 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
Jan 21, 2026We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.
MARC: Memory-Augmented RL Token Compression for Efficient Video Understanding
Oct 09, 2025The rapid progress of large language models (LLMs) has laid the foundation for multimodal models. However, visual language models (VLMs) still face heavy computational costs when extended from images to videos due to high frame rates and long durations. Token compression is a promising solution, yet most existing training-free methods cause information loss and performance degradation. To overcome this, we propose \textbf{Memory-Augmented Reinforcement Learning-based Token Compression (MARC)}, which integrates structured retrieval and RL-based distillation. MARC adopts a \textit{retrieve-then-compress} strategy using a \textbf{Visual Memory Retriever (VMR)} to select key clips and a \textbf{Compression Group Relative Policy Optimization (C-GRPO)} framework to distil reasoning ability from a teacher to a student model. Experiments on six video benchmarks show that MARC achieves near-baseline accuracy using only one frame's tokens -- reducing visual tokens by \textbf{95\%}, GPU memory by \textbf{72\%}, and latency by \textbf{23.9\%}. This demonstrates its potential for efficient, real-time video understanding in resource-constrained settings such as video QA, surveillance, and autonomous driving.
MutualNeRF: Improve the Performance of NeRF under Limited Samples with Mutual Information Theory
May 16, 2025This paper introduces MutualNeRF, a framework enhancing Neural Radiance Field (NeRF) performance under limited samples using Mutual Information Theory. While NeRF excels in 3D scene synthesis, challenges arise with limited data and existing methods that aim to introduce prior knowledge lack theoretical support in a unified framework. We introduce a simple but theoretically robust concept, Mutual Information, as a metric to uniformly measure the correlation between images, considering both macro (semantic) and micro (pixel) levels. For sparse view sampling, we strategically select additional viewpoints containing more non-overlapping scene information by minimizing mutual information without knowing ground truth images beforehand. Our framework employs a greedy algorithm, offering a near-optimal solution. For few-shot view synthesis, we maximize the mutual information between inferred images and ground truth, expecting inferred images to gain more relevant information from known images. This is achieved by incorporating efficient, plug-and-play regularization terms. Experiments under limited samples show consistent improvement over state-of-the-art baselines in different settings, affirming the efficacy of our framework.
Ring Artifacts Correction Based on Global-Local Features Interaction Guidance in the Projection Domain
Apr 15, 2025Ring artifacts are common artifacts in CT imaging, typically caused by inconsistent responses of detector units to X-rays, resulting in stripe artifacts in the projection data. Under circular scanning mode, such artifacts manifest as concentric rings radiating from the center of rotation, severely degrading image quality. In the Radon transform domain, even if the object's density function is piecewise discontinuous in certain regions, the projection images remain nearly continuous in the angular direction, making the ideal projections exhibit a smooth global low-frequency characteristic. In practical scanning, the local disturbances of the same detector unit at different scanning angles lead to a prominent high-frequency locality of stripe artifacts. Existing studies generally model ring artifacts disturbances as fixed additive errors, which overlooks the dynamic variation of detector responses during practical scanning. However, the degree of detector response inconsistency is a function of the projection values, as revealed in our experiments, thereby requiring consideration of the interaction between global and local features in the process of stripe artifacts extraction and correction. Therefore, we propose a CT ring artifacts correction method based on global and local features in the projection domain. We employ the VSS block and Dense block to respectively correct the low-frequency sub-band, which capture the global correlations of the projection, and the high-frequency sub-band, which contain local stripe artifacts after wavelet decomposition. Specifically, the accuracy of artifacts correction is enhanced by the interaction guidance between global and local features. Extensive experiments demonstrate that our method achieves superior performance in both quantitative metrics and visual quality, verifying its robustness and practical applicability.
