 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Satisfiability of Counterfactuals for Faithful Explanations in NLI
May 25, 2022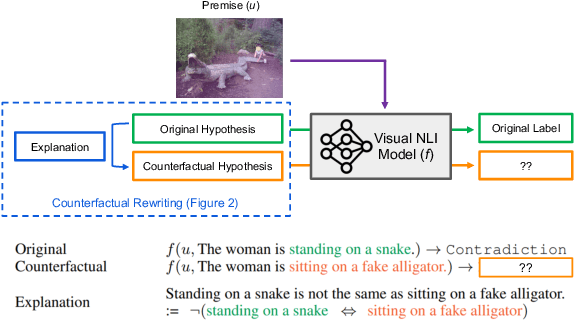


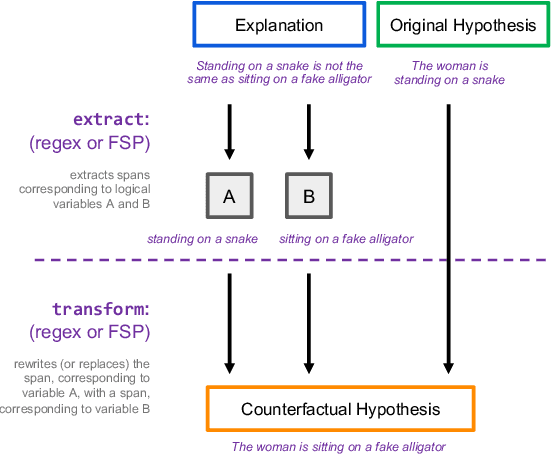
Evaluating an explanation's faithfulness is desired for many reasons such as trust, interpretability and diagnosing the sources of model's errors. In this work, which focuses on the NLI task, we introduce the methodology of Faithfulness-through-Counterfactuals, which first generates a counterfactual hypothesis based on the logical predicates expressed in the explanation, and then evaluates if the model's prediction on the counterfactual is consistent with that expressed logic (i.e. if the new formula is \textit{logically satisfiable}). In contrast to existing approaches, this does not require any explanations for training a separate verification model. We first validate the efficacy of automatic counterfactual hypothesis generation, leveraging on the few-shot priming paradigm. Next, we show that our proposed metric distinguishes between human-model agreement and disagreement on new counterfactual input. In addition, we conduct a sensitivity analysis to validate that our metric is sensitive to unfaithful explanations.
Schema Curation via Causal Association Rule Mining
Apr 18, 2021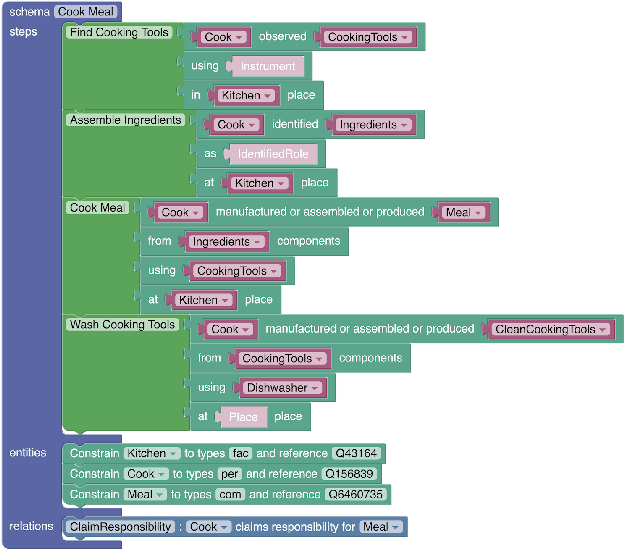



Event schemas are structured knowledge sources defining typical real-world scenarios (e.g., going to an airport). We present a framework for efficient human-in-the-loop construction of a schema library, based on a novel mechanism for schema induction and a well-crafted interface that allows non-experts to "program" complex event structures. Associated with this work we release a machine readable resource (schema library) of 232 detailed event schemas, each of which describe a distinct typical scenario in terms of its relevant sub-event structure (what happens in the scenario), participants (who plays a role in the scenario), fine-grained typing of each participant, and the implied relational constraints between them. Our custom annotation interface, SchemaBlocks, and the event schemas are available online.
InFillmore: Neural Frame Lexicalization for Narrative Text Infilling
Mar 08, 2021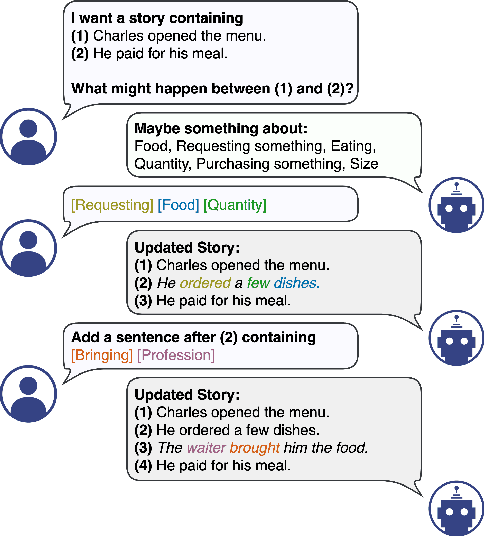
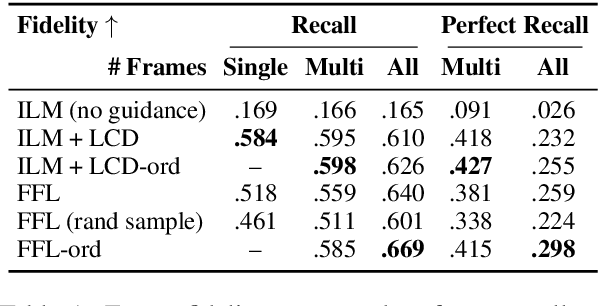

