 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Attend: A Principled Vision-Centric Position Encoding with Parabolas
Feb 01, 2026We propose Parabolic Position Encoding (PaPE), a parabola-based position encoding for vision modalities in attention-based architectures. Given a set of vision tokens-such as images, point clouds, videos, or event camera streams-our objective is to encode their positions while accounting for the characteristics of vision modalities. Prior works have largely extended position encodings from 1D-sequences in language to nD-structures in vision, but only with partial account of vision characteristics. We address this gap by designing PaPE from principles distilled from prior work: translation invariance, rotation invariance (PaPE-RI), distance decay, directionality, and context awareness. We evaluate PaPE on 8 datasets that span 4 modalities. We find that either PaPE or PaPE-RI achieves the top performance on 7 out of 8 datasets. Extrapolation experiments on ImageNet-1K show that PaPE extrapolates remarkably well, improving in absolute terms by up to 10.5% over the next-best position encoding. Code is available at https://github.com/DTU-PAS/parabolic-position-encoding.
PALM: Enhanced Generalizability for Local Visuomotor Policies via Perception Alignment
Jan 27, 2026Generalizing beyond the training domain in image-based behavior cloning remains challenging. Existing methods address individual axes of generalization, workspace shifts, viewpoint changes, and cross-embodiment transfer, yet they are typically developed in isolation and often rely on complex pipelines. We introduce PALM (Perception Alignment for Local Manipulation), which leverages the invariance of local action distributions between out-of-distribution (OOD) and demonstrated domains to address these OOD shifts concurrently, without additional input modalities, model changes, or data collection. PALM modularizes the manipulation policy into coarse global components and a local policy for fine-grained actions. We reduce the discrepancy between in-domain and OOD inputs at the local policy level by enforcing local visual focus and consistent proprioceptive representation, allowing the policy to retrieve invariant local actions under OOD conditions. Experiments show that PALM limits OOD performance drops to 8% in simulation and 24% in the real world, compared to 45% and 77% for baselines.
ViTA-Seg: Vision Transformer for Amodal Segmentation in Robotics
Dec 10, 2025Occlusions in robotic bin picking compromise accurate and reliable grasp planning. We present ViTA-Seg, a class-agnostic Vision Transformer framework for real-time amodal segmentation that leverages global attention to recover complete object masks, including hidden regions. We proposte two architectures: a) Single-Head for amodal mask prediction; b) Dual-Head for amodal and occluded mask prediction. We also introduce ViTA-SimData, a photo-realistic synthetic dataset tailored to industrial bin-picking scenario. Extensive experiments on two amodal benchmarks, COOCA and KINS, demonstrate that ViTA-Seg Dual Head achieves strong amodal and occlusion segmentation accuracy with computational efficiency, enabling robust, real-time robotic manipulation.
Federated Learning for Large-Scale Cloud Robotic Manipulation: Opportunities and Challenges
Jul 23, 2025Federated Learning (FL) is an emerging distributed machine learning paradigm, where the collaborative training of a model involves dynamic participation of devices to achieve broad objectives. In contrast, classical machine learning (ML) typically requires data to be located on-premises for training, whereas FL leverages numerous user devices to train a shared global model without the need to share private data. Current robotic manipulation tasks are constrained by the individual capabilities and speed of robots due to limited low-latency computing resources. Consequently, the concept of cloud robotics has emerged, allowing robotic applications to harness the flexibility and reliability of computing resources, effectively alleviating their computational demands across the cloud-edge continuum. Undoubtedly, within this distributed computing context, as exemplified in cloud robotic manipulation scenarios, FL offers manifold advantages while also presenting several challenges and opportunities. In this paper, we present fundamental concepts of FL and their connection to cloud robotic manipulation. Additionally, we envision the opportunities and challenges associated with realizing efficient and reliable cloud robotic manipulation at scale through FL, where researchers adopt to design and verify FL models in either centralized or decentralized settings.
Unifying Complementarity Constraints and Control Barrier Functions for Safe Whole-Body Robot Control
Apr 24, 2025Safety-critical whole-body robot control demands reactive methods that ensure collision avoidance in real-time. Complementarity constraints and control barrier functions (CBF) have emerged as core tools for ensuring such safety constraints, and each represents a well-developed field. Despite addressing similar problems, their connection remains largely unexplored. This paper bridges this gap by formally proving the equivalence between these two methodologies for sampled-data, first-order systems, considering both single and multiple constraint scenarios. By demonstrating this equivalence, we provide a unified perspective on these techniques. This unification has theoretical and practical implications, facilitating the cross-application of robustness guarantees and algorithmic improvements between complementarity and CBF frameworks. We discuss these synergistic benefits and motivate future work in the comparison of the methods in more general cases.
Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs
Apr 15, 2025Reasoning is the fundamental capability of large language models (LLMs). Due to the rapid progress of LLMs, there are two main issues of current benchmarks: i) these benchmarks can be crushed in a short time (less than 1 year), and ii) these benchmarks may be easily hacked. To handle these issues, we propose the ever-scalingness for building the benchmarks which are uncrushable, unhackable, auto-verifiable and general. This paper presents Nondeterministic Polynomial-time Problem Challenge (NPPC), an ever-scaling reasoning benchmark for LLMs. Specifically, the NPPC has three main modules: i) npgym, which provides a unified interface of 25 well-known NP-complete problems and can generate any number of instances with any levels of complexities, ii) npsolver: which provides a unified interface to evaluate the problem instances with both online and offline models via APIs and local deployments, respectively, and iii) npeval: which provides the comprehensive and ready-to-use tools to analyze the performances of LLMs over different problems, the number of tokens, the aha moments, the reasoning errors and the solution errors. Extensive experiments over widely-used LLMs demonstrate: i) NPPC can successfully decrease the performances of advanced LLMs' performances to below 10%, demonstrating that NPPC is uncrushable, ii) DeepSeek-R1, Claude-3.7-Sonnet, and o1/o3-mini are the most powerful LLMs, where DeepSeek-R1 outperforms Claude-3.7-Sonnet and o1/o3-mini in most NP-complete problems considered, and iii) the numbers of tokens, aha moments in the advanced LLMs, e.g., Claude-3.7-Sonnet and DeepSeek-R1, are observed first to increase and then decrease when the problem instances become more and more difficult. We believe that NPPC is the first ever-scaling reasoning benchmark, serving as the uncrushable and unhackable testbed for LLMs toward artificial general intelligence (AGI).
Can Visuo-motor Policies Benefit from Random Exploration Data? A Case Study on Stacking
Mar 30, 2025Human demonstrations have been key to recent advancements in robotic manipulation, but their scalability is hampered by the substantial cost of the required human labor. In this paper, we focus on random exploration data-video sequences and actions produced autonomously via motions to randomly sampled positions in the workspace-as an often overlooked resource for training visuo-motor policies in robotic manipulation. Within the scope of imitation learning, we examine random exploration data through two paradigms: (a) by investigating the use of random exploration video frames with three self-supervised learning objectives-reconstruction, contrastive, and distillation losses-and evaluating their applicability to visual pre-training; and (b) by analyzing random motor commands in the context of a staged learning framework to assess their effectiveness in autonomous data collection. Towards this goal, we present a large-scale experimental study based on over 750 hours of robot data collection, comprising 400 successful and 12,000 failed episodes. Our results indicate that: (a) among the three self-supervised learning objectives, contrastive loss appears most effective for visual pre-training while leveraging random exploration video frames; (b) data collected with random motor commands may play a crucial role in balancing the training data distribution and improving success rates in autonomous data collection within this study. The source code and dataset will be made publicly available at https://cloudgripper.org.
Data-augmented Learning of Geodesic Distances in Irregular Domains through Soner Boundary Conditions
Mar 06, 2025Geodesic distances play a fundamental role in robotics, as they efficiently encode global geometric information of the domain. Recent methods use neural networks to approximate geodesic distances by solving the Eikonal equation through physics-informed approaches. While effective, these approaches often suffer from unstable convergence during training in complex environments. We propose a framework to learn geodesic distances in irregular domains by using the Soner boundary condition, and systematically evaluate the impact of data losses on training stability and solution accuracy. Our experiments demonstrate that incorporating data losses significantly improves convergence robustness, reducing training instabilities and sensitivity to initialization. These findings suggest that hybrid data-physics approaches can effectively enhance the reliability of learning-based geodesic distance solvers with sparse data.
