 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaDrive: Instance-Aware Driving World Models for Realistic and Consistent Video Generation
Feb 03, 2026Autonomous driving relies on robust models trained on high-quality, large-scale multi-view driving videos. While world models offer a cost-effective solution for generating realistic driving videos, they struggle to maintain instance-level temporal consistency and spatial geometric fidelity. To address these challenges, we propose InstaDrive, a novel framework that enhances driving video realism through two key advancements: (1) Instance Flow Guider, which extracts and propagates instance features across frames to enforce temporal consistency, preserving instance identity over time. (2) Spatial Geometric Aligner, which improves spatial reasoning, ensures precise instance positioning, and explicitly models occlusion hierarchies. By incorporating these instance-aware mechanisms, InstaDrive achieves state-of-the-art video generation quality and enhances downstream autonomous driving tasks on the nuScenes dataset. Additionally, we utilize CARLA's autopilot to procedurally and stochastically simulate rare but safety-critical driving scenarios across diverse maps and regions, enabling rigorous safety evaluation for autonomous systems. Our project page is https://shanpoyang654.github.io/InstaDrive/page.html.
CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
Oct 09, 2025Generative models have been widely applied to world modeling for environment simulation and future state prediction. With advancements in autonomous driving, there is a growing demand not only for high-fidelity video generation under various controls, but also for producing diverse and meaningful information such as depth estimation. To address this, we propose CVD-STORM, a cross-view video diffusion model utilizing a spatial-temporal reconstruction Variational Autoencoder (VAE) that generates long-term, multi-view videos with 4D reconstruction capabilities under various control inputs. Our approach first fine-tunes the VAE with an auxiliary 4D reconstruction task, enhancing its ability to encode 3D structures and temporal dynamics. Subsequently, we integrate this VAE into the video diffusion process to significantly improve generation quality. Experimental results demonstrate that our model achieves substantial improvements in both FID and FVD metrics. Additionally, the jointly-trained Gaussian Splatting Decoder effectively reconstructs dynamic scenes, providing valuable geometric information for comprehensive scene understanding.
Physical Informed Driving World Model
Dec 13, 2024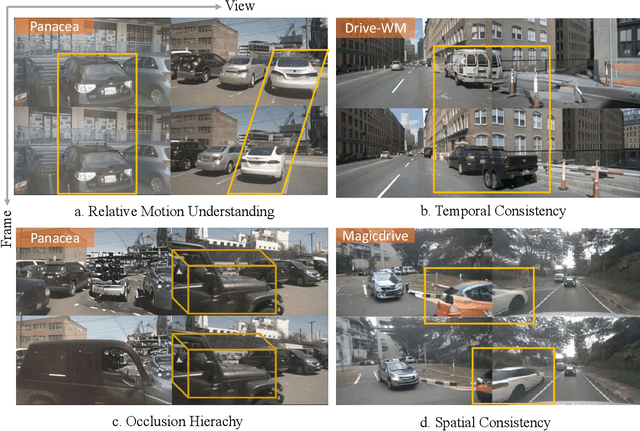
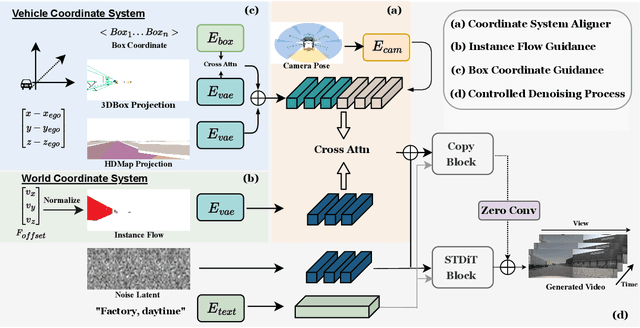
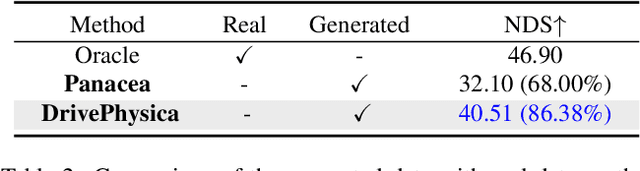
Autonomous driving requires robust perception models trained on high-quality, large-scale multi-view driving videos for tasks like 3D object detection, segmentation and trajectory prediction. While world models provide a cost-effective solution for generating realistic driving videos, challenges remain in ensuring these videos adhere to fundamental physical principles, such as relative and absolute motion, spatial relationship like occlusion and spatial consistency, and temporal consistency. To address these, we propose DrivePhysica, an innovative model designed to generate realistic multi-view driving videos that accurately adhere to essential physical principles through three key advancements: (1) a Coordinate System Aligner module that integrates relative and absolute motion features to enhance motion interpretation, (2) an Instance Flow Guidance module that ensures precise temporal consistency via efficient 3D flow extraction, and (3) a Box Coordinate Guidance module that improves spatial relationship understanding and accurately resolves occlusion hierarchies. Grounded in physical principles, we achieve state-of-the-art performance in driving video generation quality (3.96 FID and 38.06 FVD on the Nuscenes dataset) and downstream perception tasks. Our project homepage: https://metadrivescape.github.io/papers_project/DrivePhysica/page.html
Pysical Informed Driving World Model
Dec 11, 2024Autonomous driving requires robust perception models trained on high-quality, large-scale multi-view driving videos for tasks like 3D object detection, segmentation and trajectory prediction. While world models provide a cost-effective solution for generating realistic driving videos, challenges remain in ensuring these videos adhere to fundamental physical principles, such as relative and absolute motion, spatial relationship like occlusion and spatial consistency, and temporal consistency. To address these, we propose DrivePhysica, an innovative model designed to generate realistic multi-view driving videos that accurately adhere to essential physical principles through three key advancements: (1) a Coordinate System Aligner module that integrates relative and absolute motion features to enhance motion interpretation, (2) an Instance Flow Guidance module that ensures precise temporal consistency via efficient 3D flow extraction, and (3) a Box Coordinate Guidance module that improves spatial relationship understanding and accurately resolves occlusion hierarchies. Grounded in physical principles, we achieve state-of-the-art performance in driving video generation quality (3.96 FID and 38.06 FVD on the Nuscenes dataset) and downstream perception tasks. Our project homepage: https://metadrivescape.github.io/papers_project/DrivePhysica/page.html
InfinityDrive: Breaking Time Limits in Driving World Models
Dec 02, 2024



