 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolSAM: Polarimetric Scattering Mechanism Informed Segment Anything Model
Dec 17, 2024PolSAR data presents unique challenges due to its rich and complex characteristics. Existing data representations, such as complex-valued data, polarimetric features, and amplitude images, are widely used. However, these formats often face issues related to usability, interpretability, and data integrity. Most feature extraction networks for PolSAR are small, limiting their ability to capture features effectively. To address these issues, We propose the Polarimetric Scattering Mechanism-Informed SAM (PolSAM), an enhanced Segment Anything Model (SAM) that integrates domain-specific scattering characteristics and a novel prompt generation strategy. PolSAM introduces Microwave Vision Data (MVD), a lightweight and interpretable data representation derived from polarimetric decomposition and semantic correlations. We propose two key components: the Feature-Level Fusion Prompt (FFP), which fuses visual tokens from pseudo-colored SAR images and MVD to address modality incompatibility in the frozen SAM encoder, and the Semantic-Level Fusion Prompt (SFP), which refines sparse and dense segmentation prompts using semantic information. Experimental results on the PhySAR-Seg datasets demonstrate that PolSAM significantly outperforms existing SAM-based and multimodal fusion models, improving segmentation accuracy, reducing data storage, and accelerating inference time. The source code and datasets will be made publicly available at \url{https://github.com/XAI4SAR/PolSAM}.
Skeleton Supervised Airway Segmentation
Mar 11, 2024



Fully-supervised airway segmentation has accomplished significant triumphs over the years in aiding pre-operative diagnosis and intra-operative navigation. However, full voxel-level annotation constitutes a labor-intensive and time-consuming task, often plagued by issues such as missing branches, branch annotation discontinuity, or erroneous edge delineation. label-efficient solutions for airway extraction are rarely explored yet primarily demanding in medical practice. To this end, we introduce a novel skeleton-level annotation (SkA) tailored to the airway, which simplifies the annotation workflow while enhancing annotation consistency and accuracy, preserving the complete topology. Furthermore, we propose a skeleton-supervised learning framework to achieve accurate airway segmentation. Firstly, a dual-stream buffer inference is introduced to realize initial label propagation from SkA, avoiding the collapse of direct learning from SkA. Then, we construct a geometry-aware dual-path propagation framework (GDP) to further promote complementary propagation learning, composed of hard geometry-aware propagation learning and soft geometry-aware propagation guidance. Experiments reveal that our proposed framework outperforms the competing methods with SKA, which amounts to only 1.96% airways, and achieves comparable performance with the baseline model that is fully supervised with 100% airways, demonstrating its significant potential in achieving label-efficient segmentation for other tubular structures, such as vessels.
A Robust Super-resolution Gridless Imaging Framework for UAV-borne SAR Tomography
Feb 02, 2024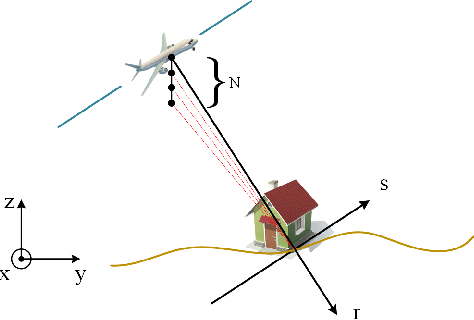
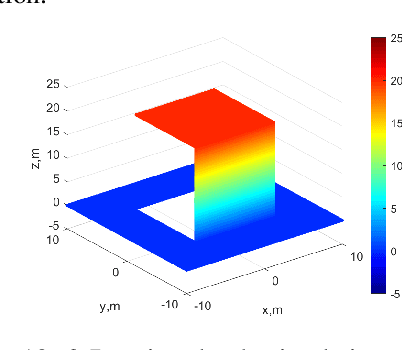
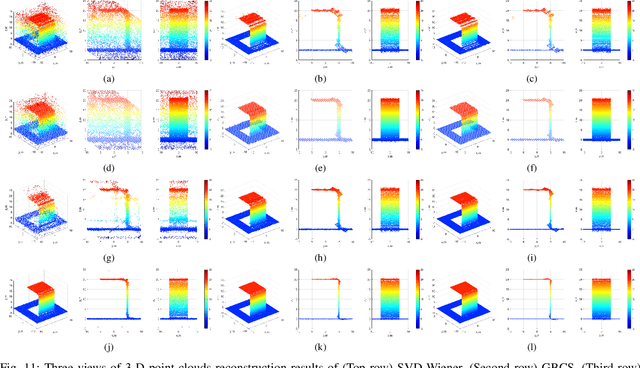
