 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePursuing the limit of chirp parameter identifiability: A computational approach
Jul 02, 2025In this paper, it is shown that a necessary condition for unique identifiability of $K$ chirps from $N$ regularly spaced samples of their mixture is $N\geq 2K$ when $K\geq 2$. A necessary and sufficient condition is that a rank-constrained matrix optimization problem has a unique solution; this is the first result of such kind. An algorithm is proposed to solve the optimization problem and to identify the parameters numerically. The lower bound of $N=2K$ is shown to be tight by providing diverse problem instances for which the proposed algorithm succeeds to identify the parameters. The advantageous performance of the proposed algorithm is also demonstrated compared with the state of the art.
Applying Neural Monte Carlo Tree Search to Unsignalized Multi-intersection Scheduling for Autonomous Vehicles
Oct 24, 2024



Dynamic scheduling of access to shared resources by autonomous systems is a challenging problem, characterized as being NP-hard. The complexity of this task leads to a combinatorial explosion of possibilities in highly dynamic systems where arriving requests must be continuously scheduled subject to strong safety and time constraints. An example of such a system is an unsignalized intersection, where automated vehicles' access to potential conflict zones must be dynamically scheduled. In this paper, we apply Neural Monte Carlo Tree Search (NMCTS) to the challenging task of scheduling platoons of vehicles crossing unsignalized intersections. Crucially, we introduce a transformation model that maps successive sequences of potentially conflicting road-space reservation requests from platoons of vehicles into a series of board-game-like problems and use NMCTS to search for solutions representing optimal road-space allocation schedules in the context of past allocations. To optimize search, we incorporate a prioritized re-sampling method with parallel NMCTS (PNMCTS) to improve the quality of training data. To optimize training, a curriculum learning strategy is used to train the agent to schedule progressively more complex boards culminating in overlapping boards that represent busy intersections. In a busy single four-way unsignalized intersection simulation, PNMCTS solved 95\% of unseen scenarios, reducing crossing time by 43\% in light and 52\% in heavy traffic versus first-in, first-out control. In a 3x3 multi-intersection network, the proposed method maintained free-flow in light traffic when all intersections are under control of PNMCTS and outperformed state-of-the-art RL-based traffic-light controllers in average travel time by 74.5\% and total throughput by 16\% in heavy traffic.
Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient
Oct 11, 2024



Model-based reinforcement learning (RL) offers a solution to the data inefficiency that plagues most model-free RL algorithms. However, learning a robust world model often demands complex and deep architectures, which are expensive to compute and train. Within the world model, dynamics models are particularly crucial for accurate predictions, and various dynamics-model architectures have been explored, each with its own set of challenges. Currently, recurrent neural network (RNN) based world models face issues such as vanishing gradients and difficulty in capturing long-term dependencies effectively. In contrast, use of transformers suffers from the well-known issues of self-attention mechanisms, where both memory and computational complexity scale as $O(n^2)$, with $n$ representing the sequence length. To address these challenges we propose a state space model (SSM) based world model, specifically based on Mamba, that achieves $O(n)$ memory and computational complexity while effectively capturing long-term dependencies and facilitating the use of longer training sequences efficiently. We also introduce a novel sampling method to mitigate the suboptimality caused by an incorrect world model in the early stages of training, combining it with the aforementioned technique to achieve a normalised score comparable to other state-of-the-art model-based RL algorithms using only a 7 million trainable parameter world model. This model is accessible and can be trained on an off-the-shelf laptop. Our code is available at https://github.com/realwenlongwang/drama.git.
LearnedKV: Integrating LSM and Learned Index for Superior Performance on SSD
Jun 27, 2024



In this paper, we introduce LearnedKV, a novel tiered key-value (KV) store that seamlessly integrates a Log-Structured Merge (LSM) tree with a Learned Index. This integration yields superior read and write performance compared to standalone indexing structures on SSDs. Our design capitalizes on the LSM tree's high write/update throughput and the Learned Index's fast read capabilities, enabling each component to leverage its strengths. We analyze the impact of size on LSM tree performance and demonstrate how the tiered Learned Index significantly mitigates the LSM tree's size-related performance degradation, particularly by reducing the intensive I/O operations resulting from re-insertions after Garbage Collection (GC). To maintain rapid read performance for newly inserted keys, we introduce a non-blocking conversion mechanism that efficiently transforms the existing LSM tree into a new Learned Index with minimal overhead during GC. Our experimental results, conducted across diverse workloads, show that LearnedKV outperforms state-of-the-art solutions by up to 1.32x in read requests and 1.31x in write performance.
