 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Grounded Retrieval for Knowledgeable Large Multimodal Models
Jan 27, 2026Visual Question Answering (VQA) often requires coupling fine-grained perception with factual knowledge beyond the input image. Prior multimodal Retrieval-Augmented Generation (MM-RAG) systems improve factual grounding but lack an internal policy for when and how to retrieve. We propose PixSearch, the first end-to-end Segmenting Large Multimodal Model (LMM) that unifies region-level perception and retrieval-augmented reasoning. During encoding, PixSearch emits <search> tokens to trigger retrieval, selects query modalities (text, image, or region), and generates pixel-level masks that directly serve as visual queries, eliminating the reliance on modular pipelines (detectors, segmenters, captioners, etc.). A two-stage supervised fine-tuning regimen with search-interleaved supervision teaches retrieval timing and query selection while preserving segmentation ability. On egocentric and entity-centric VQA benchmarks, PixSearch substantially improves factual consistency and generalization, yielding a 19.7% relative gain in accuracy on CRAG-MM compared to whole image retrieval, while retaining competitive reasoning performance on various VQA and text-only QA tasks.
Reading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
Meta-training with Demonstration Retrieval for Efficient Few-shot Learning
Jun 30, 2023



Large language models show impressive results on few-shot NLP tasks. However, these models are memory and computation-intensive. Meta-training allows one to leverage smaller models for few-shot generalization in a domain-general and task-agnostic manner; however, these methods alone results in models that may not have sufficient parameterization or knowledge to adapt quickly to a large variety of tasks. To overcome this issue, we propose meta-training with demonstration retrieval, where we use a dense passage retriever to retrieve semantically similar labeled demonstrations to each example for more varied supervision. By separating external knowledge from model parameters, we can use meta-training to train parameter-efficient models that generalize well on a larger variety of tasks. We construct a meta-training set from UnifiedQA and CrossFit, and propose a demonstration bank based on UnifiedQA tasks. To our knowledge, our work is the first to combine retrieval with meta-training, to use DPR models to retrieve demonstrations, and to leverage demonstrations from many tasks simultaneously, rather than randomly sampling demonstrations from the training set of the target task. Our approach outperforms a variety of targeted parameter-efficient and retrieval-augmented few-shot methods on QA, NLI, and text classification tasks (including SQuAD, QNLI, and TREC). Our approach can be meta-trained and fine-tuned quickly on a single GPU.
TimelineQA: A Benchmark for Question Answering over Timelines
Jun 01, 2023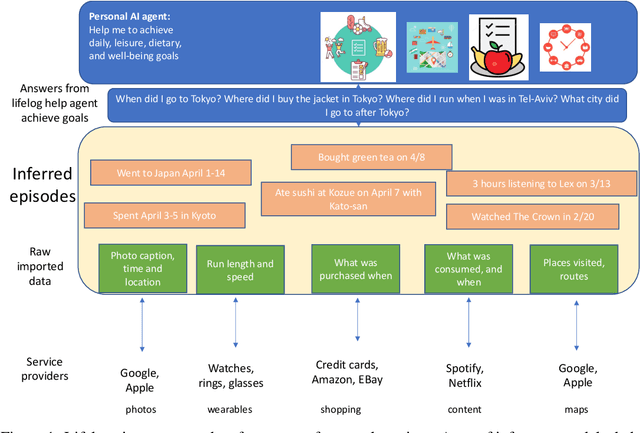



Lifelogs are descriptions of experiences that a person had during their life. Lifelogs are created by fusing data from the multitude of digital services, such as online photos, maps, shopping and content streaming services. Question answering over lifelogs can offer personal assistants a critical resource when they try to provide advice in context. However, obtaining answers to questions over lifelogs is beyond the current state of the art of question answering techniques for a variety of reasons, the most pronounced of which is that lifelogs combine free text with some degree of structure such as temporal and geographical information. We create and publicly release TimelineQA1, a benchmark for accelerating progress on querying lifelogs. TimelineQA generates lifelogs of imaginary people. The episodes in the lifelog range from major life episodes such as high school graduation to those that occur on a daily basis such as going for a run. We describe a set of experiments on TimelineQA with several state-of-the-art QA models. Our experiments reveal that for atomic queries, an extractive QA system significantly out-performs a state-of-the-art retrieval-augmented QA system. For multi-hop queries involving aggregates, we show that the best result is obtained with a state-of-the-art table QA technique, assuming the ground truth set of episodes for deriving the answer is available.
ToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022



Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
Logical Satisfiability of Counterfactuals for Faithful Explanations in NLI
May 25, 2022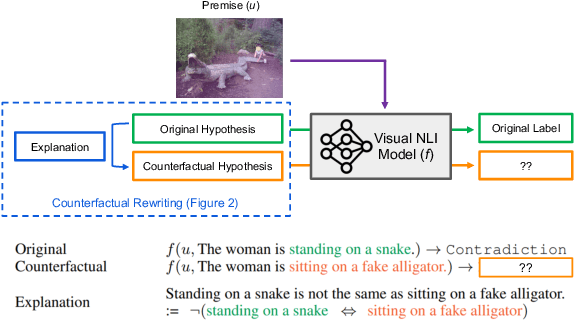


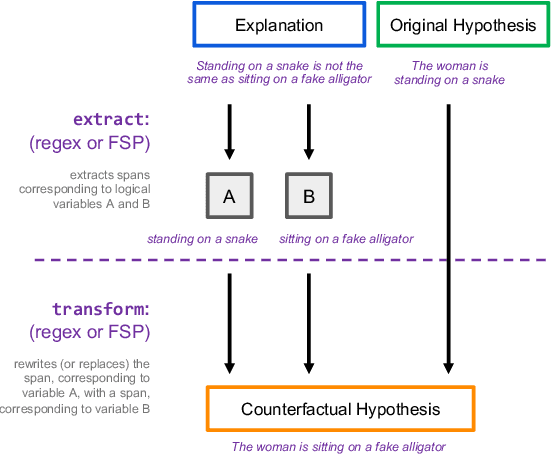
Evaluating an explanation's faithfulness is desired for many reasons such as trust, interpretability and diagnosing the sources of model's errors. In this work, which focuses on the NLI task, we introduce the methodology of Faithfulness-through-Counterfactuals, which first generates a counterfactual hypothesis based on the logical predicates expressed in the explanation, and then evaluates if the model's prediction on the counterfactual is consistent with that expressed logic (i.e. if the new formula is \textit{logically satisfiable}). In contrast to existing approaches, this does not require any explanations for training a separate verification model. We first validate the efficacy of automatic counterfactual hypothesis generation, leveraging on the few-shot priming paradigm. Next, we show that our proposed metric distinguishes between human-model agreement and disagreement on new counterfactual input. In addition, we conduct a sensitivity analysis to validate that our metric is sensitive to unfaithful explanations.
