 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere does In-context Translation Happen in Large Language Models
Mar 07, 2024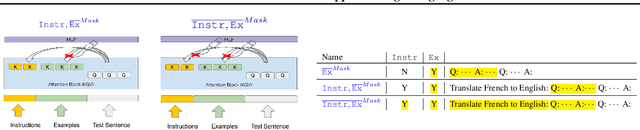

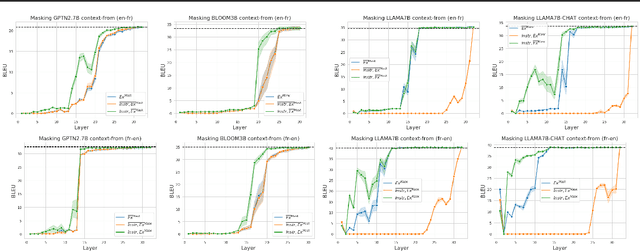

Self-supervised large language models have demonstrated the ability to perform Machine Translation (MT) via in-context learning, but little is known about where the model performs the task with respect to prompt instructions and demonstration examples. In this work, we attempt to characterize the region where large language models transition from in-context learners to translation models. Through a series of layer-wise context-masking experiments on \textsc{GPTNeo2.7B}, \textsc{Bloom3B}, \textsc{Llama7b} and \textsc{Llama7b-chat}, we demonstrate evidence of a "task recognition" point where the translation task is encoded into the input representations and attention to context is no longer necessary. We further observe correspondence between the low performance when masking out entire layers, and the task recognition layers. Taking advantage of this redundancy results in 45\% computational savings when prompting with 5 examples, and task recognition achieved at layer 14 / 32. Our layer-wise fine-tuning experiments indicate that the most effective layers for MT fine-tuning are the layers critical to task recognition.
Anti-LM Decoding for Zero-shot In-context Machine Translation
Nov 14, 2023
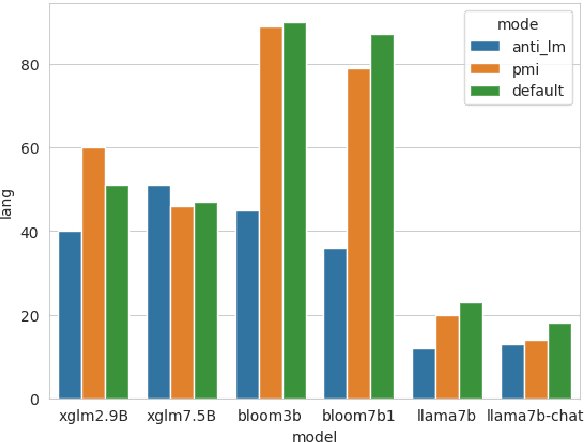
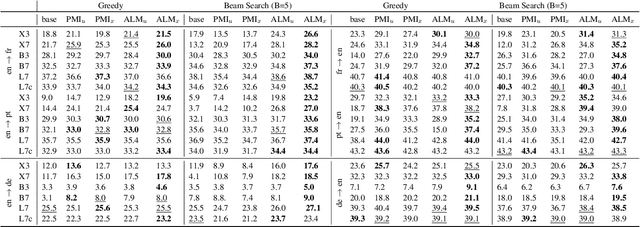
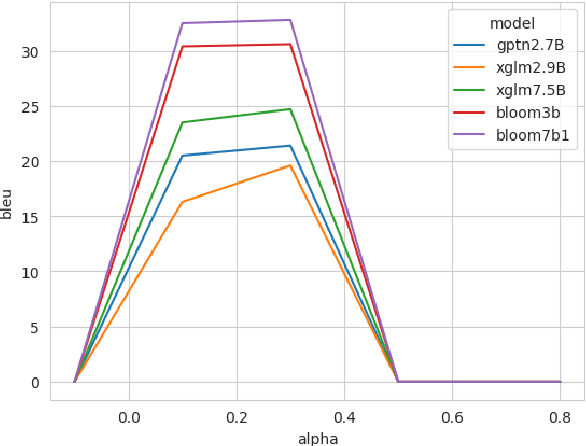
Zero-shot In-context learning is the phenomenon where models can perform the task simply given the instructions. However, pre-trained large language models are known to be poorly calibrated for this task. One of the most effective approaches to handling this bias is to adopt a contrastive decoding objective, which accounts for the prior probability of generating the next token by conditioning on some context. This work introduces an Anti-Language Model objective with a decay factor designed to address the weaknesses of In-context Machine Translation. We conduct our experiments across 3 model types and sizes, 3 language directions, and for both greedy decoding and beam search ($B=5$). The proposed method outperforms other state-of-art decoding objectives, with up to $20$ BLEU point improvement from the default objective observed in some settings.
