 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Semantic-Visual Alignment for Zero-Shot Remote Sensing Image Scene Classification
Feb 03, 2024Deep neural networks have achieved promising progress in remote sensing (RS) image classification, for which the training process requires abundant samples for each class. However, it is time-consuming and unrealistic to annotate labels for each RS category, given the fact that the RS target database is increasing dynamically. Zero-shot learning (ZSL) allows for identifying novel classes that are not seen during training, which provides a promising solution for the aforementioned problem. However, previous ZSL models mainly depend on manually-labeled attributes or word embeddings extracted from language models to transfer knowledge from seen classes to novel classes. Besides, pioneer ZSL models use convolutional neural networks pre-trained on ImageNet, which focus on the main objects appearing in each image, neglecting the background context that also matters in RS scene classification. To address the above problems, we propose to collect visually detectable attributes automatically. We predict attributes for each class by depicting the semantic-visual similarity between attributes and images. In this way, the attribute annotation process is accomplished by machine instead of human as in other methods. Moreover, we propose a Deep Semantic-Visual Alignment (DSVA) that take advantage of the self-attention mechanism in the transformer to associate local image regions together, integrating the background context information for prediction. The DSVA model further utilizes the attribute attention maps to focus on the informative image regions that are essential for knowledge transfer in ZSL, and maps the visual images into attribute space to perform ZSL classification. With extensive experiments, we show that our model outperforms other state-of-the-art models by a large margin on a challenging large-scale RS scene classification benchmark.
* Published in ISPRS P&RS. The code is available at https://github.com/wenjiaXu/RS_Scene_ZSL
A Robust Super-resolution Gridless Imaging Framework for UAV-borne SAR Tomography
Feb 02, 2024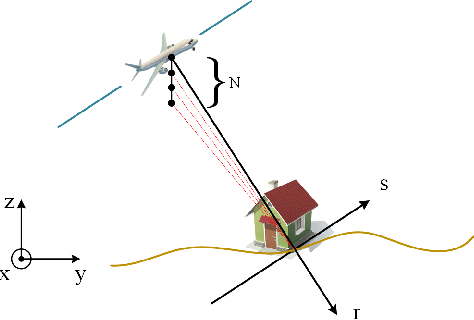
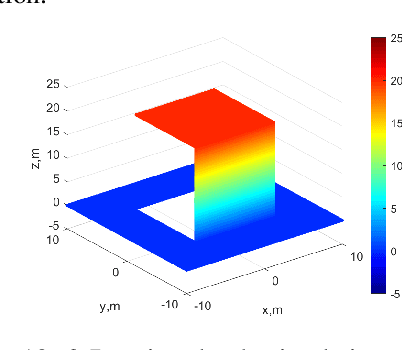
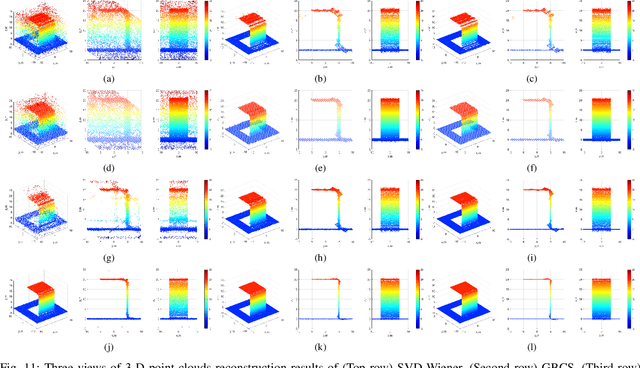
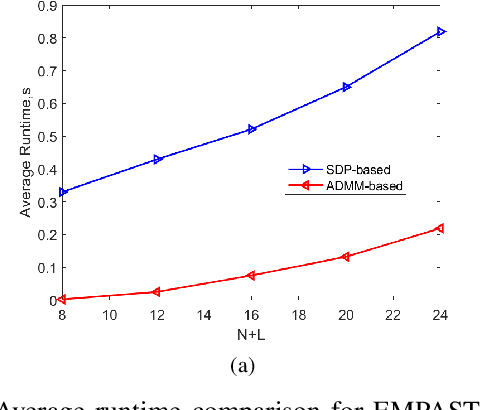
