DAPONet, a model incorporating three key modules: a dual attention mechanism combining global and local attention, a multi-scale partial over-parameterization module, and an efficient downsampling module. DAPONet achieves a mAP50 of 70.1% on the SVRDD dataset, outperforming YOLOv10n by 10.4%, while reducing parameters to 1.6M and FLOPs to 1.7G, representing reductions of 41% and 80%, respectively. On the MS COCO2017 val dataset, DAPONet achieves an mAP50-95 of 33.4%, 0.8% higher than EfficientDet-D1, with a 74% reduction in both parameters and FLOPs.
ECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
Aug 16, 2024
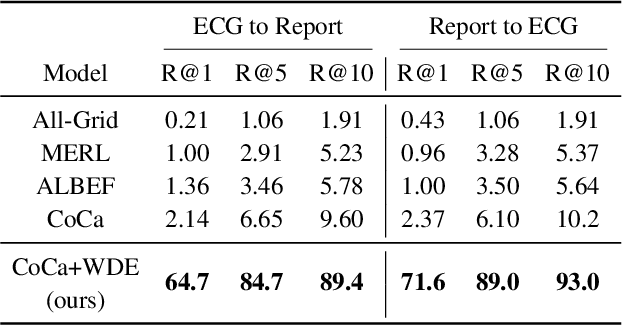
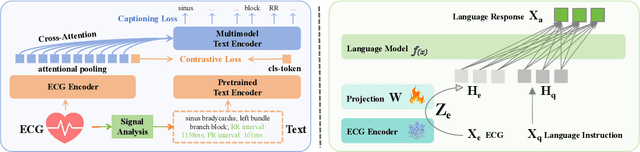
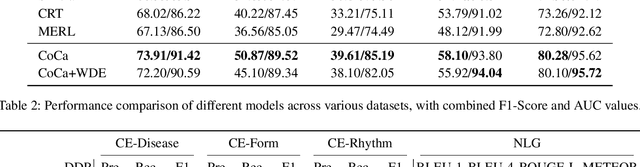
The success of Multimodal Large Language Models (MLLMs) in the medical auxiliary field shows great potential, allowing patients to engage in conversations using physiological signal data. However, general MLLMs perform poorly in cardiac disease diagnosis, particularly in the integration of ECG data analysis and long-text medical report generation, mainly due to the complexity of ECG data analysis and the gap between text and ECG signal modalities. Additionally, models often exhibit severe stability deficiencies in long-text generation due to the lack of precise knowledge strongly related to user queries. To address these issues, we propose ECG-Chat, the first multitask MLLMs focused on ECG medical report generation, providing multimodal conversational capabilities based on cardiology knowledge. We propose a contrastive learning approach that integrates ECG waveform data with text reports, aligning ECG features with reports in a fine-grained manner. This method also results in an ECG encoder that excels in zero-shot report retrieval tasks. Additionally, expanding existing datasets, we constructed a 19k ECG diagnosis dataset and a 25k multi-turn dialogue dataset for training and fine-tuning ECG-Chat, which provides professional diagnostic and conversational capabilities. Furthermore, ECG-Chat can generate comprehensive ECG analysis reports through an automated LaTeX generation pipeline. We established a benchmark for the ECG report generation task and tested our model on multiple baselines. ECG-Chat achieved the best performance in classification, retrieval, multimodal dialogue, and medical report generation tasks. Our report template design has also been widely recognized by medical practitioners.
LuoJiaHOG: A Hierarchy Oriented Geo-aware Image Caption Dataset for Remote Sensing Image-Text Retrival
Mar 16, 2024Image-text retrieval (ITR) plays a significant role in making informed decisions for various remote sensing (RS) applications. Nonetheless, creating ITR datasets containing vision and language modalities not only requires significant geo-spatial sampling area but also varing categories and detailed descriptions. To this end, we introduce an image caption dataset LuojiaHOG, which is geospatial-aware, label-extension-friendly and comprehensive-captioned. LuojiaHOG involves the hierarchical spatial sampling, extensible classification system to Open Geospatial Consortium (OGC) standards, and detailed caption generation. In addition, we propose a CLIP-based Image Semantic Enhancement Network (CISEN) to promote sophisticated ITR. CISEN consists of two components, namely dual-path knowledge transfer and progressive cross-modal feature fusion. Comprehensive statistics on LuojiaHOG reveal the richness in sampling diversity, labels quantity and descriptions granularity. The evaluation on LuojiaHOG is conducted across various state-of-the-art ITR models, including ALBEF, ALIGN, CLIP, FILIP, Wukong, GeoRSCLIP and CISEN. We use second- and third-level labels to evaluate these vision-language models through adapter-tuning and CISEN demonstrates superior performance. For instance, it achieves the highest scores with WMAP@5 of 88.47\% and 87.28\% on third-level ITR tasks, respectively. In particular, CISEN exhibits an improvement of approximately 1.3\% and 0.9\% in terms of WMAP@5 compared to its baseline. These findings highlight CISEN advancements accurately retrieving pertinent information across image and text. LuojiaHOG and CISEN can serve as a foundational resource for future RS image-text alignment research, facilitating a wide range of vision-language applications.