 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
AbstRaL: Augmenting LLMs' Reasoning by Reinforcing Abstract Thinking
Jun 11, 2025Recent studies have shown that large language models (LLMs), especially smaller ones, often lack robustness in their reasoning. I.e., they tend to experience performance drops when faced with distribution shifts, such as changes to numerical or nominal variables, or insertions of distracting clauses. A possible strategy to address this involves generating synthetic data to further "instantiate" reasoning problems on potential variations. In contrast, our approach focuses on "abstracting" reasoning problems. This not only helps counteract distribution shifts but also facilitates the connection to symbolic tools for deriving solutions. We find that this abstraction process is better acquired through reinforcement learning (RL) than just supervised fine-tuning, which often fails to produce faithful abstractions. Our method, AbstRaL -- which promotes abstract reasoning in LLMs using RL on granular abstraction data -- significantly mitigates performance degradation on recent GSM perturbation benchmarks.
Augmenting LLMs' Reasoning by Reinforcing Abstract Thinking
Jun 09, 2025Recent studies have shown that large language models (LLMs), especially smaller ones, often lack robustness in their reasoning. I.e., they tend to experience performance drops when faced with distribution shifts, such as changes to numerical or nominal variables, or insertions of distracting clauses. A possible strategy to address this involves generating synthetic data to further "instantiate" reasoning problems on potential variations. In contrast, our approach focuses on "abstracting" reasoning problems. This not only helps counteract distribution shifts but also facilitates the connection to symbolic tools for deriving solutions. We find that this abstraction process is better acquired through reinforcement learning (RL) than just supervised fine-tuning, which often fails to produce faithful abstractions. Our method, AbstraL -- which promotes abstract reasoning in LLMs using RL on granular abstraction data -- significantly mitigates performance degradation on recent GSM perturbation benchmarks.
VinaBench: Benchmark for Faithful and Consistent Visual Narratives
Mar 26, 2025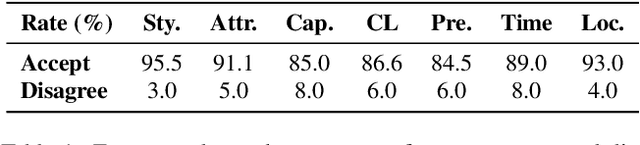
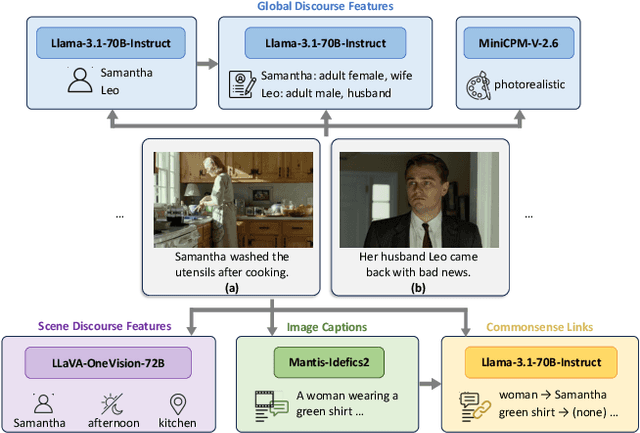
