 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAR: Learning Edge-Aware Representations for Event-to-LiDAR Localization
Mar 02, 2026Event cameras offer high-temporal-resolution sensing that remains reliable under high-speed motion and challenging lighting, making them promising for localization from LiDAR point clouds in GPS-denied and visually degraded environments. However, aligning sparse, asynchronous events with dense LiDAR maps is fundamentally ill-posed, as direct correspondence estimation suffers from modality gaps. We propose LEAR, a dual-task learning framework that jointly estimates edge structures and dense event-depth flow fields to bridge the sensing-modality divide. Instead of treating edges as a post-hoc aid, LEAR couples them with flow estimation through a cross-modal fusion mechanism that injects modality-invariant geometric cues into the motion representation, and an iterative refinement strategy that enforces mutual consistency between the two tasks over multiple update steps. This synergy produces edge-aware, depth-aligned flow fields that enable more robust and accurate pose recovery via Perspective-n-Point (PnP) solvers. On several popular and challenging datasets, LEAR achieves superior performance over the best prior method. The source code, trained models, and demo videos are made publicly available online.
${C}^{3}$-GS: Learning Context-aware, Cross-dimension, Cross-scale Feature for Generalizable Gaussian Splatting
Aug 28, 2025



Generalizable Gaussian Splatting aims to synthesize novel views for unseen scenes without per-scene optimization. In particular, recent advancements utilize feed-forward networks to predict per-pixel Gaussian parameters, enabling high-quality synthesis from sparse input views. However, existing approaches fall short in encoding discriminative, multi-view consistent features for Gaussian predictions, which struggle to construct accurate geometry with sparse views. To address this, we propose $\mathbf{C}^{3}$-GS, a framework that enhances feature learning by incorporating context-aware, cross-dimension, and cross-scale constraints. Our architecture integrates three lightweight modules into a unified rendering pipeline, improving feature fusion and enabling photorealistic synthesis without requiring additional supervision. Extensive experiments on benchmark datasets validate that $\mathbf{C}^{3}$-GS achieves state-of-the-art rendering quality and generalization ability. Code is available at: https://github.com/YuhsiHu/C3-GS.
ICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
Mar 27, 2025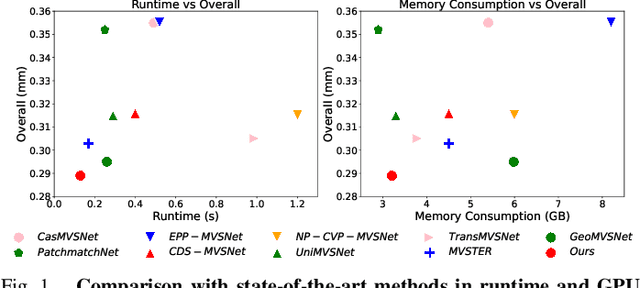
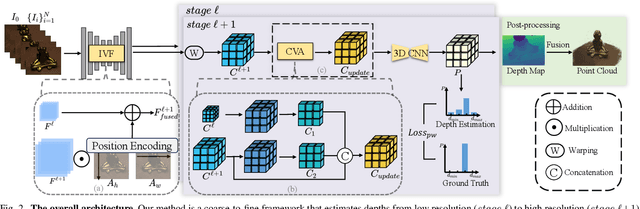
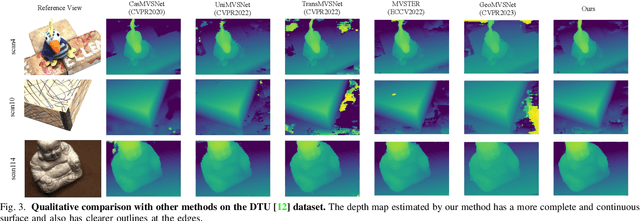

Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.
PACA: Perspective-Aware Cross-Attention Representation for Zero-Shot Scene Rearrangement
Oct 29, 2024



