 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRWKV:Frequency-Domain Linear Attention for Long-Term Time Series Forecasting
Dec 09, 2025Traditional Transformers face a major bottleneck in long-sequence time series forecasting due to their quadratic complexity $(\mathcal{O}(T^2))$ and their limited ability to effectively exploit frequency-domain information. Inspired by RWKV's $\mathcal{O}(T)$ linear attention and frequency-domain modeling, we propose FRWKV, a frequency-domain linear-attention framework that overcomes these limitations. Our model integrates linear attention mechanisms with frequency-domain analysis, achieving $\mathcal{O}(T)$ computational complexity in the attention path while exploiting spectral information to enhance temporal feature representations for scalable long-sequence modeling. Across eight real-world datasets, FRWKV achieves a first-place average rank. Our ablation studies confirm the critical roles of both the linear attention and frequency-encoder components. This work demonstrates the powerful synergy between linear attention and frequency analysis, establishing a new paradigm for scalable time series modeling. Code is available at this repository: https://github.com/yangqingyuan-byte/FRWKV.
FOAM: A General Frequency-Optimized Anti-Overlapping Framework for Overlapping Object Perception
Jun 16, 2025Overlapping object perception aims to decouple the randomly overlapping foreground-background features, extracting foreground features while suppressing background features, which holds significant application value in fields such as security screening and medical auxiliary diagnosis. Despite some research efforts to tackle the challenge of overlapping object perception, most solutions are confined to the spatial domain. Through frequency domain analysis, we observe that the degradation of contours and textures due to the overlapping phenomenon can be intuitively reflected in the magnitude spectrum. Based on this observation, we propose a general Frequency-Optimized Anti-Overlapping Framework (FOAM) to assist the model in extracting more texture and contour information, thereby enhancing the ability for anti-overlapping object perception. Specifically, we design the Frequency Spatial Transformer Block (FSTB), which can simultaneously extract features from both the frequency and spatial domains, helping the network capture more texture features from the foreground. In addition, we introduce the Hierarchical De-Corrupting (HDC) mechanism, which aligns adjacent features in the separately constructed base branch and corruption branch using a specially designed consistent loss during the training phase. This mechanism suppresses the response to irrelevant background features of FSTBs, thereby improving the perception of foreground contour. We conduct extensive experiments to validate the effectiveness and generalization of the proposed FOAM, which further improves the accuracy of state-of-the-art models on four datasets, specifically for the three overlapping object perception tasks: Prohibited Item Detection, Prohibited Item Segmentation, and Pneumonia Detection. The code will be open source once the paper is accepted.
CRoF: CLIP-based Robust Few-shot Learning on Noisy Labels
Dec 17, 2024



Noisy labels threaten the robustness of few-shot learning (FSL) due to the inexact features in a new domain. CLIP, a large-scale vision-language model, performs well in FSL on image-text embedding similarities, but it is susceptible to misclassification caused by noisy labels. How to enhance domain generalization of CLIP on noisy data within FSL tasks is a critical challenge. In this paper, we provide a novel view to mitigate the influence of noisy labels, CLIP-based Robust Few-shot learning (CRoF). CRoF is a general plug-in module for CLIP-based models. To avoid misclassification and confused label embedding, we design the few-shot task-oriented prompt generator to give more discriminative descriptions of each category. The proposed prompt achieves larger distances of inter-class textual embedding. Furthermore, rather than fully trusting zero-shot classification by CLIP, we fine-tune CLIP on noisy few-shot data in a new domain with a weighting strategy like label-smooth. The weights for multiple potentially correct labels consider the relationship between CLIP's prior knowledge and original label information to ensure reliability. Our multiple label loss function further supports robust training under this paradigm. Comprehensive experiments show that CRoF, as a plug-in, outperforms fine-tuned and vanilla CLIP models on different noise types and noise ratios.
SpikMamba: When SNN meets Mamba in Event-based Human Action Recognition
Oct 22, 2024