In-context Learning as Maintaining Coherency: A Study of On-the-fly Machine Translation Using Large Language Models
May 05, 2023
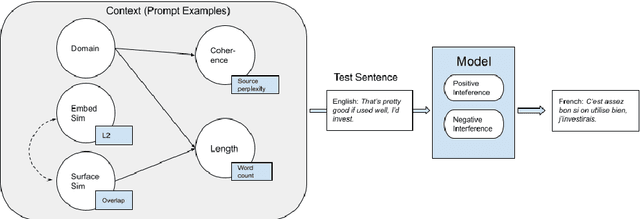

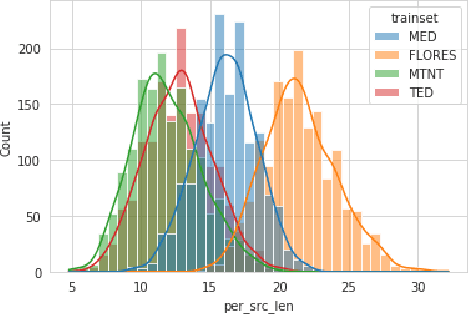
The phenomena of in-context learning has typically been thought of as "learning from examples". In this work which focuses on Machine Translation, we present a perspective of in-context learning as the desired generation task maintaining coherency with its context, i.e., the prompt examples. We first investigate randomly sampled prompts across 4 domains, and find that translation performance improves when shown in-domain prompts. Next, we investigate coherency for the in-domain setting, which uses prompt examples from a moving window. We study this with respect to other factors that have previously been identified in the literature such as length, surface similarity and sentence embedding similarity. Our results across 3 models (GPTNeo2.7B, Bloom3B, XGLM2.9B), and three translation directions (\texttt{en}$\rightarrow$\{\texttt{pt, de, fr}\}) suggest that the long-term coherency of the prompts and the test sentence is a good indicator of downstream translation performance. In doing so, we demonstrate the efficacy of In-context Machine Translation for on-the-fly adaptation.