Policy Compliance Detection via Expression Tree Inference
May 24, 2022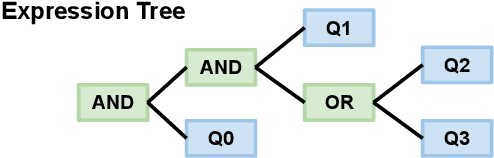

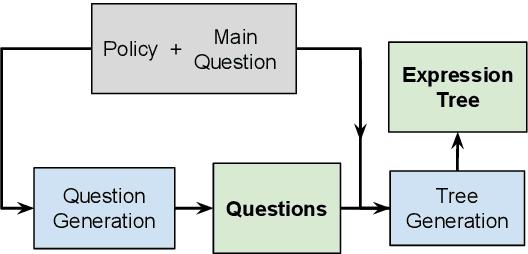
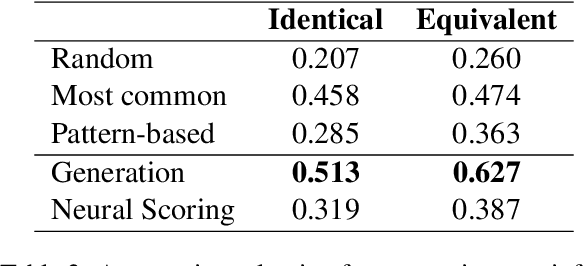
Policy Compliance Detection (PCD) is a task we encounter when reasoning over texts, e.g. legal frameworks. Previous work to address PCD relies heavily on modeling the task as a special case of Recognizing Textual Entailment. Entailment is applicable to the problem of PCD, however viewing the policy as a single proposition, as opposed to multiple interlinked propositions, yields poor performance and lacks explainability. To address this challenge, more recent proposals for PCD have argued for decomposing policies into expression trees consisting of questions connected with logic operators. Question answering is used to obtain answers to these questions with respect to a scenario. Finally, the expression tree is evaluated in order to arrive at an overall solution. However, this work assumes expression trees are provided by experts, thus limiting its applicability to new policies. In this work, we learn how to infer expression trees automatically from policy texts. We ensure the validity of the inferred trees by introducing constrained decoding using a finite state automaton to ensure the generation of valid trees. We determine through automatic evaluation that 63% of the expression trees generated by our constrained generation model are logically equivalent to gold trees. Human evaluation shows that 88% of trees generated by our model are correct.
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
Apr 03, 2022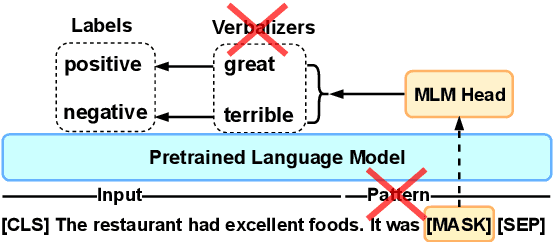
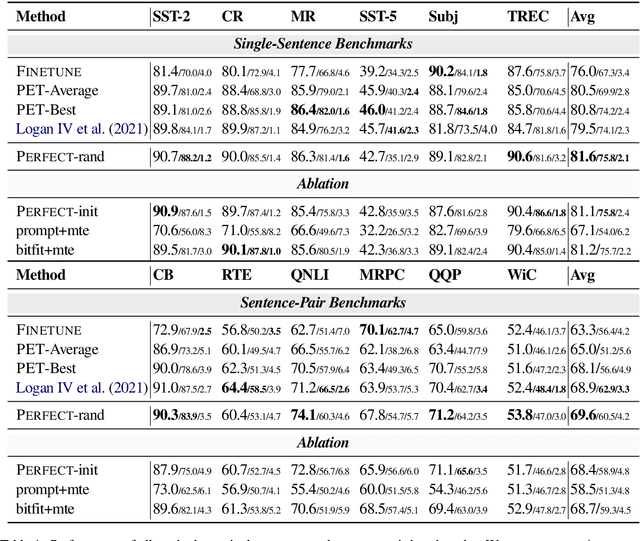
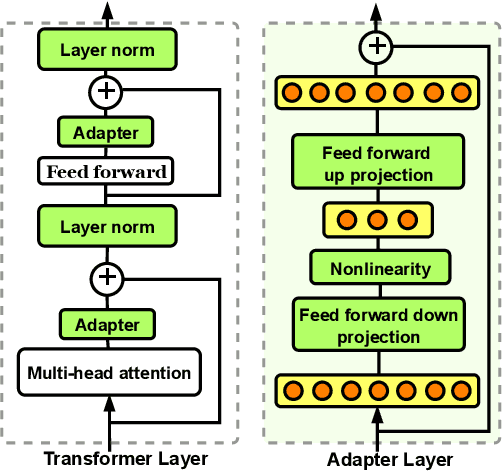
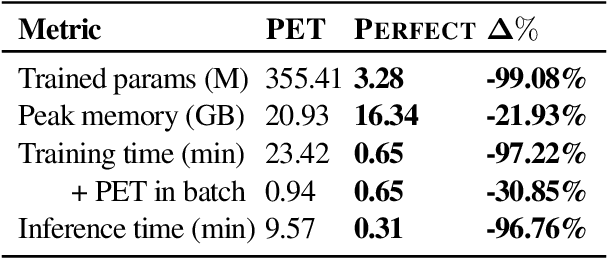
Current methods for few-shot fine-tuning of pretrained masked language models (PLMs) require carefully engineered prompts and verbalizers for each new task to convert examples into a cloze-format that the PLM can score. In this work, we propose PERFECT, a simple and efficient method for few-shot fine-tuning of PLMs without relying on any such handcrafting, which is highly effective given as few as 32 data points. PERFECT makes two key design choices: First, we show that manually engineered task prompts can be replaced with task-specific adapters that enable sample-efficient fine-tuning and reduce memory and storage costs by roughly factors of 5 and 100, respectively. Second, instead of using handcrafted verbalizers, we learn new multi-token label embeddings during fine-tuning, which are not tied to the model vocabulary and which allow us to avoid complex auto-regressive decoding. These embeddings are not only learnable from limited data but also enable nearly 100x faster training and inference. Experiments on a wide range of few-shot NLP tasks demonstrate that PERFECT, while being simple and efficient, also outperforms existing state-of-the-art few-shot learning methods. Our code is publicly available at https://github.com/rabeehk/perfect.