Improved impedance inversion by deep learning and iterated graph Laplacian
Apr 25, 2024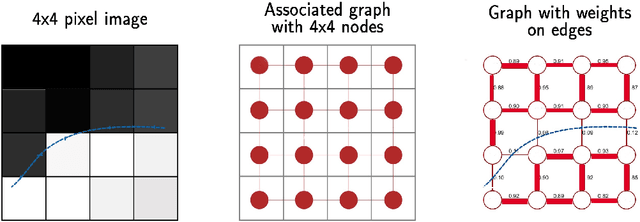
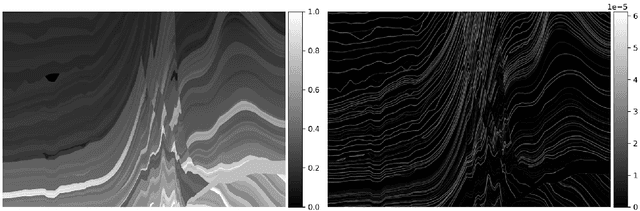
Deep learning techniques have shown significant potential in many applications through recent years. The achieved results often outperform traditional techniques. However, the quality of a neural network highly depends on the used training data. Noisy, insufficient, or biased training data leads to suboptimal results. We present a hybrid method that combines deep learning with iterated graph Laplacian and show its application in acoustic impedance inversion which is a routine procedure in seismic explorations. A neural network is used to obtain a first approximation of the underlying acoustic impedance and construct a graph Laplacian matrix from this approximation. Afterwards, we use a Tikhonov-like variational method to solve the impedance inversion problem where the regularizer is based on the constructed graph Laplacian. The obtained solution can be shown to be more accurate and stable with respect to noise than the initial guess obtained by the neural network. This process can be iterated several times, each time constructing a new graph Laplacian matrix from the most recent reconstruction. The method converges after only a few iterations returning a much more accurate reconstruction. We demonstrate the potential of our method on two different datasets and under various levels of noise. We use two different neural networks that have been introduced in previous works. The experiments show that our approach improves the reconstruction quality in the presence of noise.
A Robust Super-resolution Gridless Imaging Framework for UAV-borne SAR Tomography
Feb 02, 2024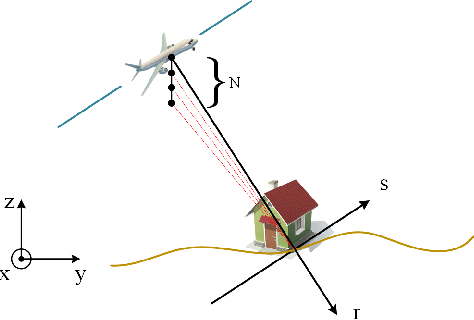
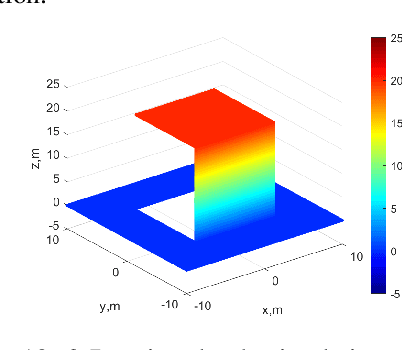
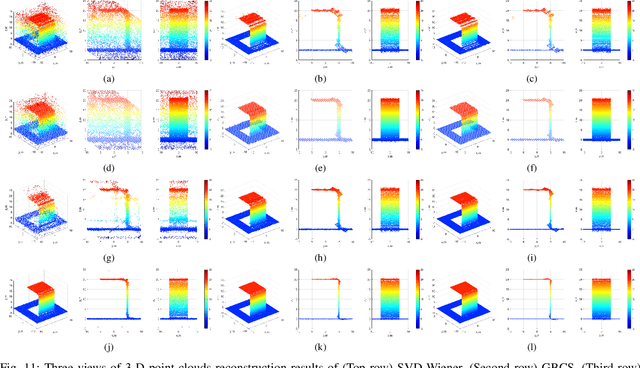
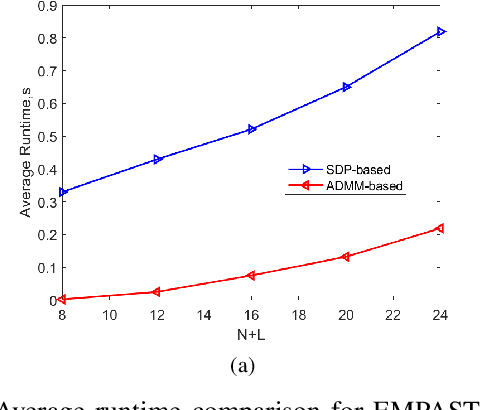
Synthetic aperture radar (SAR) tomography (TomoSAR) retrieves three-dimensional (3-D) information from multiple SAR images, effectively addresses the layover problem, and has become pivotal in urban mapping. Unmanned aerial vehicle (UAV) has gained popularity as a TomoSAR platform, offering distinct advantages such as the ability to achieve 3-D imaging in a single flight, cost-effectiveness, rapid deployment, and flexible trajectory