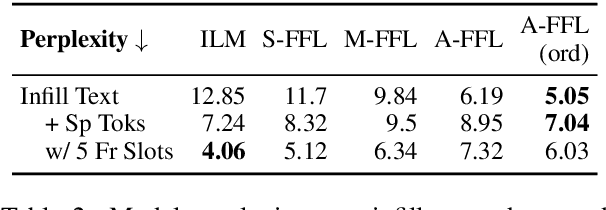
We propose a structured extension to bidirectional-context conditional language generation, or "infilling," inspired by Frame Semantic theory (Fillmore, 1976). Guidance is provided through two approaches: (1) model fine-tuning, conditioning directly on observed symbolic frames, and (2) a novel extension to disjunctive lexically constrained decoding that leverages frame semantic lexical units. Automatic and human evaluations confirm that frame-guided generation allows for explicit manipulation of intended infill semantics, with minimal loss of indistinguishability from the human-generated text. Our methods flexibly apply to a variety of use scenarios, and we provide an interactive web demo available at https://nlp.jhu.edu/demos.
MEMOIR: Multi-class Extreme Classification with Inexact Margin
Nov 24, 2018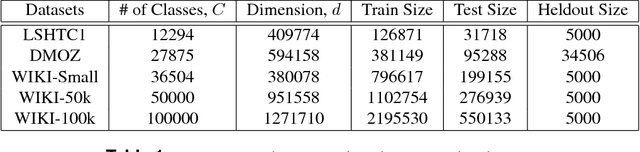
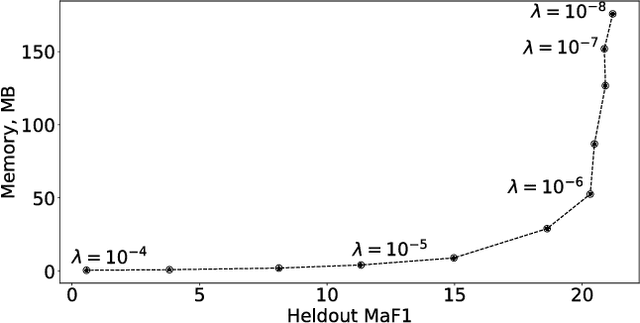

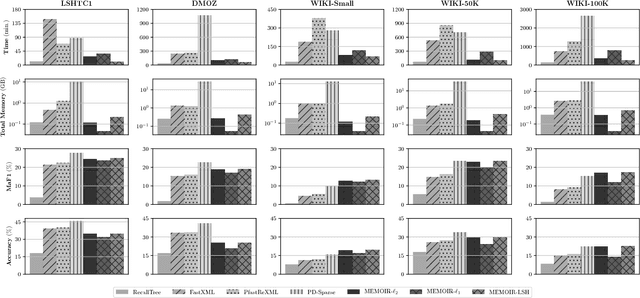
Multi-class classification with a very large number of classes, or extreme classification, is a challenging problem from both statistical and computational perspectives. Most of the classical approaches to multi-class classification, including one-vs-rest or multi-class support vector machines, require the exact estimation of the classifier's margin, at both the training and the prediction steps making them intractable in extreme classification scenarios. In this paper, we study the impact of computing an approximate margin using nearest neighbor (ANN) search structures combined with locality-sensitive hashing (LSH). This approximation allows to dramatically reduce both the training and the prediction time without a significant loss in performance. We theoretically prove that this approximation does not lead to a significant loss of the risk of the model and provide empirical evidence over five publicly available large scale datasets, showing that the proposed approach is highly competitive with respect to state-of-the-art approaches on time, memory and performance measures.
Towards Large-Scale Exploratory Search over Heterogeneous Sources
Nov 20, 2018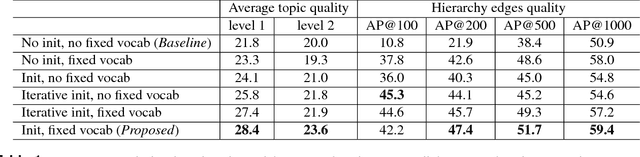
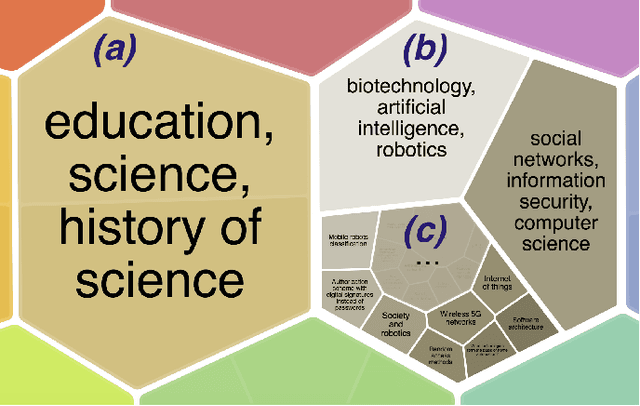

