 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedScore: Factuality Evaluation of Free-Form Medical Answers
May 24, 2025While Large Language Models (LLMs) can generate fluent and convincing responses, they are not necessarily correct. This is especially apparent in the popular decompose-then-verify factuality evaluation pipeline, where LLMs evaluate generations by decomposing the generations into individual, valid claims. Factuality evaluation is especially important for medical answers, since incorrect medical information could seriously harm the patient. However, existing factuality systems are a poor match for the medical domain, as they are typically only evaluated on objective, entity-centric, formulaic texts such as biographies and historical topics. This differs from condition-dependent, conversational, hypothetical, sentence-structure diverse, and subjective medical answers, which makes decomposition into valid facts challenging. We propose MedScore, a new approach to decomposing medical answers into condition-aware valid facts. Our method extracts up to three times more valid facts than existing methods, reducing hallucination and vague references, and retaining condition-dependency in facts. The resulting factuality score significantly varies by decomposition method, verification corpus, and used backbone LLM, highlighting the importance of customizing each step for reliable factuality evaluation.
Can one size fit all?: Measuring Failure in Multi-Document Summarization Domain Transfer
Mar 20, 2025Abstractive multi-document summarization (MDS) is the task of automatically summarizing information in multiple documents, from news articles to conversations with multiple speakers. The training approaches for current MDS models can be grouped into four approaches: end-to-end with special pre-training ("direct"), chunk-then-summarize, extract-then-summarize, and inference with GPT-style models. In this work, we evaluate MDS models across training approaches, domains, and dimensions (reference similarity, quality, and factuality), to analyze how and why models trained on one domain can fail to summarize documents from another (News, Science, and Conversation) in the zero-shot domain transfer setting. We define domain-transfer "failure" as a decrease in factuality, higher deviation from the target, and a general decrease in summary quality. In addition to exploring domain transfer for MDS models, we examine potential issues with applying popular summarization metrics out-of-the-box.
Using Natural Language Inference to Improve Persona Extraction from Dialogue in a New Domain
Jan 12, 2024While valuable datasets such as PersonaChat provide a foundation for training persona-grounded dialogue agents, they lack diversity in conversational and narrative settings, primarily existing in the "real" world. To develop dialogue agents with unique personas, models are trained to converse given a specific persona, but hand-crafting these persona can be time-consuming, thus methods exist to automatically extract persona information from existing character-specific dialogue. However, these persona-extraction models are also trained on datasets derived from PersonaChat and struggle to provide high-quality persona information from conversational settings that do not take place in the real world, such as the fantasy-focused dataset, LIGHT. Creating new data to train models on a specific setting is human-intensive, thus prohibitively expensive. To address both these issues, we introduce a natural language inference method for post-hoc adapting a trained persona extraction model to a new setting. We draw inspiration from the literature of dialog natural language inference (NLI), and devise NLI-reranking methods to extract structured persona information from dialogue. Compared to existing persona extraction models, our method returns higher-quality extracted persona and requires less human annotation.
Anti-LM Decoding for Zero-shot In-context Machine Translation
Nov 14, 2023
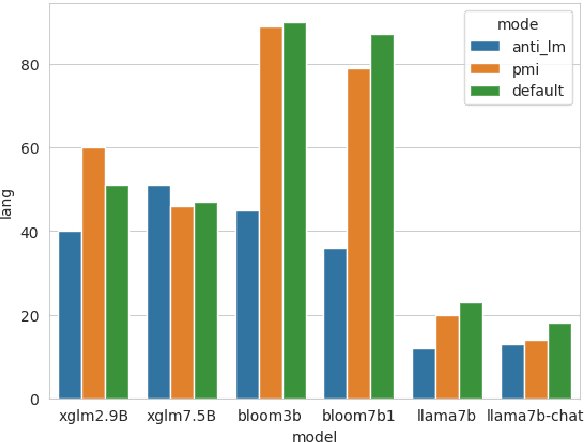
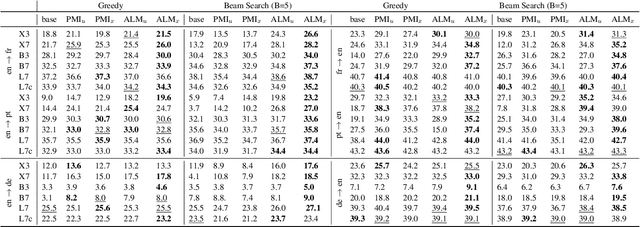
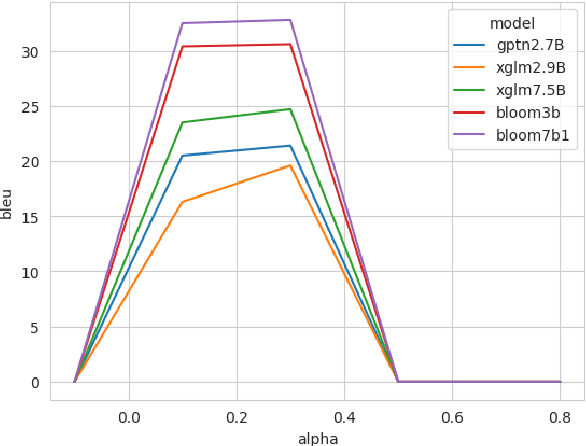
Zero-shot In-context learning is the phenomenon where models can perform the task simply given the instructions. However, pre-trained large language models are known to be poorly calibrated for this task. One of the most effective approaches to handling this bias is to adopt a contrastive decoding objective, which accounts for the prior probability of generating the next token by conditioning on some context. This work introduces an Anti-Language Model objective with a decay factor designed to address the weaknesses of In-context Machine Translation. We conduct our experiments across 3 model types and sizes, 3 language directions, and for both greedy decoding and beam search ($B=5$). The proposed method outperforms other state-of-art decoding objectives, with up to $20$ BLEU point improvement from the default objective observed in some settings.
Decoding Methods for Neural Narrative Generation
Oct 14, 2020

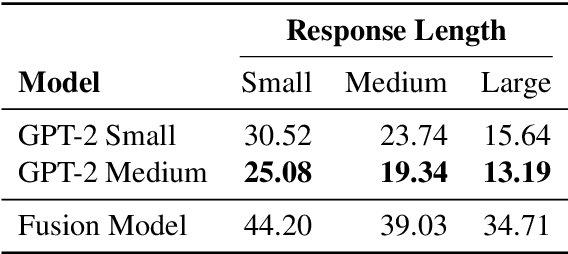
Narrative generation is an open-ended NLP task in which a model generates a story given a prompt. The task is similar to neural response generation for chatbots; however, innovations in response generation are often not applied to narrative generation, despite the similarity between these tasks. We aim to bridge this gap by applying and evaluating advances in decoding methods for neural response generation to neural narrative generation. In particular, we employ GPT-2 and perform ablations across nucleus sampling thresholds and diverse decoding hyperparameters---specifically, maximum mutual information---analyzing results over multiple criteria with automatic and human evaluation. We find that (1) nucleus sampling is generally best within $0.7 \leq p \leq 0.9$; (2) a maximum mutual information objective can improve the quality of generated stories; and (3) established automatic metrics do not correlate well with human judgments of narrative quality on any qualitative metric.