planning. The evolution of compressed sensing (CS) has led to the widespread adoption of sparse reconstruction techniques in TomoSAR signal processing, with a focus on $\ell _1$ norm regularization and other grid-based CS methods. However, the discretization of illuminated scene along elevation introduces modeling errors, resulting in reduced reconstruction accuracy, known as the "off-grid" effect. Recent advancements have introduced gridless CS algorithms to mitigate this issue. This paper presents an innovative gridless 3-D imaging framework tailored for UAV-borne TomoSAR. Capitalizing on the pulse repetition frequency (PRF) redundancy inherent in slow UAV platforms, a multiple measurement vectors (MMV) model is constructed to enhance noise immunity without compromising azimuth-range resolution. Given the sparsely placed array elements due to mounting platform constraints, an atomic norm soft thresholding algorithm is proposed for partially observed MMV, offering gridless reconstruction capability and super-resolution. An efficient alternative optimization algorithm is also employed to enhance computational efficiency. Validation of the proposed framework is achieved through computer simulations and flight experiments, affirming its efficacy in UAV-borne TomoSAR applications.
Semi-supervised Impedance Inversion by Bayesian Neural Network Based on 2-d CNN Pre-training
Nov 20, 2021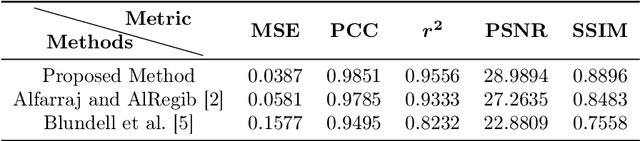
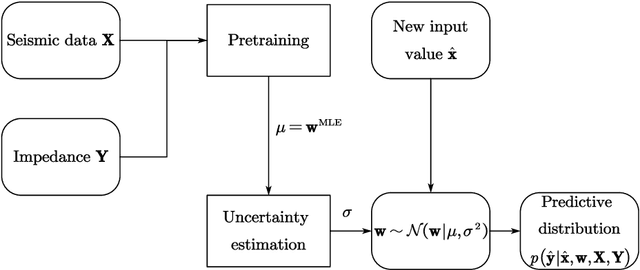

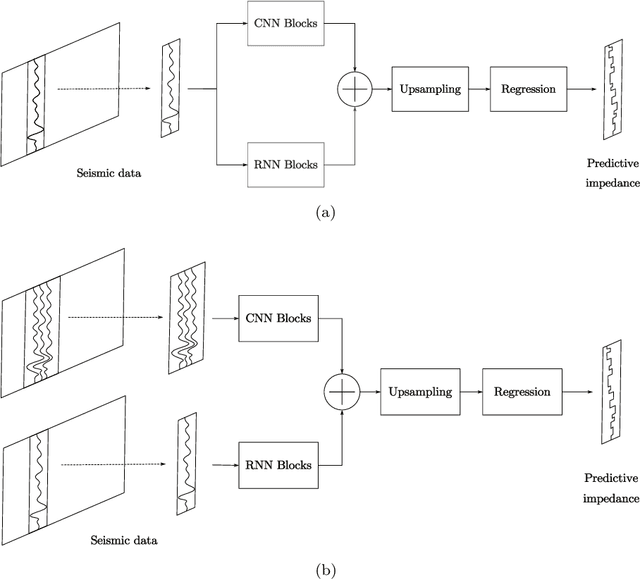
Seismic impedance inversion can be performed with a semi-supervised learning algorithm, which only needs a few logs as labels and is less likely to get overfitted. However, classical semi-supervised learning algorithm usually leads to artifacts on the predicted impedance image. In this artical, we improve the semi-supervised learning from two aspects. First, by replacing 1-d convolutional neural network (CNN) layers in deep learning structure with 2-d CNN layers and 2-d maxpooling layers, the prediction accuracy is improved. Second, prediction uncertainty can also be estimated by embedding the network into a Bayesian inference framework. Local reparameterization trick is used during forward propagation of the network to reduce sampling cost. Tests with Marmousi2 model and SEAM model validate the feasibility of the proposed strategy.
