 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxEffects: A Speech-Oriented Audio Effects Dataset and Benchmark
Apr 14, 2026Speech audio in the wild is often processed by post-production effects, but existing speech datasets rarely provide precise annotations of effects and parameters, limiting systematic study. We introduce VoxEffects, a speech audio effects dataset that pairs produced speech with exact effect-chain supervision at multiple granularities. VoxEffects supports speech-oriented audio effect identification: given a produced waveform, infer which effects are present and how they are applied. Built from minimally edited clean speech, it provides an extensible rendering pipeline for both offline synthesis and on-the-fly rendering for efficient training and evaluation. The audio effect identification benchmark includes effect presence detection, preset classification, and intensity prediction, with a robustness protocol covering capture-side and platform-side degradations. We provide an AudioMAE-based multi-task baseline and analyses of domain shift, robustness, input duration, and gender fairness.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
Dual-Teacher Distillation with Subnetwork Rectification for Black-Box Domain Adaptation
Mar 25, 2026Assuming that neither source data nor the source model is accessible, black box domain adaptation represents a highly practical yet extremely challenging setting, as transferable information is restricted to the predictions of the black box source model, which can only be queried using target samples. Existing approaches attempt to extract transferable knowledge through pseudo label refinement or by leveraging external vision language models (ViLs), but they often suffer from noisy supervision or insufficient utilization of the semantic priors provided by ViLs, which ultimately hinder adaptation performance. To overcome these limitations, we propose a dual teacher distillation with subnetwork rectification (DDSR) model that jointly exploits the specific knowledge embedded in black box source models and the general semantic information of a ViL. DDSR adaptively integrates their complementary predictions to generate reliable pseudo labels for the target domain and introduces a subnetwork driven regularization strategy to mitigate overfitting caused by noisy supervision. Furthermore, the refined target predictions iteratively enhance both the pseudo labels and ViL prompts, enabling more accurate and semantically consistent adaptation. Finally, the target model is further optimized through self training with classwise prototypes. Extensive experiments on multiple benchmark datasets validate the effectiveness of our approach, demonstrating consistent improvements over state of the art methods, including those using source data or models.
RAID: Retrieval-Augmented Anomaly Detection
Feb 23, 2026Unsupervised Anomaly Detection (UAD) aims to identify abnormal regions by establishing correspondences between test images and normal templates. Existing methods primarily rely on image reconstruction or template retrieval but face a fundamental challenge: matching between test images and normal templates inevitably introduces noise due to intra-class variations, imperfect correspondences, and limited templates. Observing that Retrieval-Augmented Generation (RAG) leverages retrieved samples directly in the generation process, we reinterpret UAD through this lens and introduce \textbf{RAID}, a retrieval-augmented UAD framework designed for noise-resilient anomaly detection and localization. Unlike standard RAG that enriches context or knowledge, we focus on using retrieved normal samples to guide noise suppression in anomaly map generation. RAID retrieves class-, semantic-, and instance-level representations from a hierarchical vector database, forming a coarse-to-fine pipeline. A matching cost volume correlates the input with retrieved exemplars, followed by a guided Mixture-of-Experts (MoE) network that leverages the retrieved samples to adaptively suppress matching noise and produce fine-grained anomaly maps. RAID achieves state-of-the-art performance across full-shot, few-shot, and multi-dataset settings on MVTec, VisA, MPDD, and BTAD benchmarks. \href{https://github.com/Mingxiu-Cai/RAID}{https://github.com/Mingxiu-Cai/RAID}.
SAGE: Scalable AI Governance & Evaluation
Feb 08, 2026Evaluating relevance in large-scale search systems is fundamentally constrained by the governance gap between nuanced, resource-constrained human oversight and the high-throughput requirements of production systems. While traditional approaches rely on engagement proxies or sparse manual review, these methods often fail to capture the full scope of high-impact relevance failures. We present \textbf{SAGE} (Scalable AI Governance \& Evaluation), a framework that operationalizes high-quality human product judgment as a scalable evaluation signal. At the core of SAGE is a bidirectional calibration loop where natural-language \emph{Policy}, curated \emph{Precedent}, and an \emph{LLM Surrogate Judge} co-evolve. SAGE systematically resolves semantic ambiguities and misalignments, transforming subjective relevance judgment into an executable, multi-dimensional rubric with near human-level agreement. To bridge the gap between frontier model reasoning and industrial-scale inference, we apply teacher-student distillation to transfer high-fidelity judgments into compact student surrogates at \textbf{92$\times$} lower cost. Deployed within LinkedIn Search ecosystems, SAGE guided model iteration through simulation-driven development, distilling policy-aligned models for online serving and enabling rapid offline evaluation. In production, it powered policy oversight that measured ramped model variants and detected regressions invisible to engagement metrics. Collectively, these drove a \textbf{0.25\%} lift in LinkedIn daily active users.