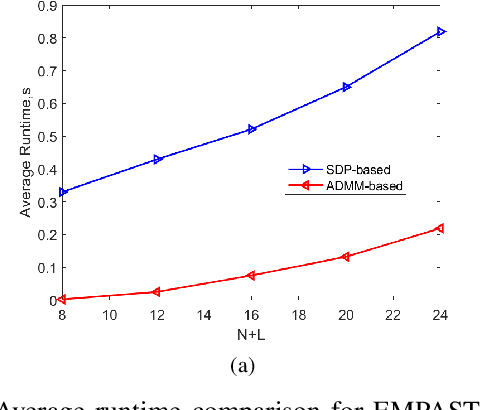
Synthetic aperture radar (SAR) tomography (TomoSAR) retrieves three-dimensional (3-D) information from multiple SAR images, effectively addresses the layover problem, and has become pivotal in urban mapping. Unmanned aerial vehicle (UAV) has gained popularity as a TomoSAR platform, offering distinct advantages such as the ability to achieve 3-D imaging in a single flight, cost-effectiveness, rapid deployment, and flexible trajectory planning. The evolution of compressed sensing (CS) has led to the widespread adoption of sparse reconstruction techniques in TomoSAR signal processing, with a focus on $\ell _1$ norm regularization and other grid-based CS methods. However, the discretization of illuminated scene along elevation introduces modeling errors, resulting in reduced reconstruction accuracy, known as the "off-grid" effect. Recent advancements have introduced gridless CS algorithms to mitigate this issue. This paper presents an innovative gridless 3-D imaging framework tailored for UAV-borne TomoSAR. Capitalizing on the pulse repetition frequency (PRF) redundancy inherent in slow UAV platforms, a multiple measurement vectors (MMV) model is constructed to enhance noise immunity without compromising azimuth-range resolution. Given the sparsely placed array elements due to mounting platform constraints, an atomic norm soft thresholding algorithm is proposed for partially observed MMV, offering gridless reconstruction capability and super-resolution. An efficient alternative optimization algorithm is also employed to enhance computational efficiency. Validation of the proposed framework is achieved through computer simulations and flight experiments, affirming its efficacy in UAV-borne TomoSAR applications.
Conceptual Study and Performance Analysis of Tandem Dual-Antenna Spaceborne SAR Interferometry
Jun 17, 2023Multi-baseline synthetic aperture radar interferometry (MB-InSAR), capable of mapping 3D surface model with high precision, is able to overcome the ill-posed problem in the single-baseline InSAR by use of the baseline diversity. Single pass MB acquisition with the advantages of high coherence and simple phase components has a more practical capability in 3D reconstruction than conventional repeat-pass MB acquisition. Using an asymptotic 3D phase unwrapping (PU), it is possible to get a reliable 3D reconstruction using very sparse acquisitions but the interferograms should follow the optimal baseline design. However, current spaceborne SAR system doesn't satisfy this principle, inducing more difficulties in practical application. In this article, a new concept of Tandem Dual-Antenna SAR Interferometry (TDA-InSAR) system for single-pass reliable 3D surface mapping using the asymptotic 3D PU is proposed. Its optimal MB acquisition is analyzed to achieve both good relative height precision and flexible baseline design. Two indicators, i.e., expected relative height precision and successful phase unwrapping rate, are selected to optimize the system parameters and evaluate the performance of various baseline configurations. Additionally, simulation-based demonstrations are conducted to evaluate the performance in typical scenarios and investigate the impact of various error sources. The results indicate that the proposed TDA-InSAR is able to get the specified MB acquisition for the asymptotic 3D PU, which offers a feasible solution for single-pass 3D SAR imaging.