Deep learning tutorial for denoising
Oct 27, 2018
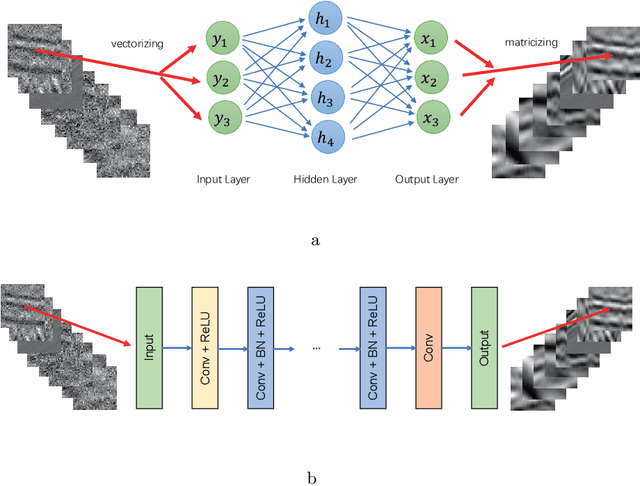
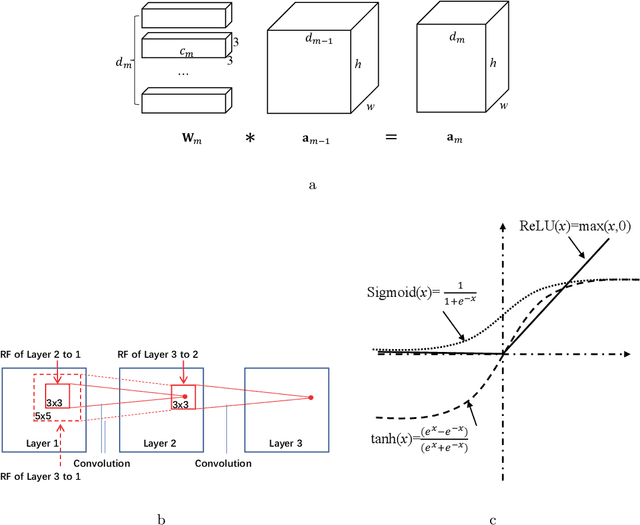
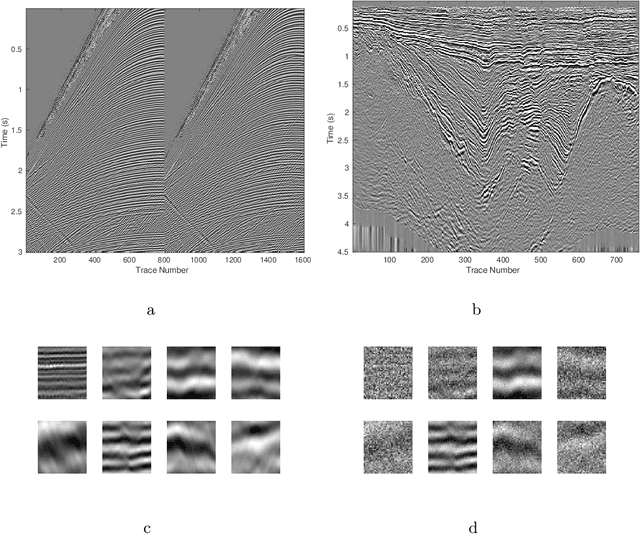
We herein introduce deep learning to seismic noise attenuation. Compared with traditional seismic noise attenuation algorithms that depend on signal models and their corresponding prior assumptions, a deep neural network is trained based on a large training set, where the inputs are the raw datasets and the corresponding outputs are the desired clean data. After the completion of training, the deep learning method achieves adaptive denoising with no requirements of (i) accurate modeling of the signal and noise, and (ii) optimal parameters tuning. We call this intelligent denoising. We use a convolutional neural network as the basic tool for deep learning. The training set is generated with manually added noise in random and linear noise attenuation, and with the wave equation in the multiple attenuation. Stochastic gradient descent is used to solve the optimal parameters for the convolutional neural network. The runtime of deep learning on a graphics processing unit for denoising has the same order as the $f-x$ deconvolutional method. Synthetic and field results show the potential applications of deep learning in the automation of random noise attenuation with unknown variance, linear noise, and multiples.