T-DOM: A Taxonomy for Robotic Manipulation of Deformable Objects
Dec 30, 2024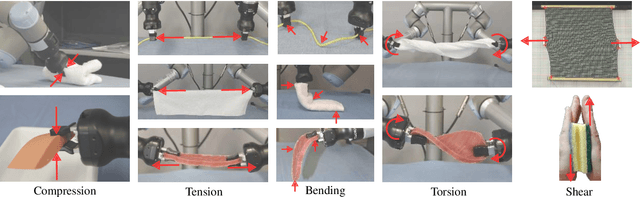
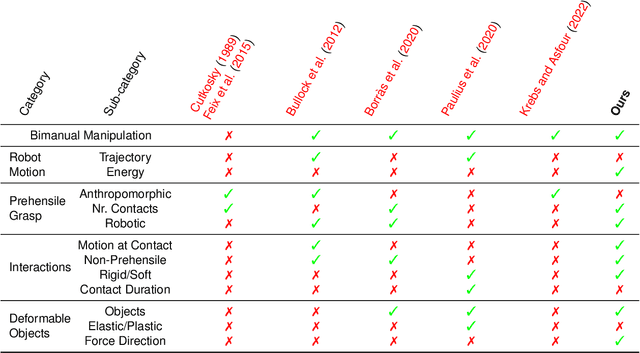

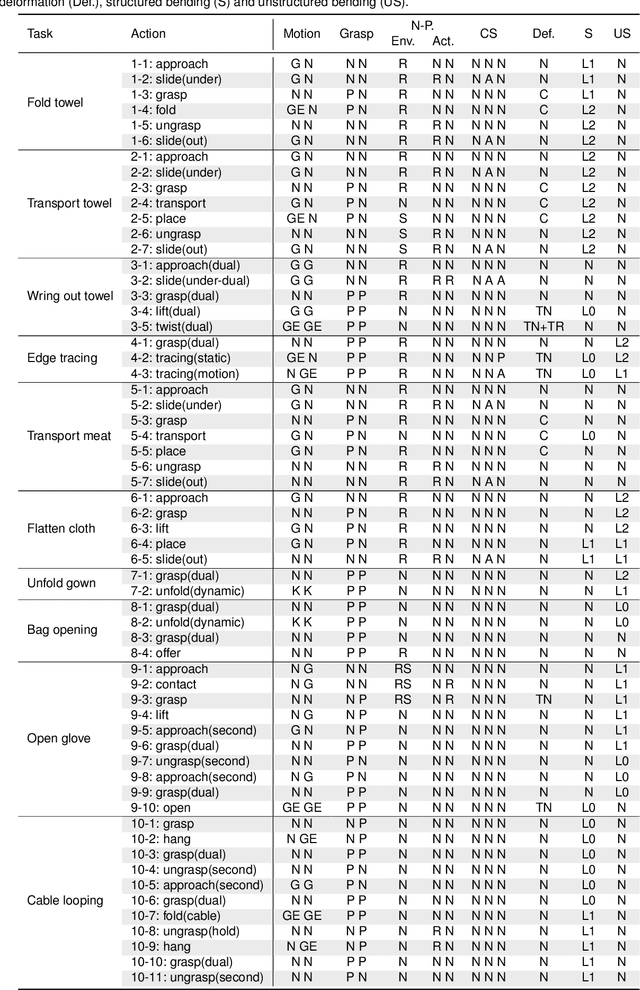
Robotic grasp and manipulation taxonomies, inspired by observing human manipulation strategies, can provide key guidance for tasks ranging from robotic gripper design to the development of manipulation algorithms. The existing grasp and manipulation taxonomies, however, often assume object rigidity, which limits their ability to reason about the complex interactions in the robotic manipulation of deformable objects. Hence, to assist in tasks involving deformable objects, taxonomies need to capture more comprehensively the interactions inherent in deformable object manipulation. To this end, we introduce T-DOM, a taxonomy that analyses key aspects involved in the manipulation of deformable objects, such as robot motion, forces, prehensile and non-prehensile interactions and, for the first time, a detailed classification of object deformations. To evaluate T-DOM, we curate a dataset of ten tasks involving a variety of deformable objects, such as garments, ropes, and surgical gloves, as well as diverse types of deformations. We analyse the proposed tasks comparing the T-DOM taxonomy with previous well established manipulation taxonomies. Our analysis demonstrates that T-DOM can effectively distinguish between manipulation skills that were not identified in other taxonomies, across different deformable objects and manipulation actions, offering new categories to characterize a skill. The proposed taxonomy significantly extends past work, providing a more fine-grained classification that can be used to describe the robotic manipulation of deformable objects. This work establishes a foundation for advancing deformable object manipulation, bridging theoretical understanding and practical implementation in robotic systems.
PACA: Perspective-Aware Cross-Attention Representation for Zero-Shot Scene Rearrangement
Oct 29, 2024



Scene rearrangement, like table tidying, is a challenging task in robotic manipulation due to the complexity of predicting diverse object arrangements. Web-scale trained generative models such as Stable Diffusion can aid by generating natural scenes as goals. To facilitate robot execution, object-level representations must be extracted to match the real scenes with the generated goals and to calculate object pose transformations. Current methods typically use a multi-step design that involves separate models for generation, segmentation, and feature encoding, which can lead to a low success rate due to error accumulation. Furthermore, they lack control over the viewing perspectives of the generated goals, restricting the tasks to 3-DoF settings. In this paper, we propose PACA, a zero-shot pipeline for scene rearrangement that leverages perspective-aware cross-attention representation derived from Stable Diffusion. Specifically, we develop a representation that integrates generation, segmentation, and feature encoding into a single step to produce object-level representations. Additionally, we introduce perspective control, thus enabling the matching of 6-DoF camera views and extending past approaches that were limited to 3-DoF top-down views. The efficacy of our method is demonstrated through its zero-shot performance in real robot experiments across various scenes, achieving an average matching accuracy and execution success rate of 87% and 67%, respectively.