 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: Enhanced Generalizability for Local Visuomotor Policies via Perception Alignment
Jan 27, 2026Generalizing beyond the training domain in image-based behavior cloning remains challenging. Existing methods address individual axes of generalization, workspace shifts, viewpoint changes, and cross-embodiment transfer, yet they are typically developed in isolation and often rely on complex pipelines. We introduce PALM (Perception Alignment for Local Manipulation), which leverages the invariance of local action distributions between out-of-distribution (OOD) and demonstrated domains to address these OOD shifts concurrently, without additional input modalities, model changes, or data collection. PALM modularizes the manipulation policy into coarse global components and a local policy for fine-grained actions. We reduce the discrepancy between in-domain and OOD inputs at the local policy level by enforcing local visual focus and consistent proprioceptive representation, allowing the policy to retrieve invariant local actions under OOD conditions. Experiments show that PALM limits OOD performance drops to 8% in simulation and 24% in the real world, compared to 45% and 77% for baselines.
Raising Body Ownership in End-to-End Visuomotor Policy Learning via Robot-Centric Pooling
Nov 07, 2024



We present Robot-centric Pooling (RcP), a novel pooling method designed to enhance end-to-end visuomotor policies by enabling differentiation between the robots and similar entities or their surroundings. Given an image-proprioception pair, RcP guides the aggregation of image features by highlighting image regions correlating with the robot's proprioceptive states, thereby extracting robot-centric image representations for policy learning. Leveraging contrastive learning techniques, RcP integrates seamlessly with existing visuomotor policy learning frameworks and is trained jointly with the policy using the same dataset, requiring no extra data collection involving self-distractors. We evaluate the proposed method with reaching tasks in both simulated and real-world settings. The results demonstrate that RcP significantly enhances the policies' robustness against various unseen distractors, including self-distractors, positioned at different locations. Additionally, the inherent robot-centric characteristic of RcP enables the learnt policy to be far more resilient to aggressive pixel shifts compared to the baselines.
Feature Extractor or Decision Maker: Rethinking the Role of Visual Encoders in Visuomotor Policies
Sep 30, 2024



An end-to-end (E2E) visuomotor policy is typically treated as a unified whole, but recent approaches using out-of-domain (OOD) data to pretrain the visual encoder have cleanly separated the visual encoder from the network, with the remainder referred to as the policy. We propose Visual Alignment Testing, an experimental framework designed to evaluate the validity of this functional separation. Our results indicate that in E2E-trained models, visual encoders actively contribute to decision-making resulting from motor data supervision, contradicting the assumed functional separation. In contrast, OOD-pretrained models, where encoders lack this capability, experience an average performance drop of 42% in our benchmark results, compared to the state-of-the-art performance achieved by E2E policies. We believe this initial exploration of visual encoders' role can provide a first step towards guiding future pretraining methods to address their decision-making ability, such as developing task-conditioned or context-aware encoders.
End-to-end Multi-Instance Robotic Reaching from Monocular Vision
Jan 22, 2024Multi-instance scenes are especially challenging for end-to-end visuomotor (image-to-control) learning algorithms. "Pipeline" visual servo control algorithms use separate detection, selection and servo stages, allowing algorithms to focus on a single object instance during servo control. End-to-end systems do not have separate detection and selection stages and need to address the visual ambiguities introduced by the presence of arbitrary number of visually identical or similar objects during servo control. However, end-to-end schemes avoid embedding errors from detection and selection stages in the servo control behaviour, are more dynamically robust to changing scenes, and are algorithmically simpler. In this paper, we present a real-time end-to-end visuomotor learning algorithm for multi-instance reaching. The proposed algorithm uses a monocular RGB image and the manipulator's joint angles as the input to a light-weight fully-convolutional network (FCN) to generate control candidates. A key innovation of the proposed method is identifying the optimal control candidate by regressing a control-Lyapunov function (cLf) value. The multi-instance capability emerges naturally from the stability analysis associated with the cLf formulation. We demonstrate the proposed algorithm effectively reaching and grasping objects from different categories on a table-top amid other instances and distractors from an over-the-shoulder monocular RGB camera. The network is able to run up to approximately 160 fps during inference on one GTX 1080 Ti GPU.
