 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Making and Breaking of Camouflage
Sep 07, 2023Not all camouflages are equally effective, as even a partially visible contour or a slight color difference can make the animal stand out and break its camouflage. In this paper, we address the question of what makes a camouflage successful, by proposing three scores for automatically assessing its effectiveness. In particular, we show that camouflage can be measured by the similarity between background and foreground features and boundary visibility. We use these camouflage scores to assess and compare all available camouflage datasets. We also incorporate the proposed camouflage score into a generative model as an auxiliary loss and show that effective camouflage images or videos can be synthesised in a scalable manner. The generated synthetic dataset is used to train a transformer-based model for segmenting camouflaged animals in videos. Experimentally, we demonstrate state-of-the-art camouflage breaking performance on the public MoCA-Mask benchmark.
Self-supervised Video Object Segmentation by Motion Grouping
Apr 15, 2021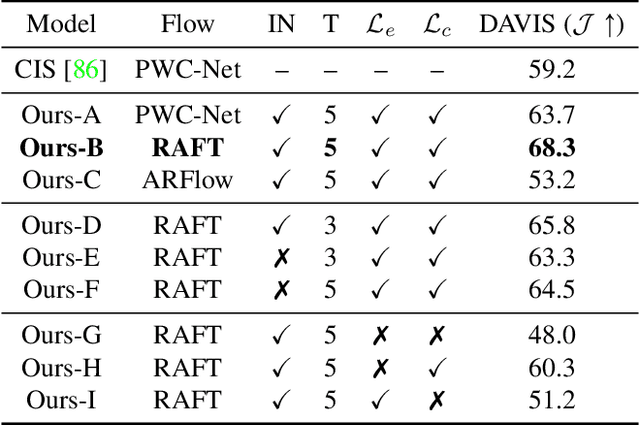

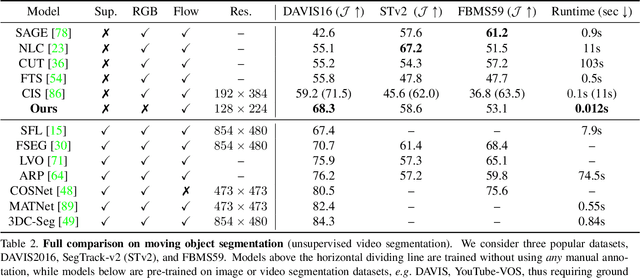
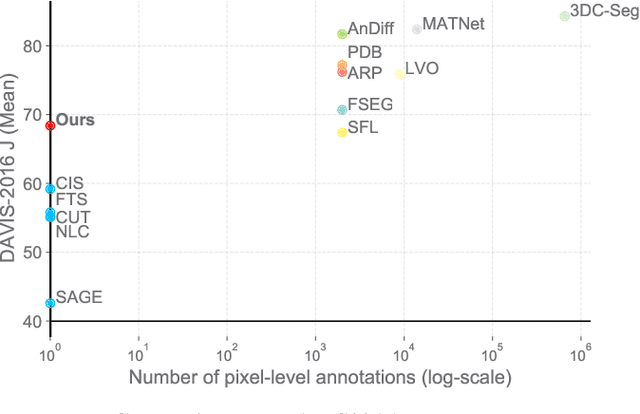
Animals have evolved highly functional visual systems to understand motion, assisting perception even under complex environments. In this paper, we work towards developing a computer vision system able to segment objects by exploiting motion cues, i.e. motion segmentation. We make the following contributions: First, we introduce a simple variant of the Transformer to segment optical flow frames into primary objects and the background. Second, we train the architecture in a self-supervised manner, i.e. without using any manual annotations. Third, we analyze several critical components of our method and conduct thorough ablation studies to validate their necessity. Fourth, we evaluate the proposed architecture on public benchmarks (DAVIS2016, SegTrackv2, and FBMS59). Despite using only optical flow as input, our approach achieves superior or comparable results to previous state-of-the-art self-supervised methods, while being an order of magnitude faster. We additionally evaluate on a challenging camouflage dataset (MoCA), significantly outperforming the other self-supervised approaches, and comparing favourably to the top supervised approach, highlighting the importance of motion cues, and the potential bias towards visual appearance in existing video segmentation models.
Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
Nov 23, 2020
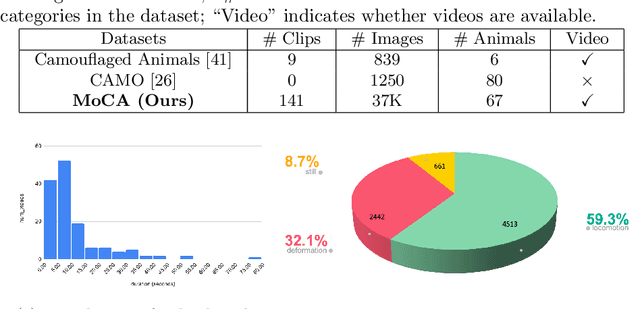
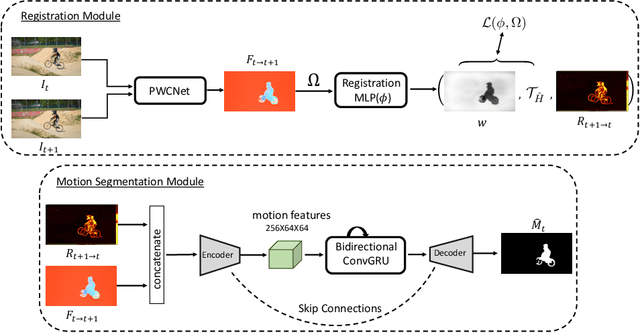
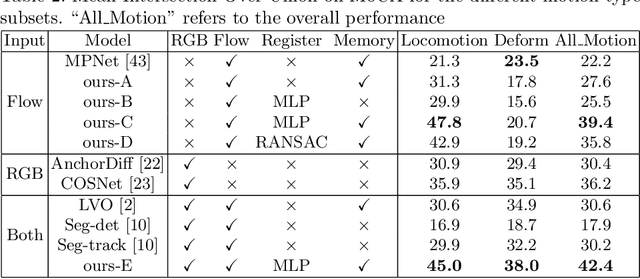
The objective of this paper is to design a computational architecture that discovers camouflaged objects in videos, specifically by exploiting motion information to perform object segmentation. We make the following three contributions: (i) We propose a novel architecture that consists of two essential components for breaking camouflage, namely, a differentiable registration module to align consecutive frames based on the background, which effectively emphasises the object boundary in the difference image, and a motion segmentation module with memory that discovers the moving objects, while maintaining the object permanence even when motion is absent at some point. (ii) We collect the first large-scale Moving Camouflaged Animals (MoCA) video dataset, which consists of over 140 clips across a diverse range of animals (67 categories). (iii) We demonstrate the effectiveness of the proposed model on MoCA, and achieve competitive performance on the unsupervised segmentation protocol on DAVIS2016 by only relying on motion.