Since time immemorial, people have been looking for ways to organize scientific knowledge into some systems to facilitate search and discovery of new ideas. The problem was partially solved in the pre-Internet era using library classifications, but nowadays it is nearly impossible to classify all scientific and popular scientific knowledge manually. There is a clear gap between the diversity and the amount of data available on the Internet and the algorithms for automatic structuring of such data. In our preliminary study, we approach the problem of knowledge discovery on web-scale data with diverse text sources and propose an algorithm to aggregate multiple collections into a single hierarchical topic model. We implement a web service named Rysearch to demonstrate the concept of topical exploratory search and make it available online.
Construction and Quality Evaluation of Heterogeneous Hierarchical Topic Models
Nov 07, 2018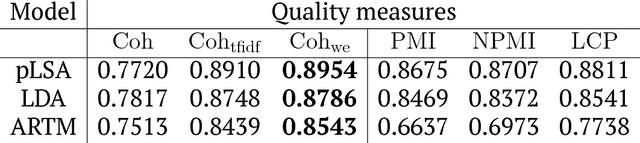
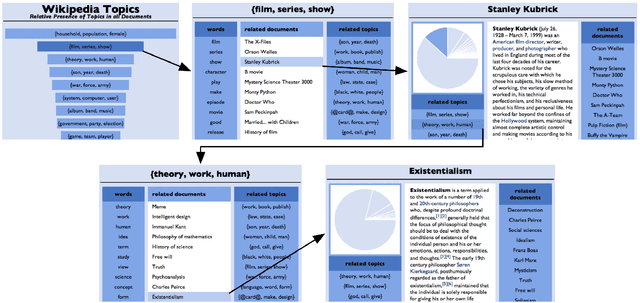
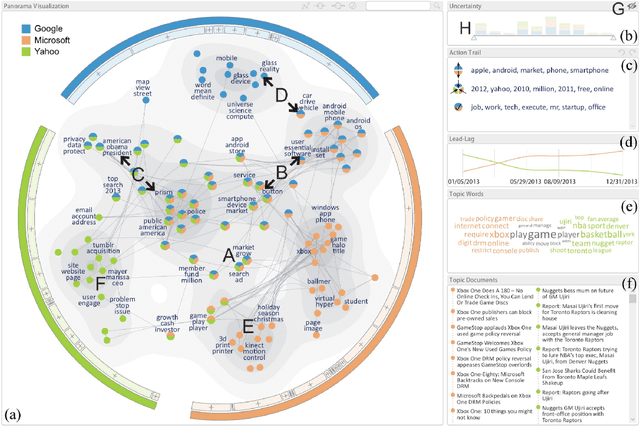
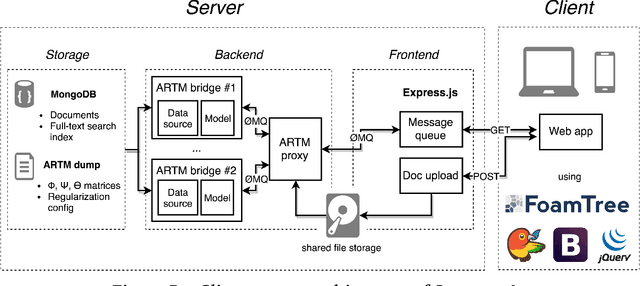
In our work, we propose to represent HTM as a set of flat models, or layers, and a set of topical hierarchies, or edges. We suggest several quality measures for edges of hierarchical models, resembling those proposed for flat models. We conduct an assessment experimentation and show strong correlation between the proposed measures and human judgement on topical edge quality. We also introduce heterogeneous algorithm to build hierarchical topic models for heterogeneous data sources. We show how making certain adjustments to learning process helps to retain original structure of customized models while allowing for slight coherent modifications for new documents. We evaluate this approach using the proposed measures and show that the proposed heterogeneous algorithm significantly outperforms the baseline concat approach. Finally, we implement our own ESE called Rysearch, which demonstrates the potential of ARTM approach for visualizing large heterogeneous document collections.