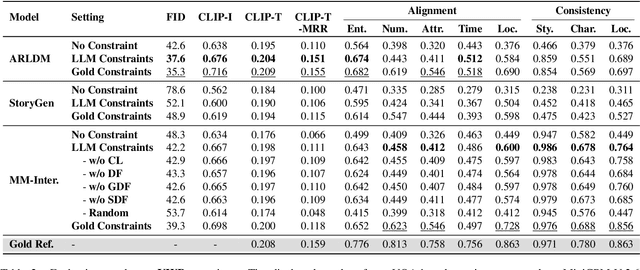
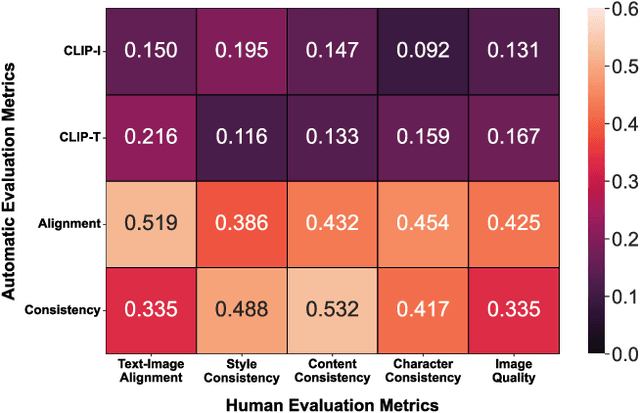
Visual narrative generation transforms textual narratives into sequences of images illustrating the content of the text. However, generating visual narratives that are faithful to the input text and self-consistent across generated images remains an open challenge, due to the lack of knowledge constraints used for planning the stories. In this work, we propose a new benchmark, VinaBench, to address this challenge. Our benchmark annotates the underlying commonsense and discourse constraints in visual narrative samples, offering systematic scaffolds for learning the implicit strategies of visual storytelling. Based on the incorporated narrative constraints, we further propose novel metrics to closely evaluate the consistency of generated narrative images and the alignment of generations with the input textual narrative. Our results across three generative vision models demonstrate that learning with VinaBench's knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
ComperDial: Commonsense Persona-grounded Dialogue Dataset and Benchmark
Jun 17, 2024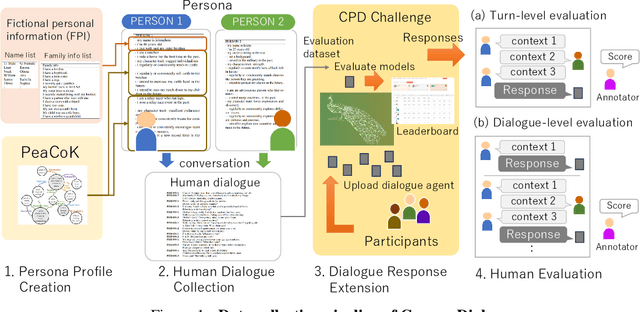

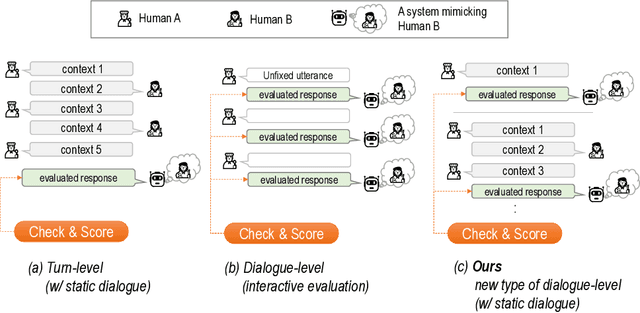
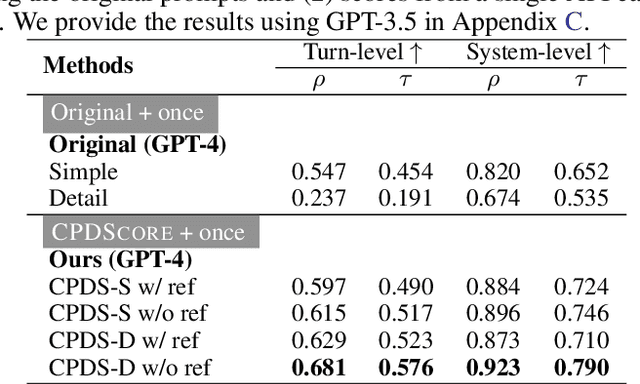
We propose a new benchmark, ComperDial, which facilitates the training and evaluation of evaluation metrics for open-domain dialogue systems. ComperDial consists of human-scored responses for 10,395 dialogue turns in 1,485 conversations collected from 99 dialogue agents submitted to the Commonsense Persona-grounded Dialogue (CPD) challenge. As a result, for any dialogue, our benchmark includes multiple diverse responses with variety of characteristics to ensure more robust evaluation of learned dialogue metrics. In addition to single-turn response scores, ComperDial also contains dialogue-level human-annotated scores, enabling joint assessment of multi-turn model responses throughout a dialogue. Finally, building off ComperDial, we devise a new automatic evaluation metric to measure the general similarity of model-generated dialogues to human conversations. Our experimental results demonstrate that our novel metric, CPDScore is more correlated with human judgments than existing metrics. We release both ComperDial and CPDScore to the community to accelerate development of automatic evaluation metrics for open-domain dialogue systems.
