 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
Made to Order: Discovering monotonic temporal changes via self-supervised video ordering
Apr 25, 2024
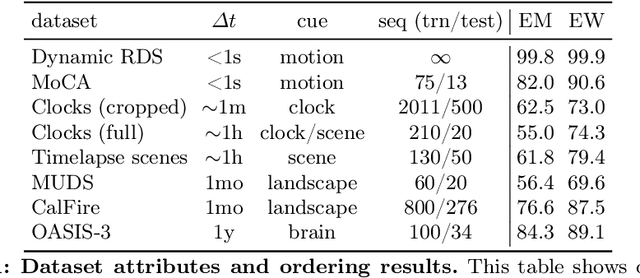

Our objective is to discover and localize monotonic temporal changes in a sequence of images. To achieve this, we exploit a simple proxy task of ordering a shuffled image sequence, with `time' serving as a supervisory signal since only changes that are monotonic with time can give rise to the correct ordering. We also introduce a flexible transformer-based model for general-purpose ordering of image sequences of arbitrary length with built-in attribution maps. After training, the model successfully discovers and localizes monotonic changes while ignoring cyclic and stochastic ones. We demonstrate applications of the model in multiple video settings covering different scene and object types, discovering both object-level and environmental changes in unseen sequences. We also demonstrate that the attention-based attribution maps function as effective prompts for segmenting the changing regions, and that the learned representations can be used for downstream applications. Finally, we show that the model achieves the state of the art on standard benchmarks for ordering a set of images.
Moving Object Segmentation: All You Need Is SAM
Apr 18, 2024


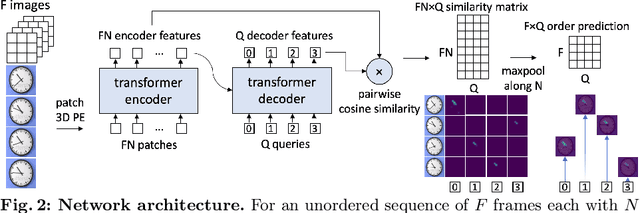
The objective of this paper is motion segmentation -- discovering and segmenting the moving objects in a video. This is a much studied area with numerous careful,and sometimes complex, approaches and training schemes including: self-supervised learning, learning from synthetic datasets, object-centric representations, amodal representations, and many more. Our interest in this paper is to determine if the Segment Anything model (SAM) can contribute to this task. We investigate two models for combining SAM with optical flow that harness the segmentation power of SAM with the ability of flow to discover and group moving objects. In the first model, we adapt SAM to take optical flow, rather than RGB, as an input. In the second, SAM takes RGB as an input, and flow is used as a segmentation prompt. These surprisingly simple methods, without any further modifications, outperform all previous approaches by a considerable margin in both single and multi-object benchmarks. We also extend these frame-level segmentations to sequence-level segmentations that maintain object identity. Again, this simple model outperforms previous methods on multiple video object segmentation benchmarks.
It's About Time: Analog Clock Reading in the Wild
Dec 06, 2021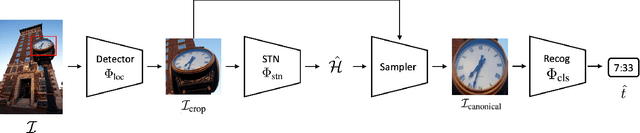
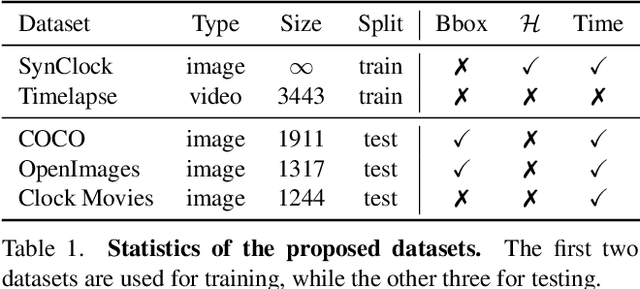

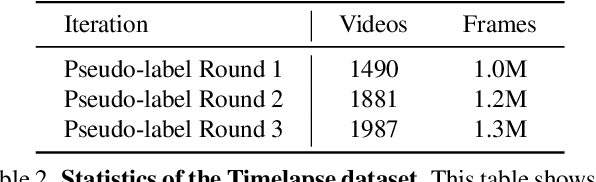
In this paper, we present a framework for reading analog clocks in natural images or videos. Specifically, we make the following contributions: First, we create a scalable pipeline for generating synthetic clocks, significantly reducing the requirements for the labour-intensive annotations; Second, we introduce a clock recognition architecture based on spatial transformer networks (STN), which is trained end-to-end for clock alignment and recognition. We show that the model trained on the proposed synthetic dataset generalises towards real clocks with good accuracy, advocating a Sim2Real training regime; Third, to further reduce the gap between simulation and real data, we leverage the special property of time, i.e. uniformity, to generate reliable pseudo-labels on real unlabelled clock videos, and show that training on these videos offers further improvements while still requiring zero manual annotations. Lastly, we introduce three benchmark datasets based on COCO, Open Images, and The Clock movie, totalling 4,472 images with clocks, with full annotations for time, accurate to the minute.
Self-supervised Video Object Segmentation by Motion Grouping
Apr 15, 2021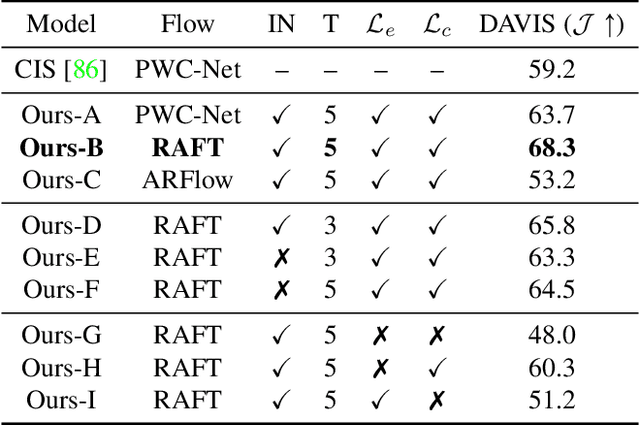

