 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
SmartSight: Mitigating Hallucination in Video-LLMs Without Compromising Video Understanding via Temporal Attention Collapse
Dec 21, 2025Despite Video Large Language Models having rapidly advanced in recent years, perceptual hallucinations pose a substantial safety risk, which severely restricts their real-world applicability. While several methods for hallucination mitigation have been proposed, they often compromise the model's capacity for video understanding and reasoning. In this work, we propose SmartSight, a pioneering step to address this issue in a training-free manner by leveraging the model's own introspective capabilities. Specifically, SmartSight generates multiple candidate responses to uncover low-hallucinated outputs that are often obscured by standard greedy decoding. It assesses the hallucination of each response using the Temporal Attention Collapse score, which measures whether the model over-focuses on trivial temporal regions of the input video when generating the response. To improve efficiency, SmartSight identifies the Visual Attention Vanishing point, enabling more accurate hallucination estimation and early termination of hallucinated responses, leading to a substantial reduction in decoding cost. Experiments show that SmartSight substantially lowers hallucinations for Qwen2.5-VL-7B by 10.59% on VRIPT-HAL, while simultaneously enhancing video understanding and reasoning, boosting performance on VideoMMMU by up to 8.86%. These results highlight SmartSight's effectiveness in improving the reliability of open-source Video-LLMs.
3D-ANC: Adaptive Neural Collapse for Robust 3D Point Cloud Recognition
Nov 10, 2025Deep neural networks have recently achieved notable progress in 3D point cloud recognition, yet their vulnerability to adversarial perturbations poses critical security challenges in practical deployments. Conventional defense mechanisms struggle to address the evolving landscape of multifaceted attack patterns. Through systematic analysis of existing defenses, we identify that their unsatisfactory performance primarily originates from an entangled feature space, where adversarial attacks can be performed easily. To this end, we present 3D-ANC, a novel approach that capitalizes on the Neural Collapse (NC) mechanism to orchestrate discriminative feature learning. In particular, NC depicts where last-layer features and classifier weights jointly evolve into a simplex equiangular tight frame (ETF) arrangement, establishing maximally separable class prototypes. However, leveraging this advantage in 3D recognition confronts two substantial challenges: (1) prevalent class imbalance in point cloud datasets, and (2) complex geometric similarities between object categories. To tackle these obstacles, our solution combines an ETF-aligned classification module with an adaptive training framework consisting of representation-balanced learning (RBL) and dynamic feature direction loss (FDL). 3D-ANC seamlessly empowers existing models to develop disentangled feature spaces despite the complexity in 3D data distribution. Comprehensive evaluations state that 3D-ANC significantly improves the robustness of models with various structures on two datasets. For instance, DGCNN's classification accuracy is elevated from 27.2% to 80.9% on ModelNet40 -- a 53.7% absolute gain that surpasses leading baselines by 34.0%.
ReasoningGuard: Safeguarding Large Reasoning Models with Inference-time Safety Aha Moments
Aug 06, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance in reasoning-intensive tasks, but they remain vulnerable to harmful content generation, particularly in the mid-to-late steps of their reasoning processes. Existing defense mechanisms, however, rely on costly fine-tuning and additional expert knowledge, which restricts their scalability. In this work, we propose ReasoningGuard, an inference-time safeguard for LRMs, which injects timely safety aha moments to steer harmless while helpful reasoning processes. Leveraging the model's internal attention behavior, our approach accurately identifies critical points in the reasoning path, and triggers spontaneous, safety-oriented reflection. To safeguard both the subsequent reasoning steps and the final answers, we further implement a scaling sampling strategy during the decoding phase, selecting the optimal reasoning path. Inducing minimal extra inference cost, ReasoningGuard effectively mitigates three types of jailbreak attacks, including the latest ones targeting the reasoning process of LRMs. Our approach outperforms seven existing safeguards, achieving state-of-the-art safety defenses while effectively avoiding the common exaggerated safety issues.