CVGG-Net: Ship Recognition for SAR Images Based on Complex-Valued Convolutional Neural Network
May 13, 2023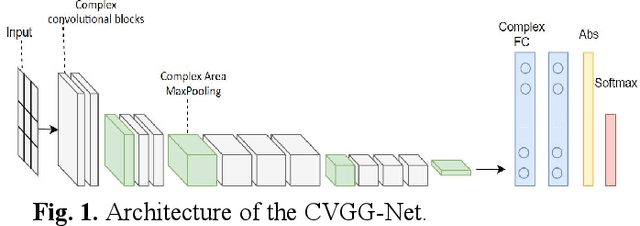
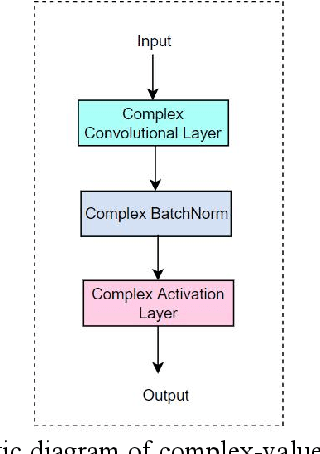
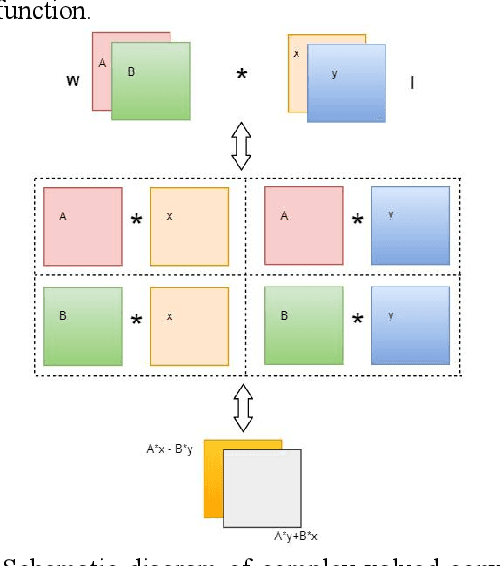
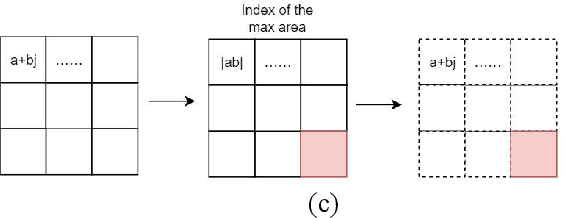
Ship target recognition is a vital task in synthetic aperture radar (SAR) imaging applications. Although convolutional neural networks have been successfully employed for SAR image target recognition, surpassing traditional algorithms, most existing research concentrates on the amplitude domain and neglects the essential phase information. Furthermore, several complex-valued neural networks utilize average pooling to achieve full complex values, resulting in suboptimal performance. To address these concerns, this paper introduces a Complex-valued Convolutional Neural Network (CVGG-Net) specifically designed for SAR image ship recognition. CVGG-Net effectively leverages both the amplitude and phase information in complex-valued SAR data. Additionally, this study examines the impact of various widely-used complex activation functions on network performance and presents a novel complex max-pooling method, called Complex Area Max-Pooling. Experimental results from two measured SAR datasets demonstrate that the proposed algorithm outperforms conventional real-valued convolutional neural networks. The proposed framework is validated on several SAR datasets.
SPHR-SAR-Net: Superpixel High-resolution SAR Imaging Network Based on Nonlocal Total Variation
Apr 10, 2023



High-resolution is a key trend in the development of synthetic aperture radar (SAR), which enables the capture of fine details and accurate representation of backscattering properties. However, traditional high-resolution SAR imaging algorithms face several challenges. Firstly, these algorithms tend to focus on local information, neglecting non-local information between different pixel patches. Secondly, speckle is more pronounced and difficult to filter out in high-resolution SAR images. Thirdly, the process of high-resolution SAR imaging generally involves high time and computational complexity, making real-time imaging difficult to achieve. To address these issues, we propose a Superpixel High-Resolution SAR Imaging Network (SPHR-SAR-Net) for rapid despeckling in high-resolution SAR mode. Based on the concept of superpixel techniques, we initially combine non-convex and non-local total variation as compound regularization. This approach more effectively despeckles and manages the relationship between pixels while reducing bias effects caused by convex constraints. Subsequently, we solve the compound regularization model using the Alternating Direction Method of Multipliers (ADMM) algorithm and unfold it into a Deep Unfolded Network (DUN). The network's parameters are adaptively learned in a data-driven manner, and the learned network significantly increases imaging speed. Additionally, the Deep Unfolded Network is compatible with high-resolution imaging modes such as spotlight, staring spotlight, and sliding spotlight. In this paper, we demonstrate the superiority of SPHR-SAR-Net through experiments in both simulated and real SAR scenarios. The results indicate that SPHR-SAR-Net can rapidly perform high-resolution SAR imaging from raw echo data, producing accurate imaging results.