Synthetic aperture radar (SAR) tomography (TomoSAR) retrieves three-dimensional (3-D) information from multiple SAR images, effectively addresses the layover problem, and has become pivotal in urban mapping. Unmanned aerial vehicle (UAV) has gained popularity as a TomoSAR platform, offering distinct advantages such as the ability to achieve 3-D imaging in a single flight, cost-effectiveness, rapid deployment, and flexible trajectory planning. The evolution of compressed sensing (CS) has led to the widespread adoption of sparse reconstruction techniques in TomoSAR signal processing, with a focus on $\ell _1$ norm regularization and other grid-based CS methods. However, the discretization of illuminated scene along elevation introduces modeling errors, resulting in reduced reconstruction accuracy, known as the "off-grid" effect. Recent advancements have introduced gridless CS algorithms to mitigate this issue. This paper presents an innovative gridless 3-D imaging framework tailored for UAV-borne TomoSAR. Capitalizing on the pulse repetition frequency (PRF) redundancy inherent in slow UAV platforms, a multiple measurement vectors (MMV) model is constructed to enhance noise immunity without compromising azimuth-range resolution. Given the sparsely placed array elements due to mounting platform constraints, an atomic norm soft thresholding algorithm is proposed for partially observed MMV, offering gridless reconstruction capability and super-resolution. An efficient alternative optimization algorithm is also employed to enhance computational efficiency. Validation of the proposed framework is achieved through computer simulations and flight experiments, affirming its efficacy in UAV-borne TomoSAR applications.
CVGG-Net: Ship Recognition for SAR Images Based on Complex-Valued Convolutional Neural Network
May 13, 2023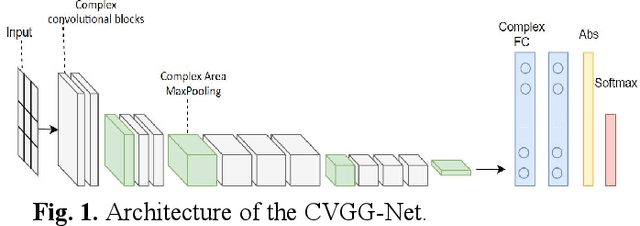
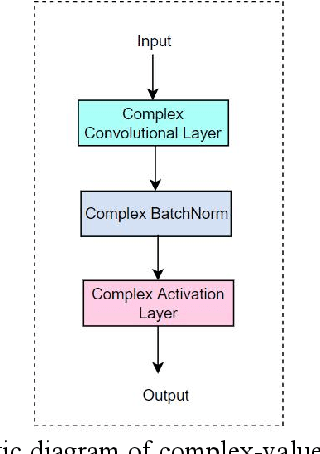
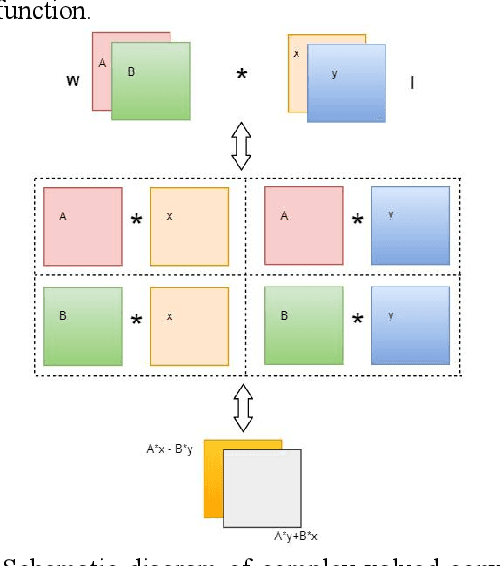
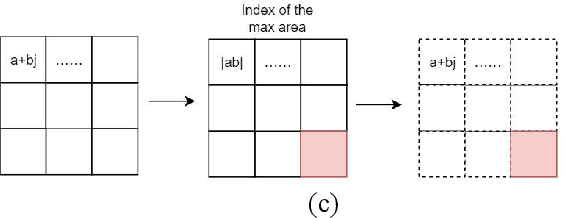
Ship target recognition is a vital task in synthetic aperture radar (SAR) imaging applications. Although convolutional neural networks have been successfully employed for SAR image target recognition, surpassing traditional algorithms, most existing research concentrates on the amplitude domain and neglects the essential phase information. Furthermore, several complex-valued neural networks utilize average pooling to achieve full complex values, resulting in suboptimal performance. To address these concerns, this paper introduces a Complex-valued Convolutional Neural Network (CVGG-Net) specifically designed for SAR image ship recognition. CVGG-Net effectively leverages both the amplitude and phase information in complex-valued SAR data. Additionally, this study examines the impact of various widely-used complex activation functions on network performance and presents a novel complex max-pooling method, called Complex Area Max-Pooling. Experimental results from two measured SAR datasets demonstrate that the proposed algorithm outperforms conventional real-valued convolutional neural networks. The proposed framework is validated on several SAR datasets.