Autonomous driving systems struggle with complex scenarios due to limited access to diverse, extensive, and out-of-distribution driving data which are critical for safe navigation. World models offer a promising solution to this challenge; however, current driving world models are constrained by short time windows and limited scenario diversity. To bridge this gap, we introduce InfinityDrive, the first driving world model with exceptional generalization capabilities, delivering state-of-the-art performance in high fidelity, consistency, and diversity with minute-scale video generation. InfinityDrive introduces an efficient spatio-temporal co-modeling module paired with an extended temporal training strategy, enabling high-resolution (576$\times$1024) video generation with consistent spatial and temporal coherence. By incorporating memory injection and retention mechanisms alongside an adaptive memory curve loss to minimize cumulative errors, achieving consistent video generation lasting over 1500 frames (approximately 2 minutes). Comprehensive experiments in multiple datasets validate InfinityDrive's ability to generate complex and varied scenarios, highlighting its potential as a next-generation driving world model built for the evolving demands of autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/InfinityDrive/page.html
DriveScape: Towards High-Resolution Controllable Multi-View Driving Video Generation
Sep 11, 2024



Recent advancements in generative models have provided promising solutions for synthesizing realistic driving videos, which are crucial for training autonomous driving perception models. However, existing approaches often struggle with multi-view video generation due to the challenges of integrating 3D information while maintaining spatial-temporal consistency and effectively learning from a unified model. In this paper, we propose an end-to-end framework named DriveScape for multi-view, 3D condition-guided video generation. DriveScape not only streamlines the process by integrating camera data to ensure comprehensive spatial-temporal coverage, but also introduces a Bi-Directional Modulated Transformer module to effectively align 3D road structural information. As a result, our approach enables precise control over video generation, significantly enhancing realism and providing a robust solution for generating multi-view driving videos. Our framework achieves state-of-the-art results on the nuScenes dataset, demonstrating impressive generative quality metrics with an FID score of 8.34 and an FVD score of 76.39, as well as superior performance across various perception tasks. This paves the way for more accurate environmental simulations in autonomous driving. Our project homepage: https://metadrivescape.github.io/papers_project/drivescapev1/index.html
MyGo: Consistent and Controllable Multi-View Driving Video Generation with Camera Control
Sep 11, 2024