MF-JMoDL-Net: A Deep Network for Azimuth Undersampling Pattern Design and Ambiguity Suppression for Sparse SAR Imaging
Mar 20, 2023



repetition frequency (PRF). Given the system complexity and resource constraints, it is often difficult to achieve high imaging performance and low ambiguity without compromising the swath. In this paper, we propose a joint optimization framework for sparse strip SAR imaging algorithms and azimuth undersampling patterns based on a deep convolutional neural network, combined with matched filter (MF) approximate measurement operators and inverse MF operators, referred to as MF-JMoDL-Net, for sparse SAR imaging methods. Compared with conventional sparse SAR imaging, MF-JMoDL-Net enables us to alleviate the limitations imposed by PRF. In the proposed scheme, joint and continuous optimization of azimuth undersampling patterns and convolutional neural network parameters are implemented to suppress azimuth ambiguity and enhance sparse SAR imaging quality. Experiments and comparisons under various conditions demonstrate the effectiveness and superiority of the proposed framework in imaging results.
GDDS: Pulmonary Bronchioles Segmentation with Group Deep Dense Supervision
Mar 16, 2023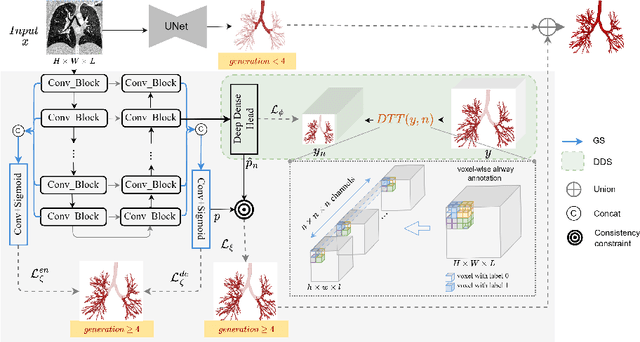
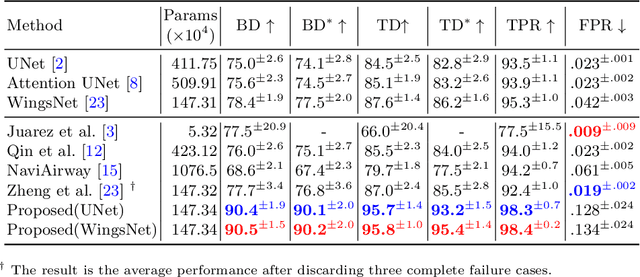

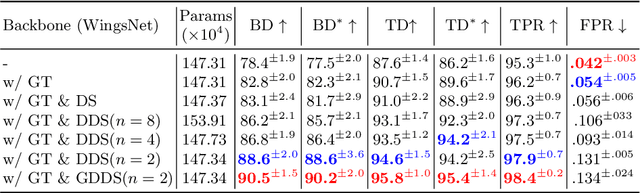
Airway segmentation, especially bronchioles segmentation, is an important but challenging task because distal bronchus are sparsely distributed and of a fine scale. Existing neural networks usually exploit sparse topology to learn the connectivity of bronchioles and inefficient shallow features to capture such high-frequency information, leading to the breakage or missed detection of individual thin branches. To address these problems, we contribute a new bronchial segmentation method based on Group Deep Dense Supervision (GDDS) that emphasizes fine-scale bronchioles segmentation in a simple-but-effective manner. First, Deep Dense Supervision (DDS) is proposed by constructing local dense topology skillfully and implementing dense topological learning on a specific shallow feature layer. GDDS further empowers the shallow features with better perception ability to detect bronchioles, even the ones that are not easily discernible to the naked eye. Extensive experiments on the BAS benchmark dataset have shown that our method promotes the network to have a high sensitivity in capturing fine-scale branches and outperforms state-of-the-art methods by a large margin (+12.8 % in BD and +8.8 % in TD) while only introducing a small number of extra parameters.