Morph: ChirpTransformer-based Encoder-decoder Co-design for Reliable LoRa Communication
Jul 30, 2025In this paper, we propose Morph, a LoRa encoder-decoder co-design to enhance communication reliability while improving its computation efficiency in extremely-low signal-to-noise ratio (SNR) situations. The standard LoRa encoder controls 6 Spreading Factors (SFs) to tradeoff SNR tolerance with data rate. SF-12 is the maximum SF providing the lowest SNR tolerance on commercial off-the-shelf (COTS) LoRa nodes. In Morph, we develop an SF-configuration based encoder to mimic the larger SFs beyond SF-12 while it is compatible with COTS LoRa nodes. Specifically, we manipulate four SF configurations of a Morph symbol to encode 2-bit data. Accordingly, we recognize the used SF configuration of the symbol for data decoding. We leverage a Deep Neural Network (DNN) decoder to fully capture multi-dimensional features among diverse SF configurations to maximize the SNR gain. Moreover, we customize the input size, neural network structure, and training method of the DNN decoder to improve its efficiency, reliability, and generalizability. We implement Morph with COTS LoRa nodes and a USRP N210, then evaluate its performance on indoor and campus-scale testbeds. Results show that we can reliably decode data at -28.8~dB SNR, which is 6.4~dB lower than the standard LoRa with SF-12 chirps. In addition, the computation efficiency of our DNN decoder is about 3x higher than state-of-the-art.
Reading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
InfoCons: Identifying Interpretable Critical Concepts in Point Clouds via Information Theory
May 26, 2025Interpretability of point cloud (PC) models becomes imperative given their deployment in safety-critical scenarios such as autonomous vehicles. We focus on attributing PC model outputs to interpretable critical concepts, defined as meaningful subsets of the input point cloud. To enable human-understandable diagnostics of model failures, an ideal critical subset should be *faithful* (preserving points that causally influence predictions) and *conceptually coherent* (forming semantically meaningful structures that align with human perception). We propose InfoCons, an explanation framework that applies information-theoretic principles to decompose the point cloud into 3D concepts, enabling the examination of their causal effect on model predictions with learnable priors. We evaluate InfoCons on synthetic datasets for classification, comparing it qualitatively and quantitatively with four baselines. We further demonstrate its scalability and flexibility on two real-world datasets and in two applications that utilize critical scores of PC.
Detect-and-Guide: Self-regulation of Diffusion Models for Safe Text-to-Image Generation via Guideline Token Optimization
Mar 19, 2025

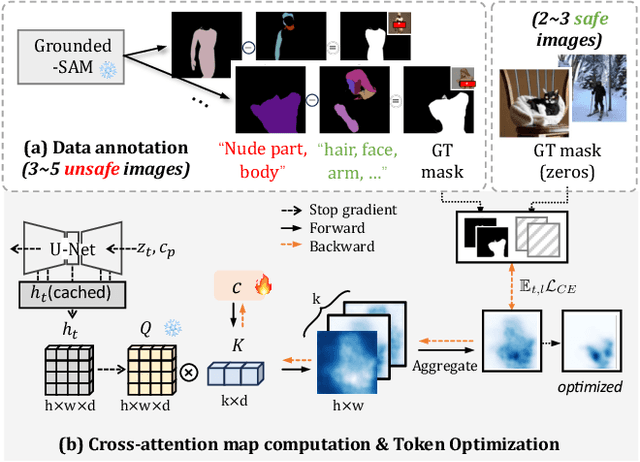
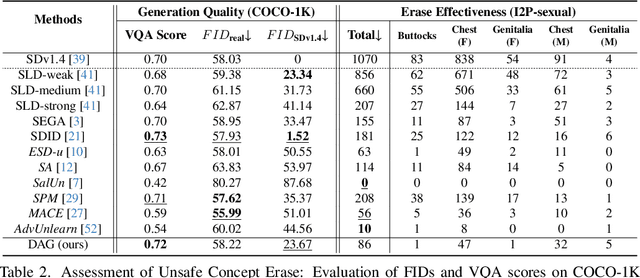
Text-to-image diffusion models have achieved state-of-the-art results in synthesis tasks; however, there is a growing concern about their potential misuse in creating harmful content. To mitigate these risks, post-hoc model intervention techniques, such as concept unlearning and safety guidance, have been developed. However, fine-tuning model weights or adapting the hidden states of the diffusion model operates in an uninterpretable way, making it unclear which part of the intermediate variables is responsible for unsafe generation. These interventions severely affect the sampling trajectory when erasing harmful concepts from complex, multi-concept prompts, thus hindering their practical use in real-world settings. In this work, we propose the