Decoupling Variance and Scale-Invariant Updates in Adaptive Gradient Descent for Unified Vector and Matrix Optimization
Feb 06, 2026Adaptive methods like Adam have become the $\textit{de facto}$ standard for large-scale vector and Euclidean optimization due to their coordinate-wise adaptation with a second-order nature. More recently, matrix-based spectral optimizers like Muon (Jordan et al., 2024b) show the power of treating weight matrices as matrices rather than long vectors. Linking these is hard because many natural generalizations are not feasible to implement, and we also cannot simply move the Adam adaptation to the matrix spectrum. To address this, we reformulate the AdaGrad update and decompose it into a variance adaptation term and a scale-invariant term. This decoupling produces $\textbf{DeVA}$ ($\textbf{De}$coupled $\textbf{V}$ariance $\textbf{A}$daptation), a framework that bridges between vector-based variance adaptation and matrix spectral optimization, enabling a seamless transition from Adam to adaptive spectral descent. Extensive experiments across language modeling and image classification demonstrate that DeVA consistently outperforms state-of-the-art methods such as Muon and SOAP (Vyas et al., 2024), reducing token usage by around 6.6\%. Theoretically, we show that the variance adaptation term effectively improves the blockwise smoothness, facilitating faster convergence. Our implementation is available at https://github.com/Tsedao/Decoupled-Variance-Adaptation
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Self Voice Conversion as an Attack against Neural Audio Watermarking
Jan 28, 2026Audio watermarking embeds auxiliary information into speech while maintaining speaker identity, linguistic content, and perceptual quality. Although recent advances in neural and digital signal processing-based watermarking methods have improved imperceptibility and embedding capacity, robustness is still primarily assessed against conventional distortions such as compression, additive noise, and resampling. However, the rise of deep learning-based attacks introduces novel and significant threats to watermark security. In this work, we investigate self voice conversion as a universal, content-preserving attack against audio watermarking systems. Self voice conversion remaps a speaker's voice to the same identity while altering acoustic characteristics through a voice conversion model. We demonstrate that this attack severely degrades the reliability of state-of-the-art watermarking approaches and highlight its implications for the security of modern audio watermarking techniques.
Pitch-Conditioned Instrument Sound Synthesis From an Interactive Timbre Latent Space
Oct 05, 2025



This paper presents a novel approach to neural instrument sound synthesis using a two-stage semi-supervised learning framework capable of generating pitch-accurate, high-quality music samples from an expressive timbre latent space. Existing approaches that achieve sufficient quality for music production often rely on high-dimensional latent representations that are difficult to navigate and provide unintuitive user experiences. We address this limitation through a two-stage training paradigm: first, we train a pitch-timbre disentangled 2D representation of audio samples using a Variational Autoencoder; second, we use this representation as conditioning input for a Transformer-based generative model. The learned 2D latent space serves as an intuitive interface for navigating and exploring the sound landscape. We demonstrate that the proposed method effectively learns a disentangled timbre space, enabling expressive and controllable audio generation with reliable pitch conditioning. Experimental results show the model's ability to capture subtle variations in timbre while maintaining a high degree of pitch accuracy. The usability of our method is demonstrated in an interactive web application, highlighting its potential as a step towards future music production environments that are both intuitive and creatively empowering: https://pgesam.faresschulz.com
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

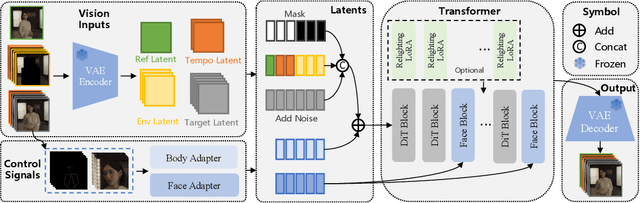
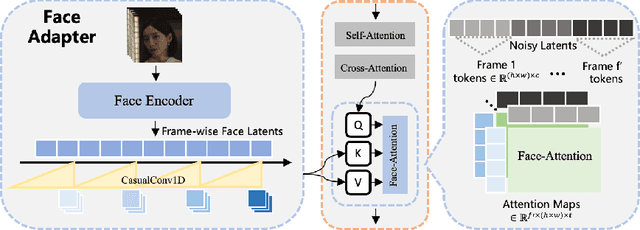
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.