SPHR-SAR-Net: Superpixel High-resolution SAR Imaging Network Based on Nonlocal Total Variation
Apr 10, 2023



High-resolution is a key trend in the development of synthetic aperture radar (SAR), which enables the capture of fine details and accurate representation of backscattering properties. However, traditional high-resolution SAR imaging algorithms face several challenges. Firstly, these algorithms tend to focus on local information, neglecting non-local information between different pixel patches. Secondly, speckle is more pronounced and difficult to filter out in high-resolution SAR images. Thirdly, the process of high-resolution SAR imaging generally involves high time and computational complexity, making real-time imaging difficult to achieve. To address these issues, we propose a Superpixel High-Resolution SAR Imaging Network (SPHR-SAR-Net) for rapid despeckling in high-resolution SAR mode. Based on the concept of superpixel techniques, we initially combine non-convex and non-local total variation as compound regularization. This approach more effectively despeckles and manages the relationship between pixels while reducing bias effects caused by convex constraints. Subsequently, we solve the compound regularization model using the Alternating Direction Method of Multipliers (ADMM) algorithm and unfold it into a Deep Unfolded Network (DUN). The network's parameters are adaptively learned in a data-driven manner, and the learned network significantly increases imaging speed. Additionally, the Deep Unfolded Network is compatible with high-resolution imaging modes such as spotlight, staring spotlight, and sliding spotlight. In this paper, we demonstrate the superiority of SPHR-SAR-Net through experiments in both simulated and real SAR scenarios. The results indicate that SPHR-SAR-Net can rapidly perform high-resolution SAR imaging from raw echo data, producing accurate imaging results.
Efficient Gridless DoA Estimation Method of Non-uniform Linear Arrays with Applications in Automotive Radars
Mar 08, 2023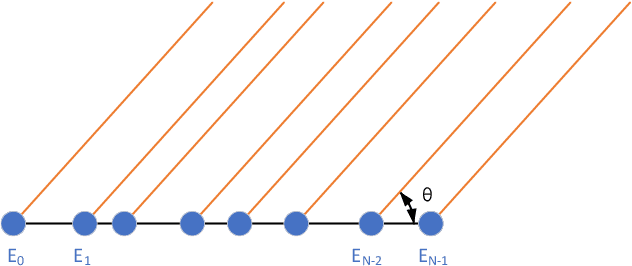
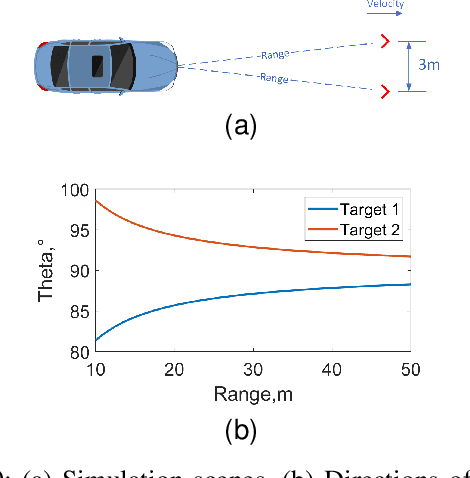
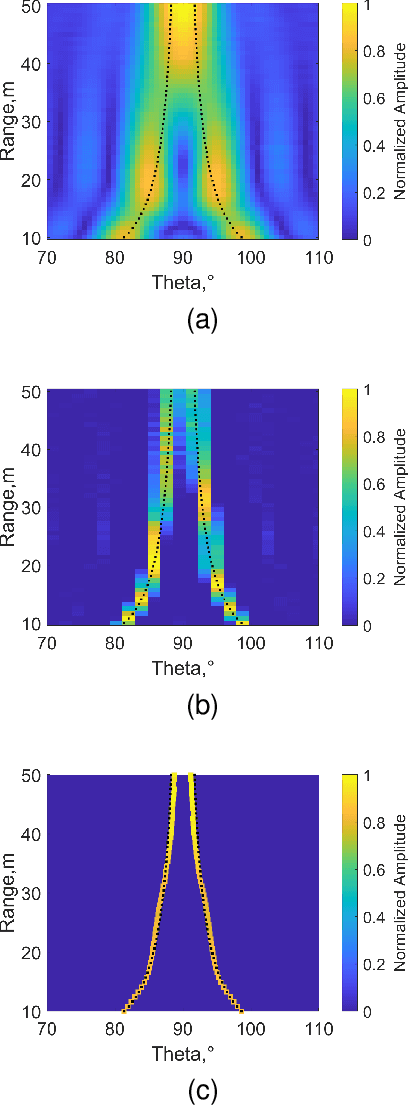