GoferBot: A Visual Guided Human-Robot Collaborative Assembly System
Apr 18, 2023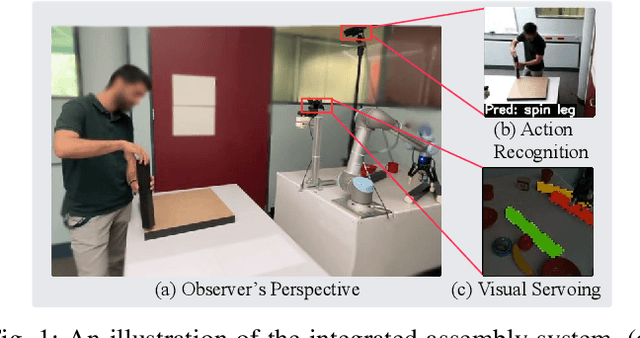
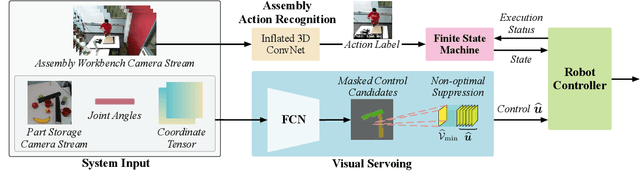
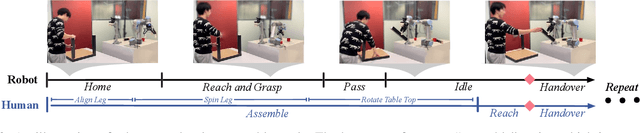
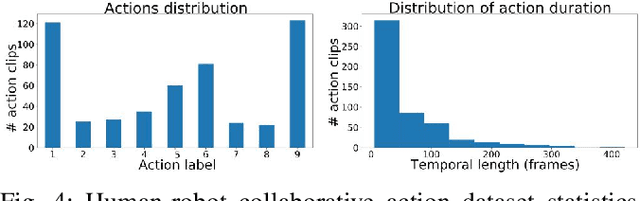
The current transformation towards smart manufacturing has led to a growing demand for human-robot collaboration (HRC) in the manufacturing process. Perceiving and understanding the human co-worker's behaviour introduces challenges for collaborative robots to efficiently and effectively perform tasks in unstructured and dynamic environments. Integrating recent data-driven machine vision capabilities into HRC systems is a logical next step in addressing these challenges. However, in these cases, off-the-shelf components struggle due to generalisation limitations. Real-world evaluation is required in order to fully appreciate the maturity and robustness of these approaches. Furthermore, understanding the pure-vision aspects is a crucial first step before combining multiple modalities in order to understand the limitations. In this paper, we propose GoferBot, a novel vision-based semantic HRC system for a real-world assembly task. It is composed of a visual servoing module that reaches and grasps assembly parts in an unstructured multi-instance and dynamic environment, an action recognition module that performs human action prediction for implicit communication, and a visual handover module that uses the perceptual understanding of human behaviour to produce an intuitive and efficient collaborative assembly experience. GoferBot is a novel assembly system that seamlessly integrates all sub-modules by utilising implicit semantic information purely from visual perception.