DiffuCOMET: Contextual Commonsense Knowledge Diffusion
Feb 26, 2024

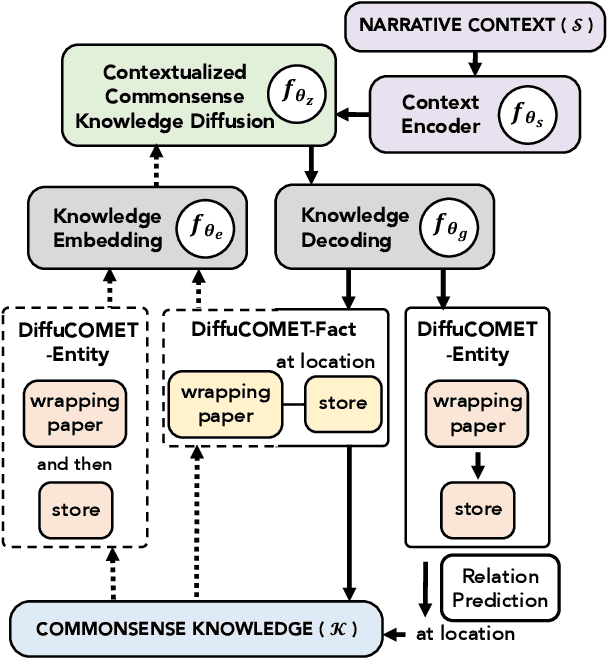
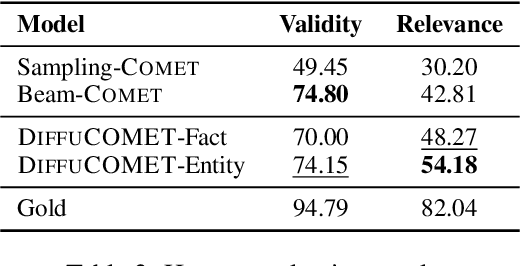
Inferring contextually-relevant and diverse commonsense to understand narratives remains challenging for knowledge models. In this work, we develop a series of knowledge models, DiffuCOMET, that leverage diffusion to learn to reconstruct the implicit semantic connections between narrative contexts and relevant commonsense knowledge. Across multiple diffusion steps, our method progressively refines a representation of commonsense facts that is anchored to a narrative, producing contextually-relevant and diverse commonsense inferences for an input context. To evaluate DiffuCOMET, we introduce new metrics for commonsense inference that more closely measure knowledge diversity and contextual relevance. Our results on two different benchmarks, ComFact and WebNLG+, show that knowledge generated by DiffuCOMET achieves a better trade-off between commonsense diversity, contextual relevance and alignment to known gold references, compared to baseline knowledge models.