This paper focuses on the gridless direction-of-arrival (DoA) estimation for data acquired by non-uniform linear arrays (NLAs) in automotive applications. Atomic norm minimization (ANM) is a promising gridless sparse recovery algorithm under the Toeplitz model and solved by convex relaxation, thus it is only applicable to uniform linear arrays (ULAs) with array manifolds having a Vandermonde structure. In automotive applications, it is essential to apply the gridless DoA estimation to NLAs with arbitrary geometry with efficiency. In this paper, a fast ANM-based gridless DoA estimation algorithm for NLAs is proposed, which employs the array manifold separation technique and the accelerated proximal gradient (APG) technique, making it applicable to NLAs without losing of efficiency. Simulation and measurement experiments on automotive multiple-input multiple-output (MIMO) radars demonstrate the superiority of the proposed method.
Multi-dimension Geospatial feature learning for urban region function recognition
Jul 18, 2022



Urban region function recognition plays a vital character in monitoring and managing the limited urban areas. Since urban functions are complex and full of social-economic properties, simply using remote sensing~(RS) images equipped with physical and optical information cannot completely solve the classification task. On the other hand, with the development of mobile communication and the internet, the acquisition of geospatial big data~(GBD) becomes possible. In this paper, we propose a Multi-dimension Feature Learning Model~(MDFL) using high-dimensional GBD data in conjunction with RS images for urban region function recognition. When extracting multi-dimension features, our model considers the user-related information modeled by their activity, as well as the region-based information abstracted from the region graph. Furthermore, we propose a decision fusion network that integrates the decisions from several neural networks and machine learning classifiers, and the final decision is made considering both the visual cue from the RS images and the social information from the GBD data. Through quantitative evaluation, we demonstrate that our model achieves overall accuracy at 92.75, outperforming the state-of-the-art by 10 percent.
