 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-LM Decoding for Zero-shot In-context Machine Translation
Paper and Code

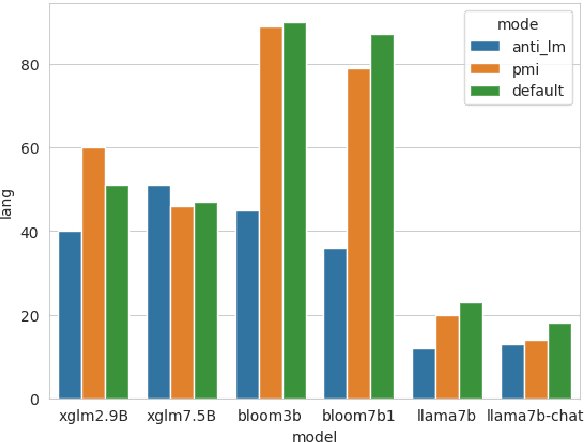
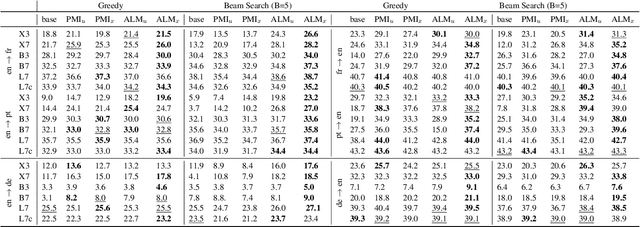
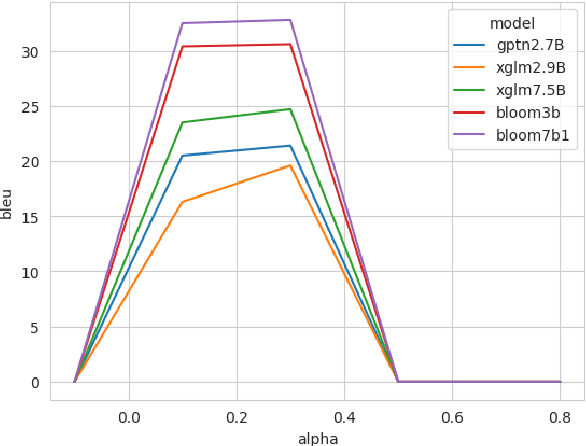
Zero-shot In-context learning is the phenomenon where models can perform the task simply given the instructions. However, pre-trained large language models are known to be poorly calibrated for this task. One of the most effective approaches to handling this bias is to adopt a contrastive decoding objective, which accounts for the prior probability of generating the next token by conditioning on some context. This work introduces an Anti-Language Model objective with a decay factor designed to address the weaknesses of In-context Machine Translation. We conduct our experiments across 3 model types and sizes, 3 language directions, and for both greedy decoding and beam search ($B=5$). The proposed method outperforms other state-of-art decoding objectives, with up to $20$ BLEU point improvement from the default objective observed in some settings.