Human action recognition (HAR) plays a key role in various applications such as video analysis, surveillance, autonomous driving, robotics, and healthcare. Most HAR algorithms are developed from RGB images, which capture detailed visual information. However, these algorithms raise concerns in privacy-sensitive environments due to the recording of identifiable features. Event cameras offer a promising solution by capturing scene brightness changes sparsely at the pixel level, without capturing full images. Moreover, event cameras have high dynamic ranges that can effectively handle scenarios with complex lighting conditions, such as low light or high contrast environments. However, using event cameras introduces challenges in modeling the spatially sparse and high temporal resolution event data for HAR. To address these issues, we propose the SpikMamba framework, which combines the energy efficiency of spiking neural networks and the long sequence modeling capability of Mamba to efficiently capture global features from spatially sparse and high a temporal resolution event data. Additionally, to improve the locality of modeling, a spiking window-based linear attention mechanism is used. Extensive experiments show that SpikMamba achieves remarkable recognition performance, surpassing the previous state-of-the-art by 1.45%, 7.22%, 0.15%, and 3.92% on the PAF, HARDVS, DVS128, and E-FAction datasets, respectively. The code is available at https://github.com/Typistchen/SpikMamba.
Mask-adaptive Gated Convolution and Bi-directional Progressive Fusion Network for Depth Completion
Jan 15, 2024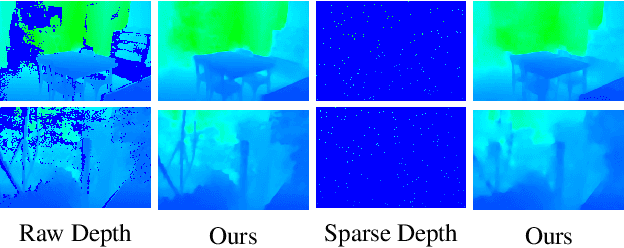



Depth completion is a critical task for handling depth images with missing pixels, which can negatively impact further applications. Recent approaches have utilized Convolutional Neural Networks (CNNs) to reconstruct depth images with the assistance of color images. However, vanilla convolution has non-negligible drawbacks in handling missing pixels. To solve this problem, we propose a new model for depth completion based on an encoder-decoder structure. Our model introduces two key components: the Mask-adaptive Gated Convolution (MagaConv) architecture and the Bi-directional Progressive Fusion (BP-Fusion) module. The MagaConv architecture is designed to acquire precise depth features by modulating convolution operations with iteratively updated masks, while the BP-Fusion module progressively integrates depth and color features, utilizing consecutive bi-directional fusion structures in a global perspective. Extensive experiments on popular benchmarks, including NYU-Depth V2, DIML, and SUN RGB-D, demonstrate the superiority of our model over state-of-the-art methods. We achieved remarkable performance in completing depth maps and outperformed existing approaches in terms of accuracy and reliability.
AGG-Net: Attention Guided Gated-convolutional Network for Depth Image Completion
Sep 04, 2023Recently, stereo vision based on lightweight RGBD cameras has been widely used in various fields. However, limited by the imaging principles, the commonly used RGB-D cameras based on TOF, structured light, or binocular vision acquire some invalid data inevitably, such as weak reflection, boundary shadows, and artifacts, which may bring adverse impacts to the follow-up work. In this paper, we propose a new model for depth image completion based on the Attention Guided Gated-convolutional Network (AGG-Net), through which more accurate and reliable depth images can be obtained from the raw depth maps and the corresponding RGB images. Our model employs a UNet-like architecture which consists of two parallel branches of depth and color features. In the encoding stage, an Attention Guided Gated-Convolution (AG-GConv) module is proposed to realize the fusion of depth and color features at different scales, which can effectively reduce the negative impacts of invalid depth data on the reconstruction. In the decoding stage, an Attention Guided Skip Connection (AG-SC) module is presented to avoid introducing too many depth-irrelevant features to the reconstruction. The experimental results demonstrate that our method outperforms the state-of-the-art methods on the popular benchmarks NYU-Depth V2, DIML, and SUN RGB-D.
Prior Knowledge Guided Network for Video Anomaly Detection
Sep 04, 2023



Video Anomaly Detection (VAD) involves detecting anomalous events in videos, presenting a significant and intricate task within intelligent video surveillance. Existing studies often concentrate solely on features acquired from limited normal data, disregarding the latent prior knowledge present in extensive natural image datasets. To address this constraint, we propose a Prior Knowledge Guided Network(PKG-Net) for the VAD task. First, an auto-encoder network is incorporated into a teacher-student architecture to learn two designated proxy tasks: future frame prediction and teacher network imitation, which can provide better generalization ability on unknown samples. Second, knowledge distillation on proper feature blocks is also proposed to increase the multi-scale detection ability of the model. In addition, prediction error and teacher-student feature inconsistency are combined to evaluate anomaly scores of inference samples more comprehensively. Experimental results on three public benchmarks validate the effectiveness and accuracy of our method, which surpasses recent state-of-the-arts.