UniREx: A Unified Learning Framework for Language Model Rationale Extraction
Dec 16, 2021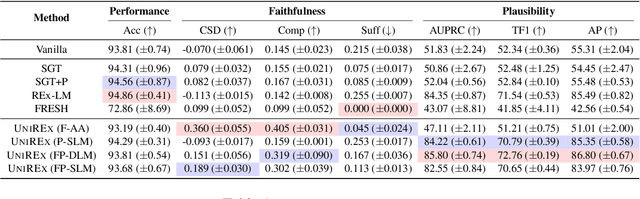
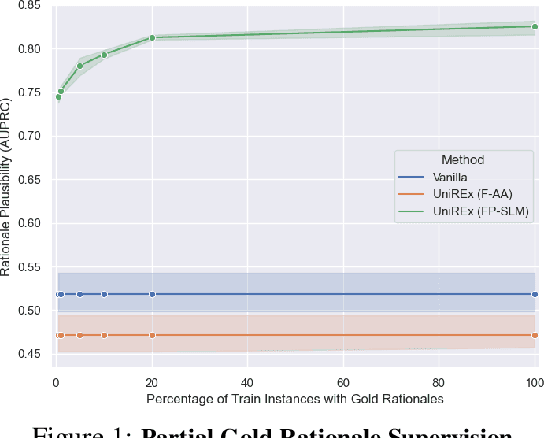
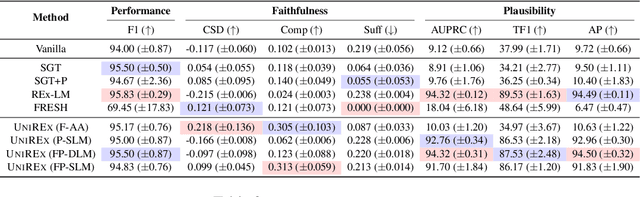
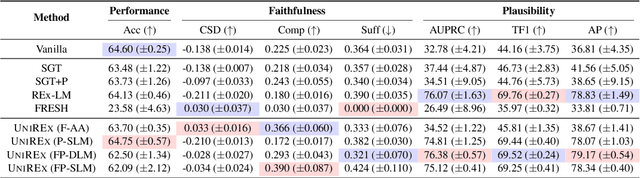
An extractive rationale explains a language model's (LM's) prediction on a given task instance by highlighting the text inputs that most influenced the output. Ideally, rationale extraction should be faithful (reflects LM's behavior), plausible (makes sense to humans), data-efficient, and fast, without sacrificing the LM's task performance. Prior rationale extraction works consist of specialized approaches for addressing various subsets of these desiderata -- but never all five. Narrowly focusing on certain desiderata typically comes at the expense of ignored ones, so existing rationale extractors are often impractical in real-world applications. To tackle this challenge, we propose UniREx, a unified and highly flexible learning framework for rationale extraction, which allows users to easily account for all five factors. UniREx enables end-to-end customization of the rationale extractor training process, supporting arbitrary: (1) heuristic/learned rationale extractors, (2) combinations of faithfulness and/or plausibility objectives, and (3) amounts of gold rationale supervision. Across three text classification datasets, our best UniREx configurations achieve a superior balance of the five desiderata, when compared to strong baselines. Furthermore, UniREx-trained rationale extractors can even generalize to unseen datasets and tasks.
UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
Oct 14, 2021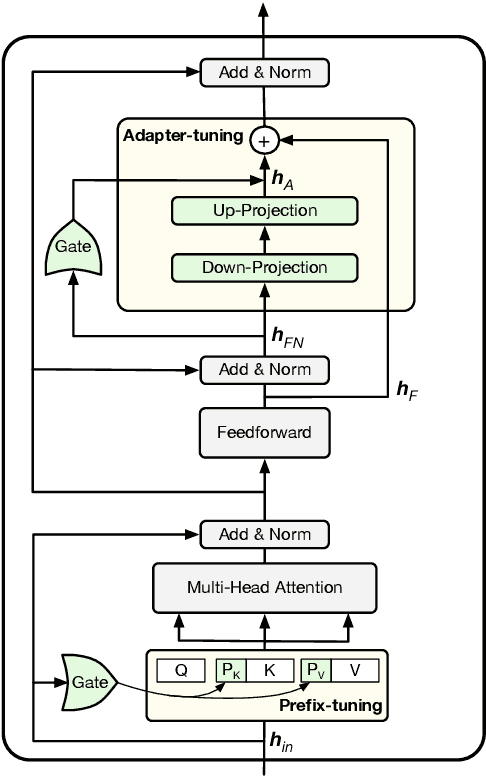
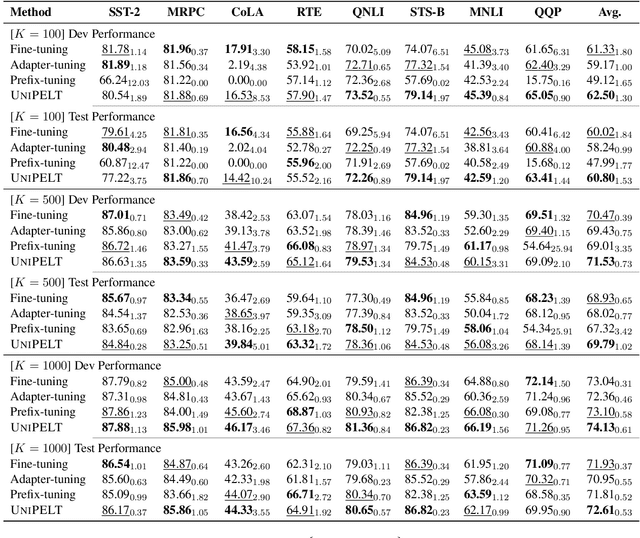
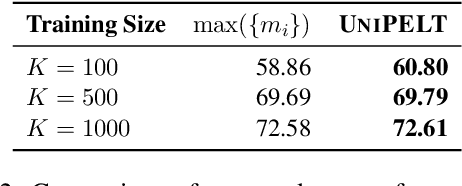
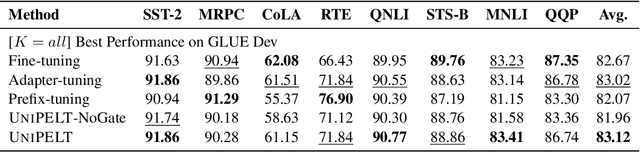
Conventional fine-tuning of pre-trained language models tunes all model parameters and stores a full model copy for each downstream task, which has become increasingly infeasible as the model size grows larger. Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when the training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and downstream tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UniPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup. Remarkably, on the GLUE benchmark, UniPELT consistently achieves 1~3pt gains compared to the best individual PELT method that it incorporates and even outperforms fine-tuning under different setups. Moreover, UniPELT often surpasses the upper bound when taking the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.