Stereo Hybrid Event-Frame Cameras for 3D Perception
Oct 11, 2021
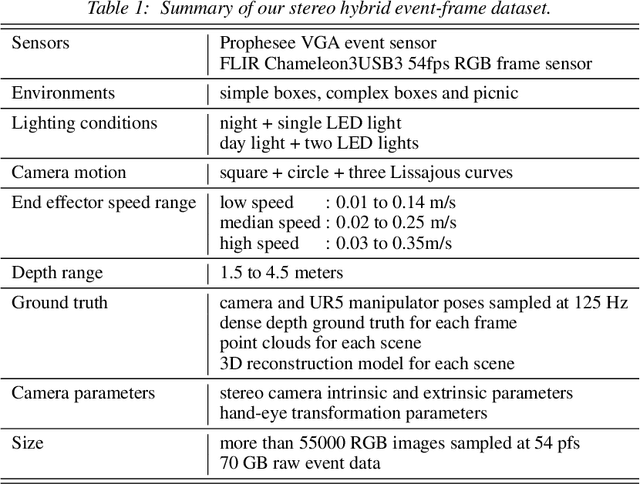


Stereo camera systems play an important role in robotics applications to perceive the 3D world. However, conventional cameras have drawbacks such as low dynamic range, motion blur and latency due to the underlying frame-based mechanism. Event cameras address these limitations as they report the brightness changes of each pixel independently with a fine temporal resolution, but they are unable to acquire absolute intensity information directly. Although integrated hybrid event-frame sensors (eg., DAVIS) are available, the quality of data is compromised by coupling at the pixel level in the circuit fabrication of such cameras. This paper proposes a stereo hybrid event-frame (SHEF) camera system that offers a sensor modality with separate high-quality pure event and pure frame cameras, overcoming the limitations of each separate sensor and allowing for stereo depth estimation. We provide a SHEF dataset targeted at evaluating disparity estimation algorithms and introduce a stereo disparity estimation algorithm that uses edge information extracted from the event stream correlated with the edge detected in the frame data. Our disparity estimation outperforms the state-of-the-art stereo matching algorithm on the SHEF dataset.
Iterative Optimisation with an Innovation CNN for Pose Refinement
Jan 22, 2021
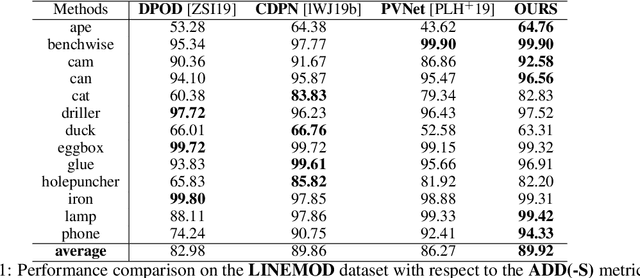
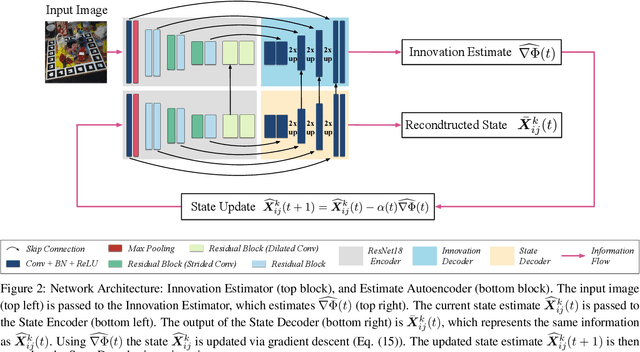

Object pose estimation from a single RGB image is a challenging problem due to variable lighting conditions and viewpoint changes. The most accurate pose estimation networks implement pose refinement via reprojection of a known, textured 3D model, however, such methods cannot be applied without high quality 3D models of the observed objects. In this work we propose an approach, namely an Innovation CNN, to object pose estimation refinement that overcomes the requirement for reprojecting a textured 3D model. Our approach improves initial pose estimation progressively by applying the Innovation CNN iteratively in a stochastic gradient descent (SGD) framework. We evaluate our method on the popular LINEMOD and Occlusion LINEMOD datasets and obtain state-of-the-art performance on both datasets.