Scene rearrangement, like table tidying, is a challenging task in robotic manipulation due to the complexity of predicting diverse object arrangements. Web-scale trained generative models such as Stable Diffusion can aid by generating natural scenes as goals. To facilitate robot execution, object-level representations must be extracted to match the real scenes with the generated goals and to calculate object pose transformations. Current methods typically use a multi-step design that involves separate models for generation, segmentation, and feature encoding, which can lead to a low success rate due to error accumulation. Furthermore, they lack control over the viewing perspectives of the generated goals, restricting the tasks to 3-DoF settings. In this paper, we propose PACA, a zero-shot pipeline for scene rearrangement that leverages perspective-aware cross-attention representation derived from Stable Diffusion. Specifically, we develop a representation that integrates generation, segmentation, and feature encoding into a single step to produce object-level representations. Additionally, we introduce perspective control, thus enabling the matching of 6-DoF camera views and extending past approaches that were limited to 3-DoF top-down views. The efficacy of our method is demonstrated through its zero-shot performance in real robot experiments across various scenes, achieving an average matching accuracy and execution success rate of 87% and 67%, respectively.
FE-DeTr: Keypoint Detection and Tracking in Low-quality Image Frames with Events
Mar 18, 2024


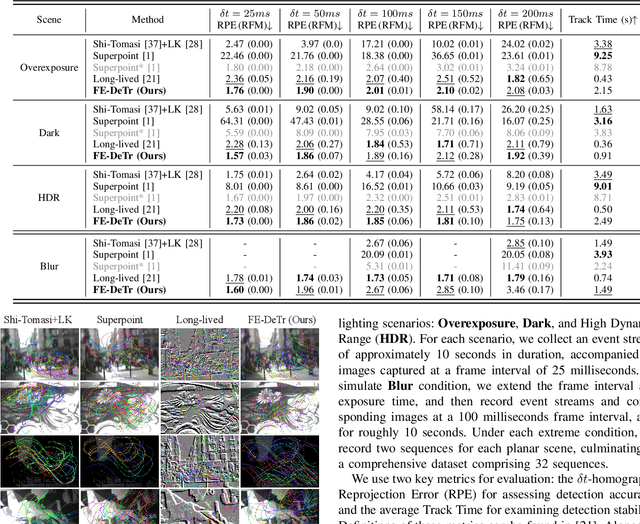
Keypoint detection and tracking in traditional image frames are often compromised by image quality issues such as motion blur and extreme lighting conditions. Event cameras offer potential solutions to these challenges by virtue of their high temporal resolution and high dynamic range. However, they have limited performance in practical applications due to their inherent noise in event data. This paper advocates fusing the complementary information from image frames and event streams to achieve more robust keypoint detection and tracking. Specifically, we propose a novel keypoint detection network that fuses the textural and structural information from image frames with the high-temporal-resolution motion information from event streams, namely FE-DeTr. The network leverages a temporal response consistency for supervision, ensuring stable and efficient keypoint detection. Moreover, we use a spatio-temporal nearest-neighbor search strategy for robust keypoint tracking. Extensive experiments are conducted on a new dataset featuring both image frames and event data captured under extreme conditions. The experimental results confirm the superior performance of our method over both existing frame-based and event-based methods.
2D-3D Pose Tracking with Multi-View Constraints
Sep 20, 2023Camera localization in 3D LiDAR maps has gained increasing attention due to its promising ability to handle complex scenarios, surpassing the limitations of visual-only localization methods. However, existing methods mostly focus on addressing the cross-modal gaps, estimating camera poses frame by frame without considering the relationship between adjacent frames, which makes the pose tracking unstable. To alleviate this, we propose to couple the 2D-3D correspondences between adjacent frames using the 2D-2D feature matching, establishing the multi-view geometrical constraints for simultaneously estimating multiple camera poses. Specifically, we propose a new 2D-3D pose tracking framework, which consists: a front-end hybrid flow estimation network for consecutive frames and a back-end pose optimization module. We further design a cross-modal consistency-based loss to incorporate the multi-view constraints during the training and inference process. We evaluate our proposed framework on the KITTI and Argoverse datasets. Experimental results demonstrate its superior performance compared to existing frame-by-frame 2D-3D pose tracking methods and state-of-the-art vision-only pose tracking algorithms. More online pose tracking videos are available at \url{https://youtu.be/yfBRdg7gw5M}