 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Enhanced Depth Scaling for Multimodal Latent Reasoning
Apr 12, 2026Multimodal latent reasoning has emerged as a promising paradigm that replaces explicit Chain-of-Thought (CoT) decoding with implicit feature propagation, simultaneously enhancing representation informativeness and reducing inference latency. By analyzing token-level gradient dynamics during latent training, we reveal two critical observations: (1) visual tokens exhibit significantly higher and more volatile gradient norms than their textual counterparts due to inherent language bias, resulting in systematic visual under-optimization; and (2) semantically simple tokens converge rapidly, whereas complex tokens exhibit persistent gradient instability constrained by fixed architectural depths. To address these limitations, we propose a visual replay module and routing depth scaling to collaboratively enhance visual perception and refine complicated latents for deeper contextual reasoning. The former module leverages causal self-attention to estimate token saliency, reinforcing fine-grained grounding through spatially-coherent constraints. Complementarily, the latter mechanism adaptively allocates additional reasoning steps to complex tokens, enabling deeper contextual refinement. Guided by a curriculum strategy that progressively internalizes explicit CoT into compact latent representations, our framework achieves state-of-the-art performance across diverse benchmarks while delivering substantial inference speedups over explicit CoT baselines.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
Stateful Cross-layer Vision Modulation
Feb 28, 2026Recent multimodal large language models (MLLMs) widely adopt multi-layer visual feature fusion to enhance visual representation. However, existing approaches typically perform static concatenation or weighted aggregation after visual encoding, without intervening in the representation formation process itself. As a result, fine-grained details from early layers may be progressively suppressed during hierarchical abstraction. Moreover, directly introducing shallow-layer features into the language model often leads to semantic distribution mismatch with the visual feature space that the LLM's cross-attention layers were pretrained on, which typically requires additional adaptation or fine-tuning of the LLM. To address these limitations, we revisit visual representation learning from the perspective of representation evolution control and propose a cross-layer memory-modulated vision framework(SCVM). Specifically, we introduce a recursively updated cross-layer memory state inside the vision encoder to model long-range inter-layer dependencies. We further design a layer-wise feedback modulation mechanism that refreshes token representations at each layer based on the accumulated memory, thereby structurally regulating the representation evolution trajectory. In addition, we incorporate an auxiliary semantic alignment objective that explicitly supervises the final memory state, encouraging progressive compression and reinforcement of task-relevant information. Experimental results on multiple visual question answering and hallucination evaluation benchmarks demonstrate that SCVM achieves consistent performance improvements without expanding visual tokens, introducing additional vision encoders, or modifying or fine-tuning the language model.
A Preliminary Study for GPT-4o on Image Restoration
May 08, 2025



OpenAI's GPT-4o model, integrating multi-modal inputs and outputs within an autoregressive architecture, has demonstrated unprecedented performance in image generation. In this work, we investigate its potential impact on the image restoration community. We present the first systematic evaluation of GPT-4o across diverse restoration tasks. Our experiments reveal that, although restoration outputs from GPT-4o are visually appealing, they often suffer from pixel-level structural fidelity when compared to ground-truth images. Common issues are variations in image proportions, shifts in object positions and quantities, and changes in viewpoint.To address it, taking image dehazing, derainning, and low-light enhancement as representative case studies, we show that GPT-4o's outputs can serve as powerful visual priors, substantially enhancing the performance of existing dehazing networks. It offers practical guidelines and a baseline framework to facilitate the integration of GPT-4o into future image restoration pipelines. We hope the study on GPT-4o image restoration will accelerate innovation in the broader field of image generation areas. To support further research, we will release GPT-4o-restored images from over 10 widely used image restoration datasets.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
ProBench: Judging Multimodal Foundation Models on Open-ended Multi-domain Expert Tasks
Mar 10, 2025Solving expert-level multimodal tasks is a key milestone towards general intelligence. As the capabilities of multimodal large language models (MLLMs) continue to improve, evaluation of such advanced multimodal intelligence becomes necessary yet challenging. In this work, we introduce ProBench, a benchmark of open-ended user queries that require professional expertise and advanced reasoning. ProBench consists of 4,000 high-quality samples independently submitted by professionals based on their daily productivity demands. It spans across 10 fields and 56 sub-fields, including science, arts, humanities, coding, mathematics, and creative writing. Experimentally, we evaluate and compare 24 latest models using MLLM-as-a-Judge. Our results reveal that although the best open-source models rival the proprietary ones, ProBench presents significant challenges in visual perception, textual understanding, domain knowledge and advanced reasoning, thus providing valuable directions for future multimodal AI research efforts.