LyRN : A Real-Time Closed Loop approach from Monocular Vision
May 28, 2020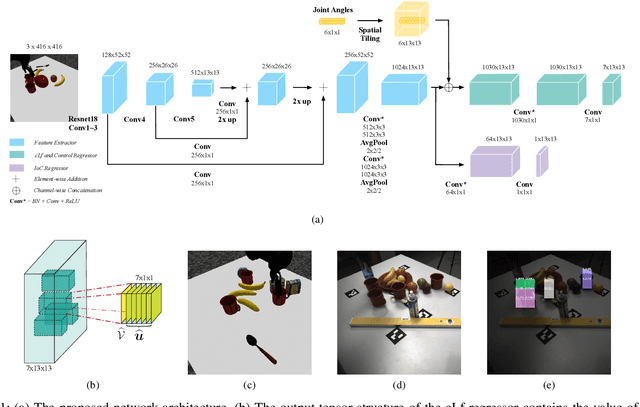
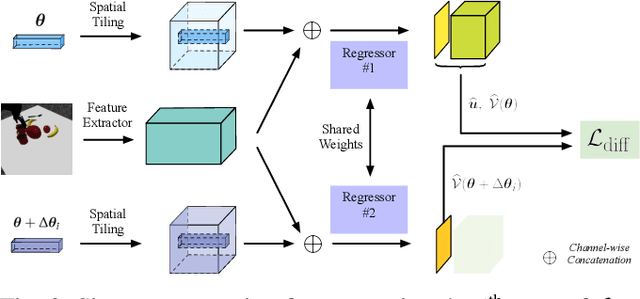
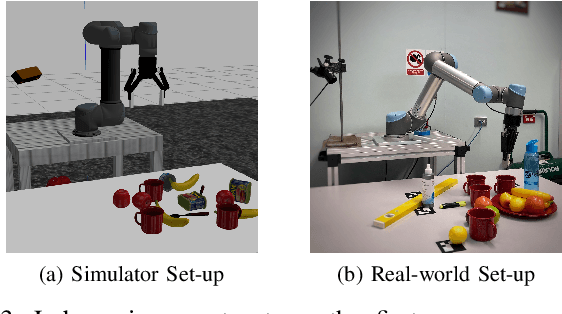
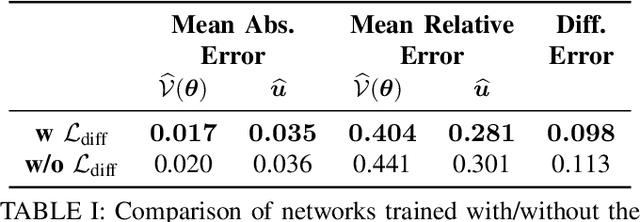
We propose a closed-loop, multi-instance control algorithm for visually guided reaching based on novel learning principles. A control Lyapunov function methodology is used to design a reaching action for a complex multi-instance task in the case where full state information (poses of all potential reaching points) is available. The proposed algorithm uses monocular vision and manipulator joint angles as the input to a deep convolution neural network to predict the value of the control Lyapunov function (cLf) and corresponding velocity control. The resulting network output is used in real-time as visual control for the grasping task with the multi-instance capability emerging naturally from the design of the control Lyapunov function. We demonstrate the proposed algorithm grasping mugs (textureless and symmetric objects) on a table-top from an over-the-shoulder monocular RGB camera. The manipulator dynamically converges to the best-suited target among multiple identical instances from any random initial pose within the workspace. The system trained with only simulated data is able to achieve 90.3% grasp success rate in the real-world experiments with up to 85Hz closed-loop control on one GTX 1080Ti GPU and significantly outperforms a Pose-Based-Visual-Servo (PBVS) grasping system adapted from a state-of-the-art single shot RGB 6D pose estimation algorithm. A key contribution of the paper is the inclusion of a first-order differential constraint associated with the cLf as a regularisation term during learning, and we provide evidence that this leads to more robust and reliable reaching/grasping performance than vanilla regression on general control inputs.