Logical Satisfiability of Counterfactuals for Faithful Explanations in NLI
May 25, 2022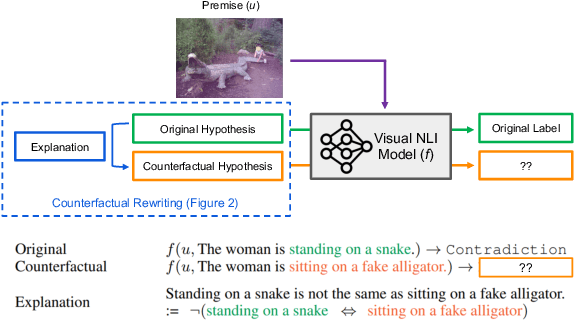


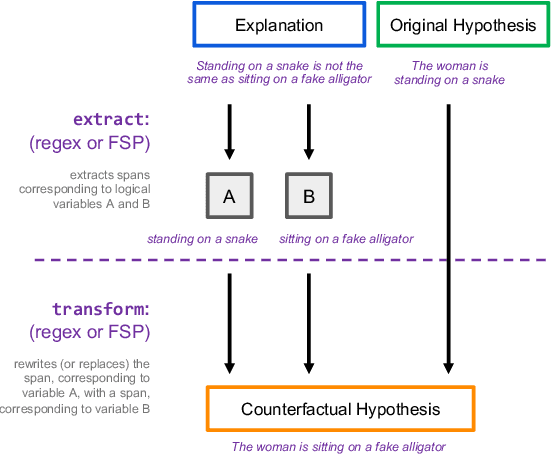
Evaluating an explanation's faithfulness is desired for many reasons such as trust, interpretability and diagnosing the sources of model's errors. In this work, which focuses on the NLI task, we introduce the methodology of Faithfulness-through-Counterfactuals, which first generates a counterfactual hypothesis based on the logical predicates expressed in the explanation, and then evaluates if the model's prediction on the counterfactual is consistent with that expressed logic (i.e. if the new formula is \textit{logically satisfiable}). In contrast to existing approaches, this does not require any explanations for training a separate verification model. We first validate the efficacy of automatic counterfactual hypothesis generation, leveraging on the few-shot priming paradigm. Next, we show that our proposed metric distinguishes between human-model agreement and disagreement on new counterfactual input. In addition, we conduct a sensitivity analysis to validate that our metric is sensitive to unfaithful explanations.
Clustering with UMAP: Why and How Connectivity Matters
Aug 12, 2021
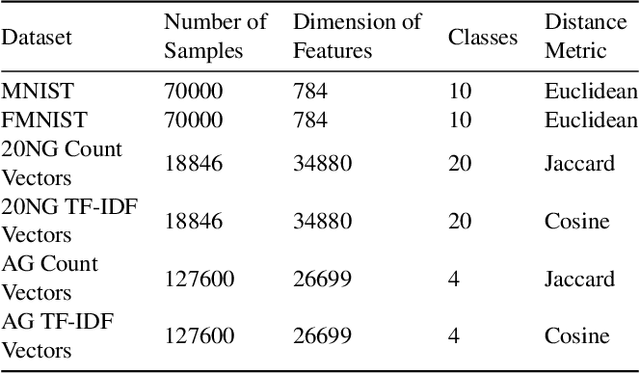
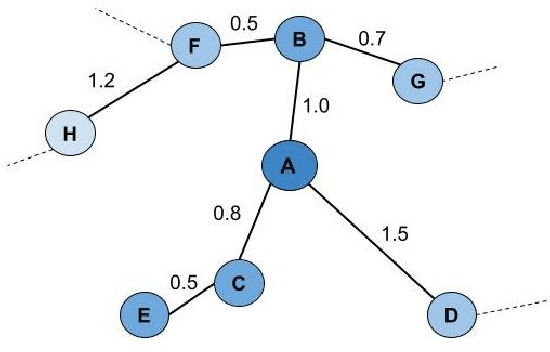
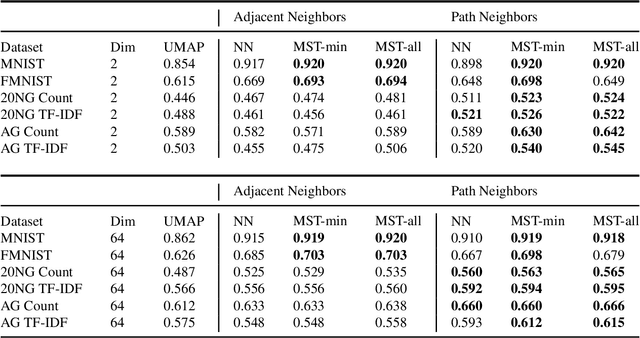
Topology based dimensionality reduction methods such as t-SNE and UMAP have seen increasing success and popularity in high-dimensional data. These methods have strong mathematical foundations and are based on the intuition that the topology in low dimensions should be close to that of high dimensions. Given that the initial topological structure is a precursor to the success of the algorithm, this naturally raises the question: What makes a "good" topological structure for dimensionality reduction? %Insight into this will enable us to design better algorithms which take into account both local and global structure. In this paper which focuses on UMAP, we study the effects of node connectivity (k-Nearest Neighbors vs \textit{mutual} k-Nearest Neighbors) and relative neighborhood (Adjacent via Path Neighbors) on dimensionality reduction. We explore these concepts through extensive ablation studies on 4 standard image and text datasets; MNIST, FMNIST, 20NG, AG, reducing to 2 and 64 dimensions. Our findings indicate that a more refined notion of connectivity (\textit{mutual} k-Nearest Neighbors with minimum spanning tree) together with a flexible method of constructing the local neighborhood (Path Neighbors), can achieve a much better representation than default UMAP, as measured by downstream clustering performance.
Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too!
Apr 30, 2020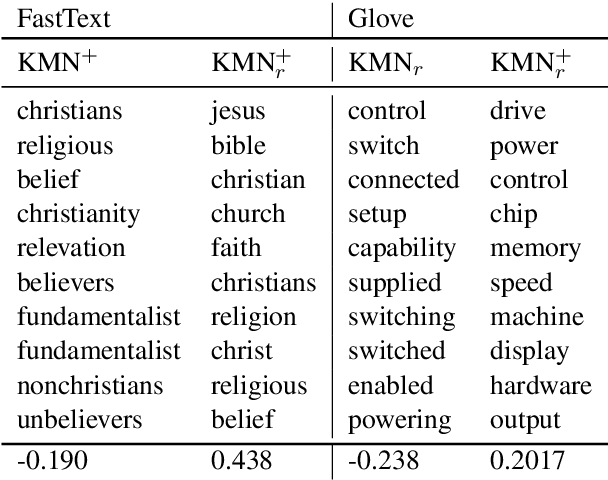
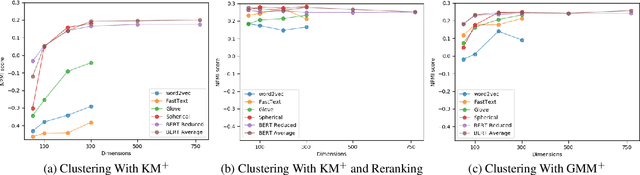
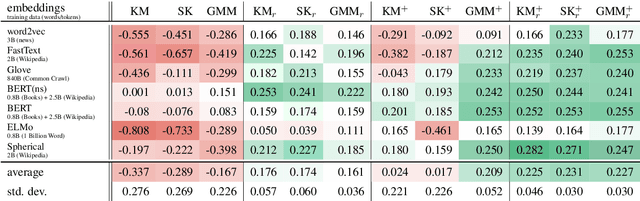
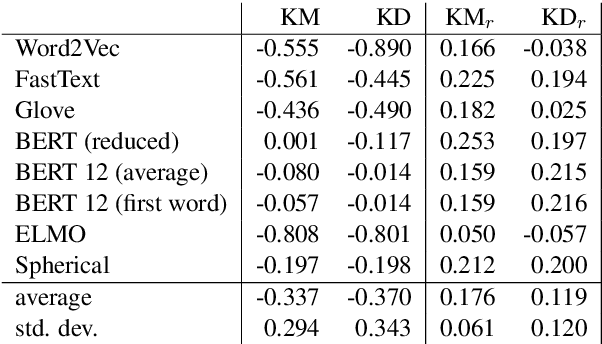
Topic models are a useful analysis tool to uncover the underlying themes within document collections. Probabilistic models which assume a generative story have been the dominant approach for topic modeling. We propose an alternative approach based on clustering readily available pre-trained word embeddings while incorporating document information for weighted clustering and reranking top words. We provide benchmarks for the combination of different word embeddings and clustering algorithms, and analyse their performance under dimensionality reduction with PCA. The best performing combination for our approach is comparable to classical models, and complexity analysis indicate that this is a practical alternative to traditional topic modeling.