 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComperDial: Commonsense Persona-grounded Dialogue Dataset and Benchmark
Jun 17, 2024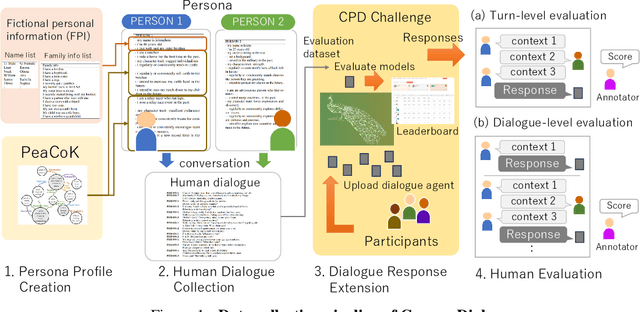

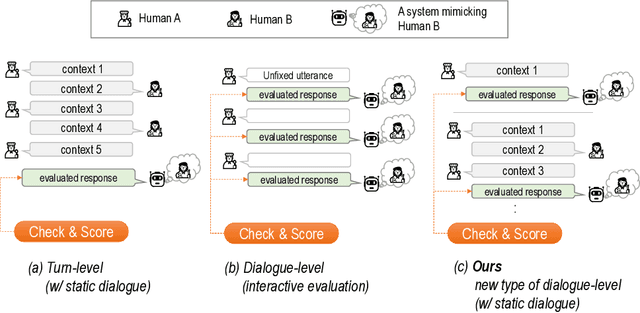
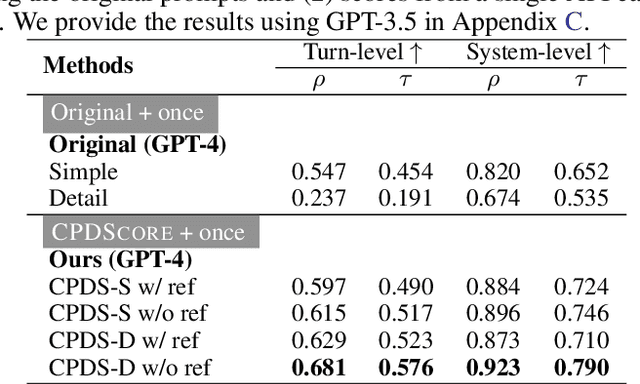
We propose a new benchmark, ComperDial, which facilitates the training and evaluation of evaluation metrics for open-domain dialogue systems. ComperDial consists of human-scored responses for 10,395 dialogue turns in 1,485 conversations collected from 99 dialogue agents submitted to the Commonsense Persona-grounded Dialogue (CPD) challenge. As a result, for any dialogue, our benchmark includes multiple diverse responses with variety of characteristics to ensure more robust evaluation of learned dialogue metrics. In addition to single-turn response scores, ComperDial also contains dialogue-level human-annotated scores, enabling joint assessment of multi-turn model responses throughout a dialogue. Finally, building off ComperDial, we devise a new automatic evaluation metric to measure the general similarity of model-generated dialogues to human conversations. Our experimental results demonstrate that our novel metric, CPDScore is more correlated with human judgments than existing metrics. We release both ComperDial and CPDScore to the community to accelerate development of automatic evaluation metrics for open-domain dialogue systems.
Few-shot Dialogue Strategy Learning for Motivational Interviewing via Inductive Reasoning
Mar 23, 2024We consider the task of building a dialogue system that can motivate users to adopt positive lifestyle changes: Motivational Interviewing. Addressing such a task requires a system that can infer \textit{how} to motivate a user effectively. We propose DIIT, a framework that is capable of learning and applying conversation strategies in the form of natural language inductive rules from expert demonstrations. Automatic and human evaluation on instruction-following large language models show natural language strategy descriptions discovered by DIIR can improve active listening skills, reduce unsolicited advice, and promote more collaborative and less authoritative responses, outperforming various demonstration utilization methods.
Using Natural Language Inference to Improve Persona Extraction from Dialogue in a New Domain
Jan 12, 2024While valuable datasets such as PersonaChat provide a foundation for training persona-grounded dialogue agents, they lack diversity in conversational and narrative settings, primarily existing in the "real" world. To develop dialogue agents with unique personas, models are trained to converse given a specific persona, but hand-crafting these persona can be time-consuming, thus methods exist to automatically extract persona information from existing character-specific dialogue. However, these persona-extraction models are also trained on datasets derived from PersonaChat and struggle to provide high-quality persona information from conversational settings that do not take place in the real world, such as the fantasy-focused dataset, LIGHT. Creating new data to train models on a specific setting is human-intensive, thus prohibitively expensive. To address both these issues, we introduce a natural language inference method for post-hoc adapting a trained persona extraction model to a new setting. We draw inspiration from the literature of dialog natural language inference (NLI), and devise NLI-reranking methods to extract structured persona information from dialogue. Compared to existing persona extraction models, our method returns higher-quality extracted persona and requires less human annotation.