safe generation framework Detect-and-Guide (DAG), leveraging the internal knowledge of diffusion models to perform self-diagnosis and fine-grained self-regulation during the sampling process. DAG first detects harmful concepts from noisy latents using refined cross-attention maps of optimized tokens, then applies safety guidance with adaptive strength and editing regions to negate unsafe generation. The optimization only requires a small annotated dataset and can provide precise detection maps with generalizability and concept specificity. Moreover, DAG does not require fine-tuning of diffusion models, and therefore introduces no loss to their generation diversity. Experiments on erasing sexual content show that DAG achieves state-of-the-art safe generation performance, balancing harmfulness mitigation and text-following performance on multi-concept real-world prompts.
SVD-LLM V2: Optimizing Singular Value Truncation for Large Language Model Compression
Mar 16, 2025



Despite significant advancements, the practical deployment of Large Language Models (LLMs) is often hampered by their immense sizes, highlighting the need for effective compression techniques. Singular Value Decomposition (SVD) is a promising LLM compression technique. However, existing SVD-based compression methods fall short in reducing truncation losses, leading to less competitive performance in compressed models. In this work, we introduce SVD-LLM V2, a SVD-based LLM compression method that optimizes singular value truncation in SVD compression with two techniques. First, SVD-LLM V2 proposes to use theoretical truncation loss of weight matrices to assign a unique compression ratio to each weight matrix at different layers to accommodate weight redundancy heterogeneity. Second, SVD-LLM V2 proposes loss-optimized weight truncation to ensure that the truncated singular values result in a lower and more stable truncation loss in practice. We evaluate SVD-LLM V2 on ten datasets and five LLMs at various scales. Our results show SVD-LLM V2 outperforms state-of-the-art SVD-based LLM compression methods. Our code is available at https://github.com/AIoT-MLSys-Lab/SVD-LLM
Revisiting Backdoor Attacks on Time Series Classification in the Frequency Domain
Mar 12, 2025Time series classification (TSC) is a cornerstone of modern web applications, powering tasks such as financial data analysis, network traffic monitoring, and user behavior analysis. In recent years, deep neural networks (DNNs) have greatly enhanced the performance of TSC models in these critical domains. However, DNNs are vulnerable to backdoor attacks, where attackers can covertly implant triggers into models to induce malicious outcomes. Existing backdoor attacks targeting DNN-based TSC models remain elementary. In particular, early methods borrow trigger designs from computer vision, which are ineffective for time series data. More recent approaches utilize generative models for trigger generation, but at the cost of significant computational complexity. In this work, we analyze the limitations of existing attacks and introduce an enhanced method, FreqBack. Drawing inspiration from the fact that DNN models inherently capture frequency domain features in time series data, we identify that improper perturbations in the frequency domain are the root cause of ineffective attacks. To address this, we propose to generate triggers both effectively and efficiently, guided by frequency analysis. FreqBack exhibits substantial performance across five models and eight datasets, achieving an impressive attack success rate of over 90%, while maintaining less than a 3% drop in model accuracy on clean data.