Spatial Transcriptomics Analysis of Spatially Dense Gene Expression Prediction
Mar 03, 2025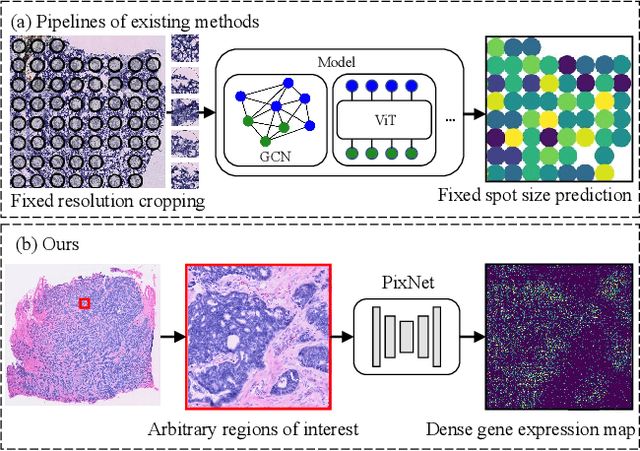
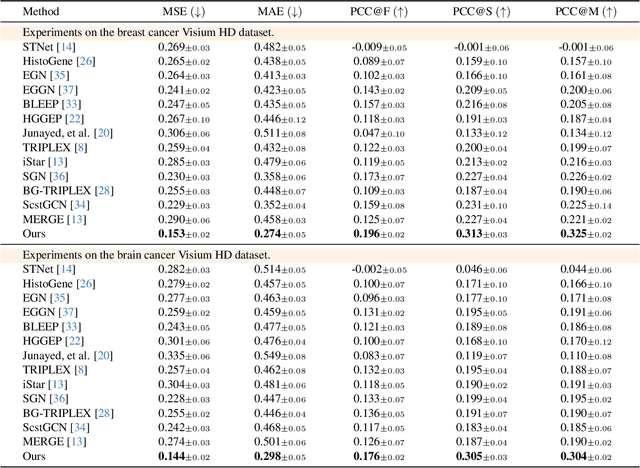
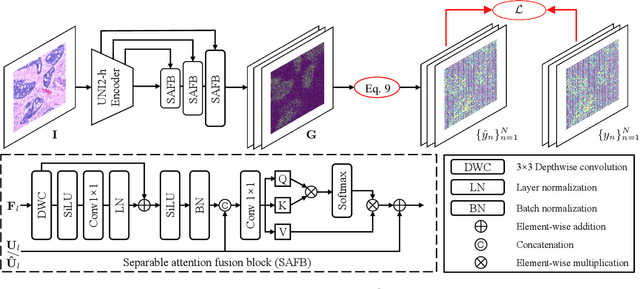
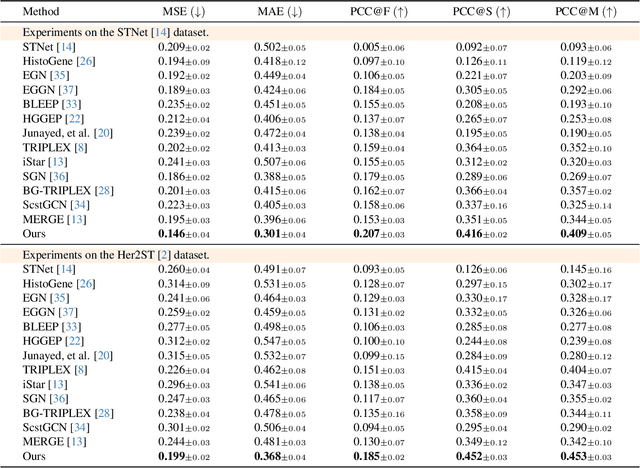
Spatial transcriptomics (ST) measures gene expression at fine-grained spatial resolution, offering insights into tissue molecular landscapes. Previous methods for spatial gene expression prediction usually crop spots of interest from pathology tissue slide images, and learn a model that maps each spot to a single gene expression profile. However, it fundamentally loses spatial resolution of gene expression: 1) each spot often contains multiple cells with distinct gene expression; 2) spots are cropped at fixed resolutions, limiting the ability to predict gene expression at varying spatial scales. To address these limitations, this paper presents PixNet, a dense prediction network capable of predicting spatially resolved gene expression across spots of varying sizes and scales directly from pathology images. Different from previous methods that map individual spots to gene expression values, we generate a dense continuous gene expression map from the pathology image, and aggregate values within spots of interest to predict the gene expression. Our PixNet outperforms state-of-the-art methods on 3 common ST datasets, while showing superior performance in predicting gene expression across multiple spatial scales. The source code will be publicly available.