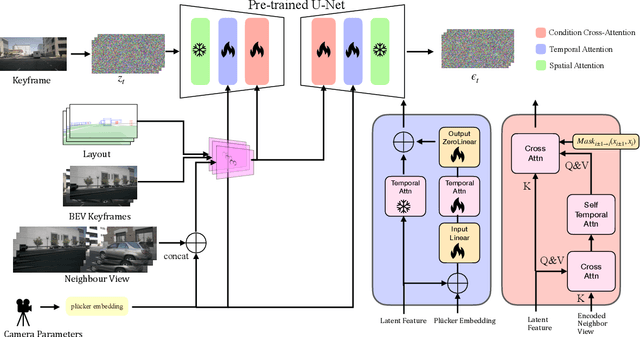
High-quality driving video generation is crucial for providing training data for autonomous driving models. However, current generative models rarely focus on enhancing camera motion control under multi-view tasks, which is essential for driving video generation. Therefore, we propose MyGo, an end-to-end framework for video generation, introducing motion of onboard cameras as conditions to make progress in camera controllability and multi-view consistency. MyGo employs additional plug-in modules to inject camera parameters into the pre-trained video diffusion model, which retains the extensive knowledge of the pre-trained model as much as possible. Furthermore, we use epipolar constraints and neighbor view information during the generation process of each view to enhance spatial-temporal consistency. Experimental results show that MyGo has achieved state-of-the-art results in both general camera-controlled video generation and multi-view driving video generation tasks, which lays the foundation for more accurate environment simulation in autonomous driving. Project page: https://metadrivescape.github.io/papers_project/MyGo/page.html
SGC-VQGAN: Towards Complex Scene Representation via Semantic Guided Clustering Codebook
Sep 09, 2024Vector quantization (VQ) is a method for deterministically learning features through discrete codebook representations. Recent works have utilized visual tokenizers to discretize visual regions for self-supervised representation learning. However, a notable limitation of these tokenizers is lack of semantics, as they are derived solely from the pretext task of reconstructing raw image pixels in an auto-encoder paradigm. Additionally, issues like imbalanced codebook distribution and codebook collapse can adversely impact performance due to inefficient codebook utilization. To address these challenges, We introduce SGC-VQGAN through Semantic Online Clustering method to enhance token semantics through Consistent Semantic Learning. Utilizing inference results from segmentation model , our approach constructs a temporospatially consistent semantic codebook, addressing issues of codebook collapse and imbalanced token semantics. Our proposed Pyramid Feature Learning pipeline integrates multi-level features to capture both image details and semantics simultaneously. As a result, SGC-VQGAN achieves SOTA performance in both reconstruction quality and various downstream tasks. Its simplicity, requiring no additional parameter learning, enables its direct application in downstream tasks, presenting significant potential.
PhysReaction: Physically Plausible Real-Time Humanoid Reaction Synthesis via Forward Dynamics Guided 4D Imitation
Apr 01, 2024



Humanoid Reaction Synthesis is pivotal for creating highly interactive and empathetic robots that can seamlessly integrate into human environments, enhancing the way we live, work, and communicate. However, it is difficult to learn the diverse interaction patterns of multiple humans and generate physically plausible reactions. The kinematics-based approaches face challenges, including issues like floating feet, sliding, penetration, and other problems that defy physical plausibility. The existing physics-based method often relies on kinematics-based methods to generate reference states, which struggle with the challenges posed by kinematic noise during action execution. Constrained by their reliance on diffusion models, these methods are unable to achieve real-time inference. In this work, we propose a Forward Dynamics Guided 4D Imitation method to generate physically plausible human-like reactions. The learned policy is capable of generating physically plausible and human-like reactions in real-time, significantly improving the speed(x33) and quality of reactions compared with the existing method. Our experiments on the InterHuman and Chi3D datasets, along with ablation studies, demonstrate the effectiveness of our approach.
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023



We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.