Gridless Tomographic SAR Imaging Based on Accelerated Atomic Norm Minimization with Efficiency
Apr 26, 2022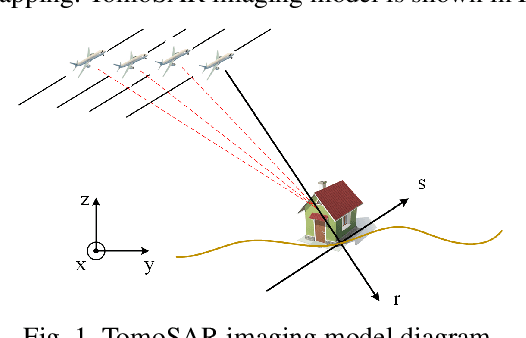

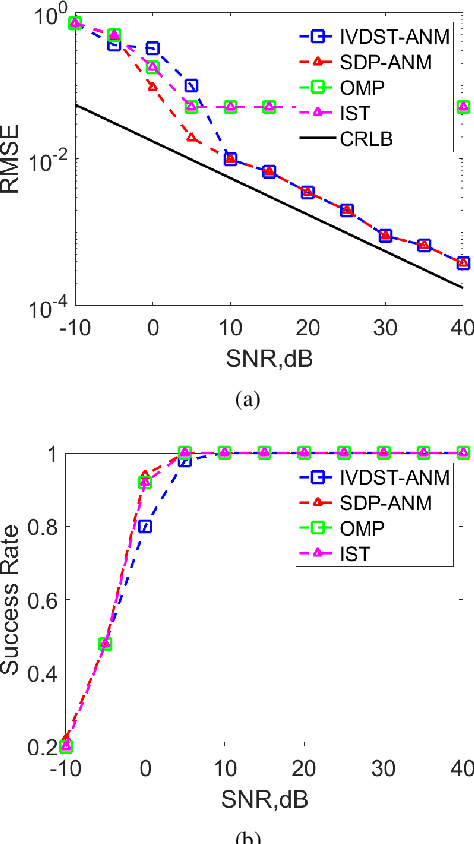
Synthetic aperture radar (SAR) tomography (TomoSAR) enables the reconstruction and three-dimensional (3D) localization of targets based on multiple two-dimensional (2D) observations of the same scene. The resolving along the elevation direction can be treated as a line spectrum estimation problem. However, traditional super-resolution spectrum estimation algorithms require multiple snapshots and uncorrelated targets. Meanwhile, as the most popular TomoSAR imaging method in modern years, compressed sensing (CS) based methods suffer from the gridding mismatch effect which markedly degrades the imaging performance. As a gridless CS approach, atomic norm minimization can avoid the gridding effect but requires enormous computing resources. Addressing the above issues, this paper proposes an improved fast ANM algorithm to TomoSAR elevation focusing by introducing the IVDST-ANM algorithm, which reduces the huge computational complexity of the conventional time-consuming semi-positive definite programming (SDP) by the iterative Vandermonde decomposition and shrinkage-thresholding (IVDST) approach, and retains the benefits of ANM in terms of gridless imaging and single snapshot recovery. We conducted experiments using simulated data to evaluate the performance of the proposed method, and reconstruction results of an urban area from the SARMV3D-Imaging 1.0 dataset are also presented.
The First Airborne Experiment of Sparse Microwave Imaging: Prototype System Design and Result Analysis
Oct 20, 2021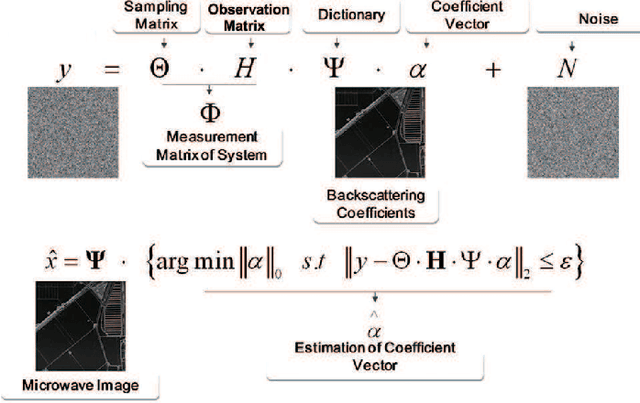
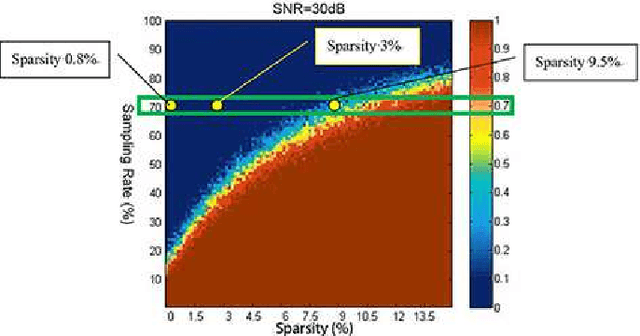


In this paper we report the first airborne experiments of sparse microwave imaging, conducted in September 2013 and May 2014, using our prototype sparse microwave imaging radar system. This is the first reported imaging radar system and airborne experiment that specially designed for sparse microwave imaging. Sparse microwave imaging is a novel concept of radar imaging, it is mainly the combination of traditional radar imaging technology and newly developed sparse signal processing theory, achieving benefits in both improving the imaging quality of current microwave imaging systems and designing optimized sparse microwave imaging radar system to reduce system sampling rate towards the sparse target scenes. During recent years, many researchers focus on related topics of sparse microwave imaging, but rarely few paid attention to prototype system design and experiment. We introduce our prototype sparse microwave imaging radar system, including its system design, hardware considerations and signal processing methods. Several design principles should be considered during the system designing, including the sampling scheme, antenna, SNR, waveform, resolution, etc. We select jittered sampling in azimuth and uniform sampling in range to balance the system complexity and performance. The imaging algorithm is accelerated $\ell_q$ regularization algorithm. To test the prototype radar system and verify the effectiveness of sparse microwave imaging framework, airborne experiments are carried out using our prototype system and we achieve the first sparse microwave image successfully. We analyze the imaging performance of prototype sparse microwave radar system with different sparsities, sampling rates, SNRs and sampling schemes, using three-dimensional phase transit diagram as the evaluation tool.
