 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMango-GS: Enhancing Spatio-Temporal Consistency in Dynamic Scenes Reconstruction using Multi-Frame Node-Guided 4D Gaussian Splatting
Mar 12, 2026Reconstructing dynamic 3D scenes with photorealistic detail and strong temporal coherence remains a significant challenge. Existing Gaussian splatting approaches for dynamic scene modeling often rely on per-frame optimization, which can overfit to instantaneous states instead of capturing underlying motion dynamics. To address this, we present Mango-GS, a multi-frame, node-guided framework for high-fidelity 4D reconstruction. Mango-GS leverages a temporal Transformer to model motion dependencies within a short window of frames, producing temporally consistent deformations. For efficiency, temporal modeling is confined to a sparse set of control nodes. Each node is represented by a decoupled canonical position and a latent code, providing a stable semantic anchor for motion propagation and preventing correspondence drift under large motion. Our framework is trained end-to-end, enhanced by an input masking strategy and two multi-frame losses to improve robustness. Extensive experiments demonstrate that Mango-GS achieves state-of-the-art reconstruction quality and real-time rendering speed, enabling high-fidelity reconstruction and interactive rendering of dynamic scenes.
TAP: A Token-Adaptive Predictor Framework for Training-Free Diffusion Acceleration
Mar 04, 2026Diffusion models achieve strong generative performance but remain slow at inference due to the need for repeated full-model denoising passes. We present Token-Adaptive Predictor (TAP), a training-free, probe-driven framework that adaptively selects a predictor for each token at every sampling step. TAP uses a single full evaluation of the model's first layer as a low-cost probe to compute proxy losses for a compact family of candidate predictors (instantiated primarily with Taylor expansions of varying order and horizon), then assigns each token the predictor with the smallest proxy error. This per-token "probe-then-select" strategy exploits heterogeneous temporal dynamics, requires no additional training, and is compatible with various predictor designs. TAP incurs negligible overhead while enabling large speedups with little or no perceptual quality loss. Extensive experiments across multiple diffusion architectures and generation tasks show that TAP substantially improves the accuracy-efficiency frontier compared to fixed global predictors and caching-only baselines.
DriveScape: Towards High-Resolution Controllable Multi-View Driving Video Generation
Sep 11, 2024



Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. In this paper, we propose an end-to-end framework named DriveScape for multi-view, 3D condition-guided video generation. DriveScape not only streamlines the process by integrating camera data to ensure comprehensive spatial-temporal coverage, but also introduces a Bi-Directional Modulated Transformer module to effectively align 3D road structural information. As a result, our approach enables precise control over video generation, significantly enhancing realism and providing a robust solution for generating multi-view driving videos. Our framework achieves state-of-the-art results on the nuScenes dataset, demonstrating impressive generative quality metrics with an FID score of 8.34 and an FVD score of 76.39, as well as superior performance across various perception tasks. This paves the way for more accurate environmental simulations in autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/drivescapev1/index.html
Mask-adaptive Gated Convolution and Bi-directional Progressive Fusion Network for Depth Completion
Jan 15, 2024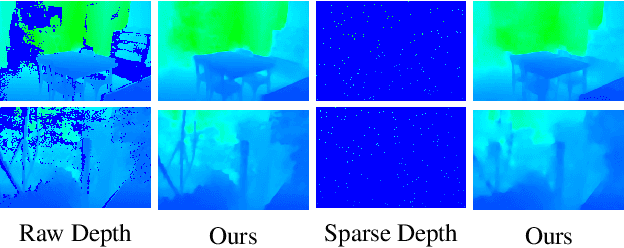



Depth completion is a critical task for handling depth images with missing pixels, which can negatively impact further applications. Recent approaches have utilized Convolutional Neural Networks (CNNs) to reconstruct depth images with the assistance of color images. However, vanilla convolution has non-negligible drawbacks in handling missing pixels. To solve this problem, we propose a new model for depth completion based on an encoder-decoder structure. Our model introduces two key components: the Mask-adaptive Gated Convolution (MagaConv) architecture and the Bi-directional Progressive Fusion (BP-Fusion) module. The MagaConv architecture is designed to acquire precise depth features by modulating convolution operations with iteratively updated masks, while the BP-Fusion module progressively integrates depth and color features, utilizing consecutive bi-directional fusion structures in a global perspective. Extensive experiments on popular benchmarks, including NYU-Depth V2, DIML, and SUN RGB-D, demonstrate the superiority of our model over state-of-the-art methods. We achieved remarkable performance in completing depth maps and outperformed existing approaches in terms of accuracy and reliability.
AGG-Net: Attention Guided Gated-convolutional Network for Depth Image Completion
Sep 04, 2023Recently, stereo vision based on lightweight RGBD cameras has been widely used in various fields. However, limited by the imaging principles, the commonly used RGB-D cameras based on TOF, structured light, or binocular vision acquire some invalid data inevitably, such as weak reflection, boundary shadows, and artifacts, which may bring adverse impacts to the follow-up work. In this paper, we propose a new model for depth image completion based on the Attention Guided Gated-convolutional Network (AGG-Net), through which more accurate and reliable depth images can be obtained from the raw depth maps and the corresponding RGB images. Our model employs a UNet-like architecture which consists of two parallel branches of depth and color features. In the encoding stage, an Attention Guided Gated-Convolution (AG-GConv) module is proposed to realize the fusion of depth and color features at different scales, which can effectively reduce the negative impacts of invalid depth data on the reconstruction. In the decoding stage, an Attention Guided Skip Connection (AG-SC) module is presented to avoid introducing too many depth-irrelevant features to the reconstruction. The experimental results demonstrate that our method outperforms the state-of-the-art methods on the popular benchmarks NYU-Depth V2, DIML, and SUN RGB-D.