DynFocus: Dynamic Cooperative Network Empowers LLMs with Video Understanding
Nov 19, 2024The challenge in LLM-based video understanding lies in preserving visual and semantic information in long videos while maintaining a memory-affordable token count. However, redundancy and correspondence in videos have hindered the performance potential of existing methods. Through statistical learning on current datasets, we observe that redundancy occurs in both repeated and answer-irrelevant frames, and the corresponding frames vary with different questions. This suggests the possibility of adopting dynamic encoding to balance detailed video information preservation with token budget reduction. To this end, we propose a dynamic cooperative network, DynFocus, for memory-efficient video encoding in this paper. Specifically, i) a Dynamic Event Prototype Estimation (DPE) module to dynamically select meaningful frames for question answering; (ii) a Compact Cooperative Encoding (CCE) module that encodes meaningful frames with detailed visual appearance and the remaining frames with sketchy perception separately. We evaluate our method on five publicly available benchmarks, and experimental results consistently demonstrate that our method achieves competitive performance.
SpikMamba: When SNN meets Mamba in Event-based Human Action Recognition
Oct 22, 2024



Human action recognition (HAR) plays a key role in various applications such as video analysis, surveillance, autonomous driving, robotics, and healthcare. Most HAR algorithms are developed from RGB images, which capture detailed visual information. However, these algorithms raise concerns in privacy-sensitive environments due to the recording of identifiable features. Event cameras offer a promising solution by capturing scene brightness changes sparsely at the pixel level, without capturing full images. Moreover, event cameras have high dynamic ranges that can effectively handle scenarios with complex lighting conditions, such as low light or high contrast environments. However, using event cameras introduces challenges in modeling the spatially sparse and high temporal resolution event data for HAR. To address these issues, we propose the SpikMamba framework, which combines the energy efficiency of spiking neural networks and the long sequence modeling capability of Mamba to efficiently capture global features from spatially sparse and high a temporal resolution event data. Additionally, to improve the locality of modeling, a spiking window-based linear attention mechanism is used. Extensive experiments show that SpikMamba achieves remarkable recognition performance, surpassing the previous state-of-the-art by 1.45%, 7.22%, 0.15%, and 3.92% on the PAF, HARDVS, DVS128, and E-FAction datasets, respectively. The code is available at https://github.com/Typistchen/SpikMamba.
LMHaze: Intensity-aware Image Dehazing with a Large-scale Multi-intensity Real Haze Dataset
Oct 21, 2024



Image dehazing has drawn a significant attention in recent years. Learning-based methods usually require paired hazy and corresponding ground truth (haze-free) images for training. However, it is difficult to collect real-world image pairs, which prevents developments of existing methods. Although several works partially alleviate this issue by using synthetic datasets or small-scale real datasets. The haze intensity distribution bias and scene homogeneity in existing datasets limit the generalization ability of these methods, particularly when encountering images with previously unseen haze intensities. In this work, we present LMHaze, a large-scale, high-quality real-world dataset. LMHaze comprises paired hazy and haze-free images captured in diverse indoor and outdoor environments, spanning multiple scenarios and haze intensities. It contains over 5K high-resolution image pairs, surpassing the size of the biggest existing real-world dehazing dataset by over 25 times. Meanwhile, to better handle images with different haze intensities, we propose a mixture-of-experts model based on Mamba (MoE-Mamba) for dehazing, which dynamically adjusts the model parameters according to the haze intensity. Moreover, with our proposed dataset, we conduct a new large multimodal model (LMM)-based benchmark study to simulate human perception for evaluating dehazed images. Experiments demonstrate that LMHaze dataset improves the dehazing performance in real scenarios and our dehazing method provides better results compared to state-of-the-art methods.