SAR Image Classification Based on Spiking Neural Network through Spike-Time Dependent Plasticity and Gradient Descent
Jun 15, 2021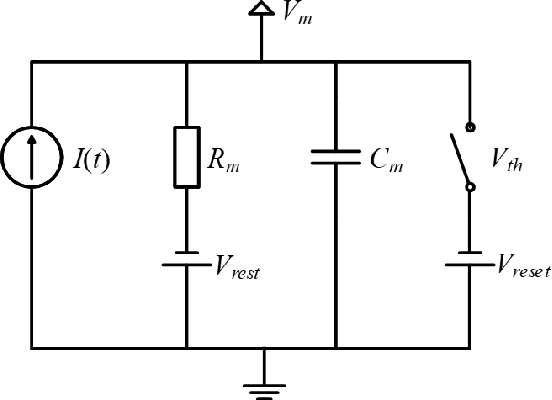


At present, the Synthetic Aperture Radar (SAR) image classification method based on convolution neural network (CNN) has faced some problems such as poor noise resistance and generalization ability. Spiking neural network (SNN) is one of the core components of brain-like intelligence and has good application prospects. This article constructs a complete SAR image classifier based on unsupervised and supervised learning of SNN by using spike sequences with complex spatio-temporal information. We firstly expound the spiking neuron model, the receptive field of SNN, and the construction of spike sequence. Then we put forward an unsupervised learning algorithm based on STDP and a supervised learning algorithm based on gradient descent. The average classification accuracy of single layer and bilayer unsupervised learning SNN in three categories images on MSTAR dataset is 80.8\% and 85.1\%, respectively. Furthermore, the convergent output spike sequences of unsupervised learning can be used as teaching signals. Based on the TensorFlow framework, a single layer supervised learning SNN is built from the bottom, and the classification accuracy reaches 90.05\%. By comparing noise resistance and model parameters between SNNs and CNNs, the effectiveness and outstanding advantages of SNN are verified. Code to reproduce our experiments is available at \url{https://github.com/Jiankun-chen/Supervised-SNN-with-GD}.
High Quality Remote Sensing Image Super-Resolution Using Deep Memory Connected Network
Oct 01, 2020
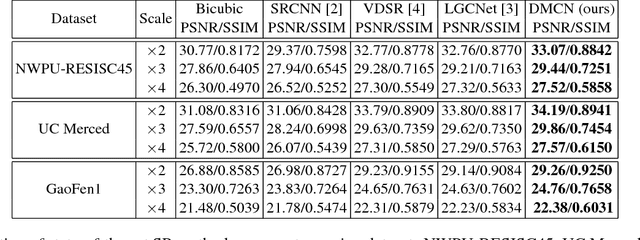


Single image super-resolution is an effective way to enhance the spatial resolution of remote sensing image, which is crucial for many applications such as target detection and image classification. However, existing methods based on the neural network usually have small receptive fields and ignore the image detail. We propose a novel method named deep memory connected network (DMCN) based on a convolutional neural network to reconstruct high-quality super-resolution images. We build local and global memory connections to combine image detail with environmental information. To further reduce parameters and ease time-consuming, we propose downsampling units, shrinking the spatial size of feature maps. We test DMCN on three remote sensing datasets with different spatial resolution. Experimental results indicate that our method yields promising improvements in both accuracy and visual performance over the current state-of-the-art.