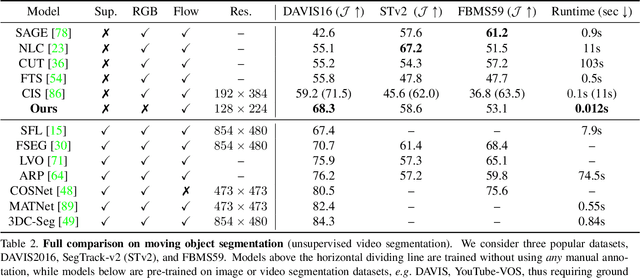
Animals have evolved highly functional visual systems to understand motion, assisting perception even under complex environments. In this paper, we work towards developing a computer vision system able to segment objects by exploiting motion cues, i.e. motion segmentation. We make the following contributions: First, we introduce a simple variant of the Transformer to segment optical flow frames into primary objects and the background. Second, we train the architecture in a self-supervised manner, i.e. without using any manual annotations. Third, we analyze several critical components of our method and conduct thorough ablation studies to validate their necessity. Fourth, we evaluate the proposed architecture on public benchmarks (DAVIS2016, SegTrackv2, and FBMS59). Despite using only optical flow as input, our approach achieves superior or comparable results to previous state-of-the-art self-supervised methods, while being an order of magnitude faster. We additionally evaluate on a challenging camouflage dataset (MoCA), significantly outperforming the other self-supervised approaches, and comparing favourably to the top supervised approach, highlighting the importance of motion cues, and the potential bias towards visual appearance in existing video segmentation models.
Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
Nov 23, 2020
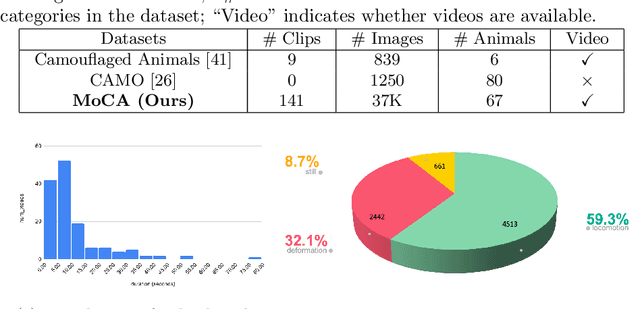
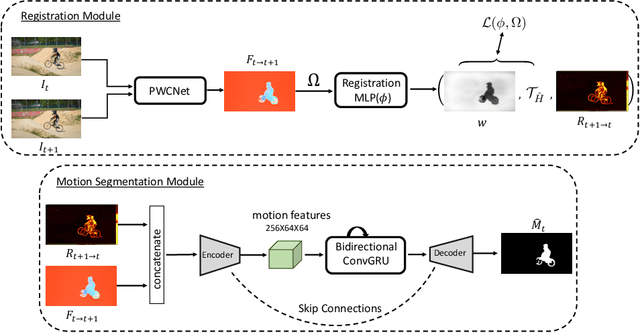
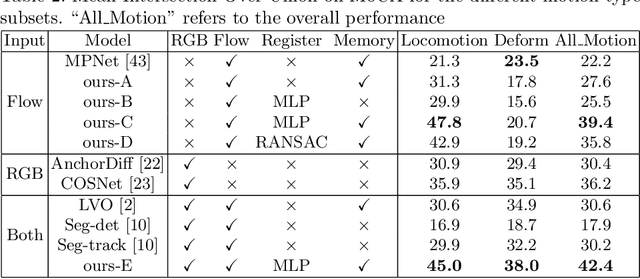
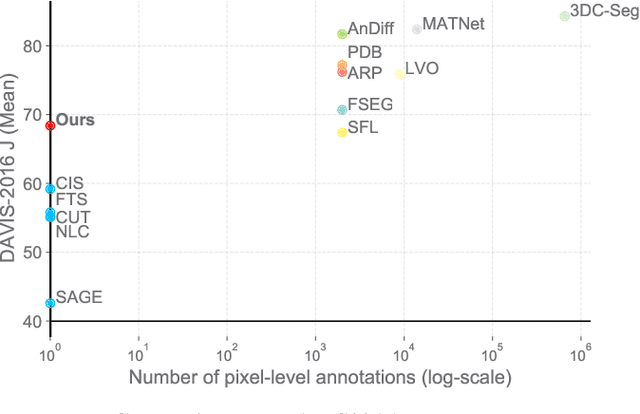
The objective of this paper is to design a computational architecture that discovers camouflaged objects in videos, specifically by exploiting motion information to perform object segmentation. We make the following three contributions: (i) We propose a novel architecture that consists of two essential components for breaking camouflage, namely, a differentiable registration module to align consecutive frames based on the background, which effectively emphasises the object boundary in the difference image, and a motion segmentation module with memory that discovers the moving objects, while maintaining the object permanence even when motion is absent at some point. (ii) We collect the first large-scale Moving Camouflaged Animals (MoCA) video dataset, which consists of over 140 clips across a diverse range of animals (67 categories). (iii) We demonstrate the effectiveness of the proposed model on MoCA, and achieve competitive performance on the unsupervised segmentation protocol on DAVIS2016 by only relying on motion.