A Robust Super-resolution Gridless Imaging Framework for UAV-borne SAR Tomography
Feb 02, 2024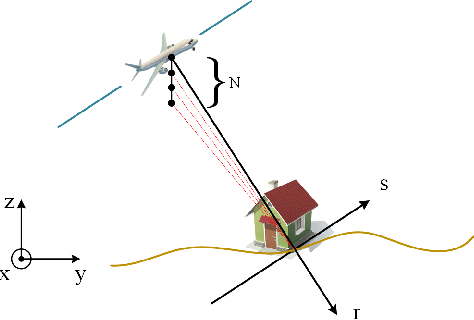
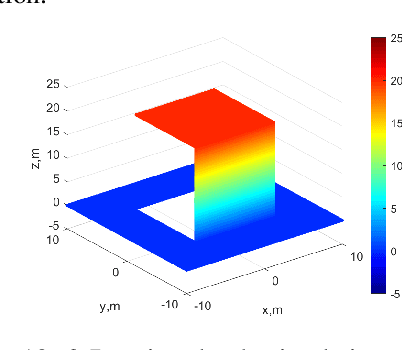
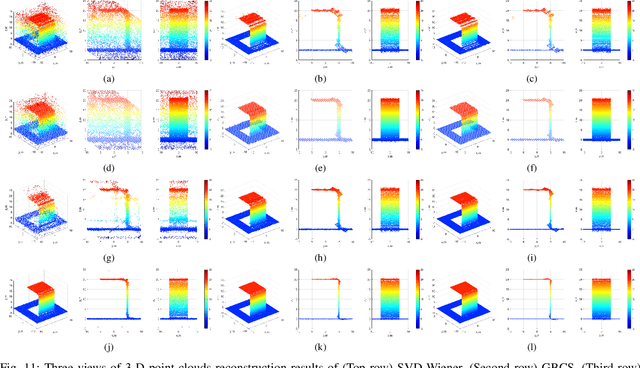
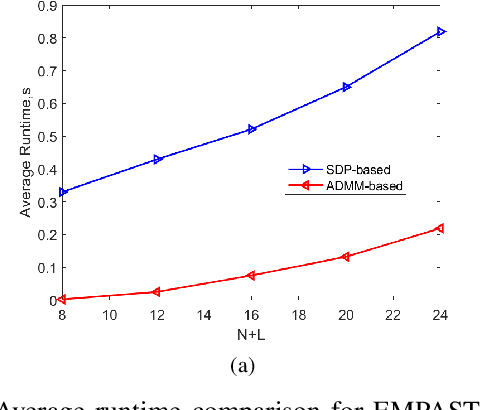
Synthetic aperture radar (SAR) tomography (TomoSAR) retrieves three-dimensional (3-D) information from multiple SAR images, effectively addresses the layover problem, and has become pivotal in urban mapping. Unmanned aerial vehicle (UAV) has gained popularity as a TomoSAR platform, offering distinct advantages such as the ability to achieve 3-D imaging in a single flight, cost-effectiveness, rapid deployment, and flexible trajectory planning. The evolution of compressed sensing (CS) has led to the widespread adoption of sparse reconstruction techniques in TomoSAR signal processing, with a focus on $\ell _1$ norm regularization and other grid-based CS methods. However, the discretization of illuminated scene along elevation introduces modeling errors, resulting in reduced reconstruction accuracy, known as the "off-grid" effect. Recent advancements have introduced gridless CS algorithms to mitigate this issue. This paper presents an innovative gridless 3-D imaging framework tailored for UAV-borne TomoSAR. Capitalizing on the pulse repetition frequency (PRF) redundancy inherent in slow UAV platforms, a multiple measurement vectors (MMV) model is constructed to enhance noise immunity without compromising azimuth-range resolution. Given the sparsely placed array elements due to mounting platform constraints, an atomic norm soft thresholding algorithm is proposed for partially observed MMV, offering gridless reconstruction capability and super-resolution. An efficient alternative optimization algorithm is also employed to enhance computational efficiency. Validation of the proposed framework is achieved through computer simulations and flight experiments, affirming its efficacy in UAV-borne TomoSAR applications.
Efficient Tool Use with Chain-of-Abstraction Reasoning
Jan 30, 2024



To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.
PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
May 03, 2023



Sustaining coherent and engaging narratives requires dialogue or storytelling agents to understand how the personas of speakers or listeners ground the narrative. Specifically, these agents must infer personas of their listeners to produce statements that cater to their interests. They must also learn to maintain consistent speaker personas for themselves throughout the narrative, so that their counterparts feel involved in a realistic conversation or story. However, personas are diverse and complex: they entail large quantities of rich interconnected world knowledge that is challenging to robustly represent in general narrative systems (e.g., a singer is good at singing, and may have attended conservatoire). In this work, we construct a new large-scale persona commonsense knowledge graph, PeaCoK, containing ~100K human-validated persona facts. Our knowledge graph schematizes five dimensions of persona knowledge identified in previous studies of human interactive behaviours, and distils facts in this schema from both existing commonsense knowledge graphs and large-scale pretrained language models. Our analysis indicates that PeaCoK contains rich and precise world persona inferences that help downstream systems generate more consistent and engaging narratives.