ATASI-Net: An Efficient Sparse Reconstruction Network for Tomographic SAR Imaging with Adaptive Threshold
Nov 30, 2022



Tomographic SAR technique has attracted remarkable interest for its ability of three-dimensional resolving along the elevation direction via a stack of SAR images collected from different cross-track angles. The emerged compressed sensing (CS)-based algorithms have been introduced into TomoSAR considering its super-resolution ability with limited samples. However, the conventional CS-based methods suffer from several drawbacks, including weak noise resistance, high computational complexity, and complex parameter fine-tuning. Aiming at efficient TomoSAR imaging, this paper proposes a novel efficient sparse unfolding network based on the analytic learned iterative shrinkage thresholding algorithm (ALISTA) architecture with adaptive threshold, named Adaptive Threshold ALISTA-based Sparse Imaging Network (ATASI-Net). The weight matrix in each layer of ATASI-Net is pre-computed as the solution of an off-line optimization problem, leaving only two scalar parameters to be learned from data, which significantly simplifies the training stage. In addition, adaptive threshold is introduced for each azimuth-range pixel, enabling the threshold shrinkage to be not only layer-varied but also element-wise. Moreover, the final learned thresholds can be visualized and combined with the SAR image semantics for mutual feedback. Finally, extensive experiments on simulated and real data are carried out to demonstrate the effectiveness and efficiency of the proposed method.
TomoSAR-ALISTA: Efficient TomoSAR Imaging via Deep Unfolded Network
May 05, 2022

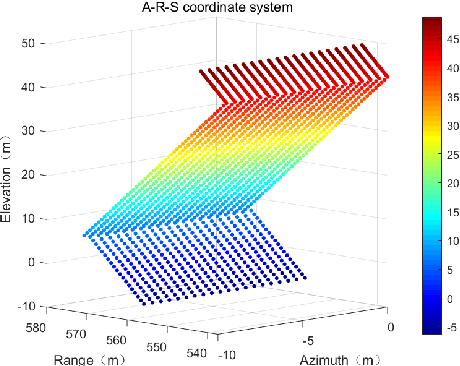
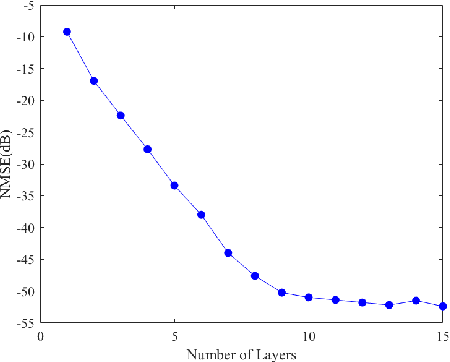
Synthetic aperture radar (SAR) tomography (TomoSAR) has attracted remarkable interest for its ability in achieving three-dimensional reconstruction along the elevation direction from multiple observations. In recent years, compressed sensing (CS) technique has been introduced into TomoSAR considering for its super-resolution ability with limited samples. Whereas, the CS-based methods suffer from several drawbacks, including weak noise resistance, high computational complexity and complex parameter fine-tuning. Among the different CS algorithms, iterative soft-thresholding algorithm (ISTA) is widely used as a robust reconstruction approach, however, the parameters in the ISTA algorithm are manually chosen, which usually requires a time-consuming fine-tuning process to achieve the best performance. Aiming at efficient TomoSAR imaging, a novel sparse unfolding network named analytic learned ISTA (ALISTA) is proposed towards the TomoSAR imaging problem in this paper, and the key parameters of ISTA are learned from training data via deep learning to avoid complex parameter fine-tuning and significantly relieves the training burden. In addition, experiments verify that it is feasible to use traditional CS algorithms as training labels, which provides a tangible supervised training method to achieve better 3D reconstruction performance even in the absence of labeled data in real applications.