6DoF Object Pose Estimation via Differentiable Proxy Voting Loss
Feb 10, 2020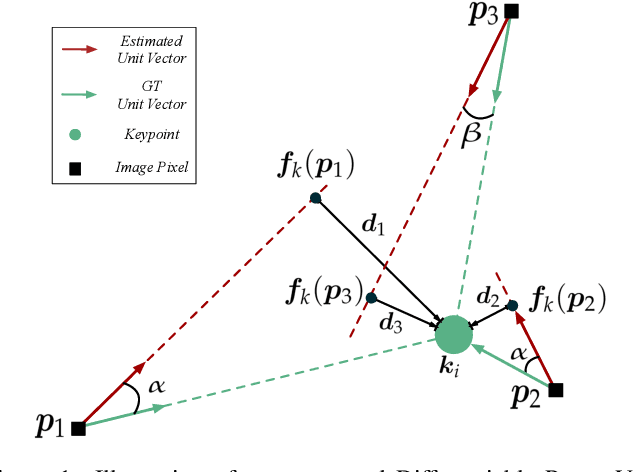
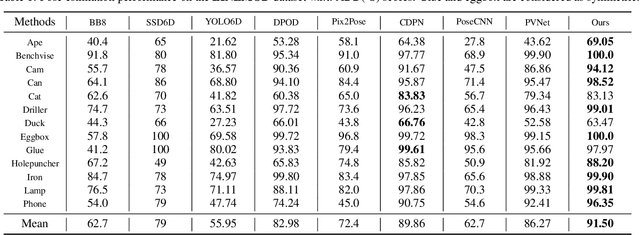
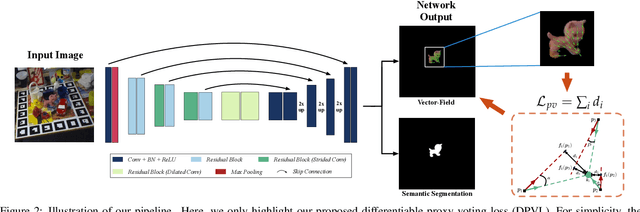
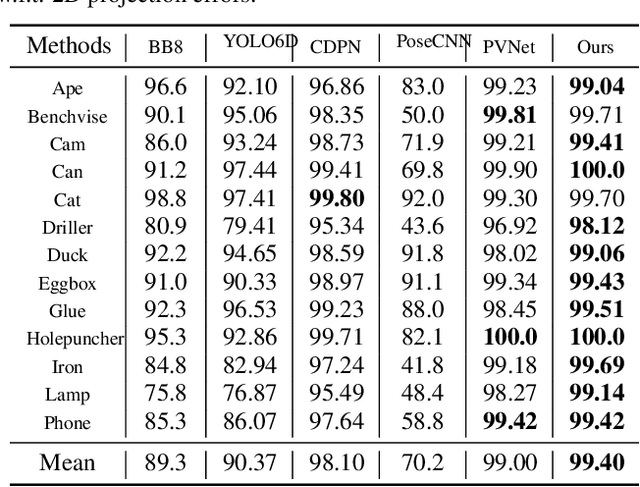
Estimating a 6DOF object pose from a single image is very challenging due to occlusions or textureless appearances. Vector-field based keypoint voting has demonstrated its effectiveness and superiority on tackling those issues. However, direct regression of vector-fields neglects that the distances between pixels and keypoints also affect the deviations of hypotheses dramatically. In other words, small errors in direction vectors may generate severely deviated hypotheses when pixels are far away from a keypoint. In this paper, we aim to reduce such errors by incorporating the distances between pixels and keypoints into our objective. To this end, we develop a simple yet effective differentiable proxy voting loss (DPVL) which mimics the hypothesis selection in the voting procedure. By exploiting our voting loss, we are able to train our network in an end-to-end manner. Experiments on widely used datasets, i.e. LINEMOD and Occlusion LINEMOD, manifest that our DPVL improves pose estimation performance significantly and speeds up the training convergence.