VideoMAP: Toward Scalable Mamba-based Video Autoregressive Pretraining
Mar 16, 2025Recent Mamba-based architectures for video understanding demonstrate promising computational efficiency and competitive performance, yet struggle with overfitting issues that hinder their scalability. To overcome this challenge, we introduce VideoMAP, a Hybrid Mamba-Transformer framework featuring a novel pre-training approach. VideoMAP uses a 4:1 Mamba-to-Transformer ratio, effectively balancing computational cost and model capacity. This architecture, combined with our proposed frame-wise masked autoregressive pre-training strategy, delivers significant performance gains when scaling to larger models. Additionally, VideoMAP exhibits impressive sample efficiency, significantly outperforming existing methods with less training data. Experiments show that VideoMAP outperforms existing models across various datasets, including Kinetics-400, Something-Something V2, Breakfast, and COIN. Furthermore, we demonstrate the potential of VideoMAP as a visual encoder for multimodal large language models, highlighting its ability to reduce memory usage and enable the processing of longer video sequences. The code is open-source at https://github.com/yunzeliu/MAP
ST-Think: How Multimodal Large Language Models Reason About 4D Worlds from Ego-Centric Videos
Mar 16, 2025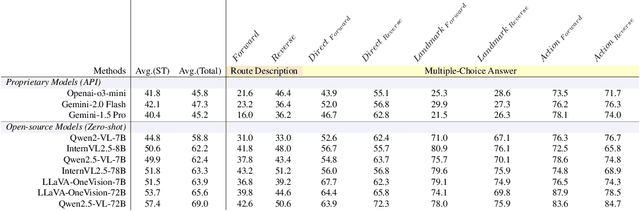
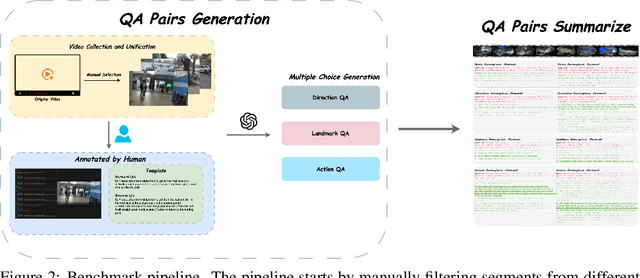
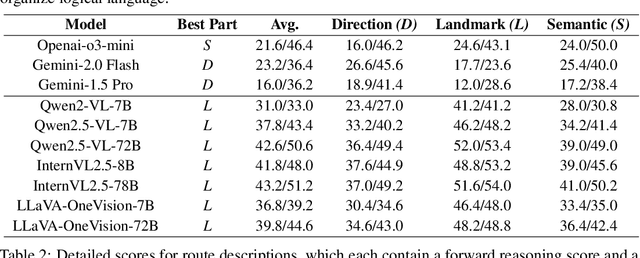

Humans excel at spatio-temporal reasoning, effortlessly interpreting dynamic visual events from an egocentric viewpoint. However, whether multimodal large language models (MLLMs) can similarly comprehend the 4D world remains uncertain. This paper explores multimodal spatio-temporal reasoning from an egocentric perspective, aiming to equip MLLMs with human-like reasoning capabilities. To support this objective, we introduce Ego-ST Bench, a novel benchmark containing over 5,000 question-answer pairs across four categories, systematically evaluating spatial, temporal, and integrated spatio-temporal reasoning. Additionally, we propose the ST-R1 Video model, a video-based reasoning model that incorporates reverse thinking into its reinforcement learning process, significantly enhancing performance. We combine long-chain-of-thought (long-CoT) supervised fine-tuning with Group Relative Policy Optimization (GRPO) reinforcement learning, achieving notable improvements with limited high-quality data. Ego-ST Bench and ST-R1 provide valuable insights and resources for advancing video-based spatio-temporal reasoning research.
MobileH2R: Learning Generalizable Human to Mobile Robot Handover Exclusively from Scalable and Diverse Synthetic Data
Jan 08, 2025



This paper introduces MobileH2R, a framework for learning generalizable vision-based human-to-mobile-robot (H2MR) handover skills. Unlike traditional fixed-base handovers, this task requires a mobile robot to reliably receive objects in a large workspace enabled by its mobility. Our key insight is that generalizable handover skills can be developed in simulators using high-quality synthetic data, without the need for real-world demonstrations. To achieve this, we propose a scalable pipeline for generating diverse synthetic full-body human motion data, an automated method for creating safe and imitation-friendly demonstrations, and an efficient 4D imitation learning method for distilling large-scale demonstrations into closed-loop policies with base-arm coordination. Experimental evaluations in both simulators and the real world show significant improvements (at least +15% success rate) over baseline methods in all cases. Experiments also validate that large-scale and diverse synthetic data greatly enhances robot learning, highlighting our scalable framework.
MAP: Unleashing Hybrid Mamba-Transformer Vision Backbone's Potential with Masked Autoregressive Pretraining
Oct 01, 2024
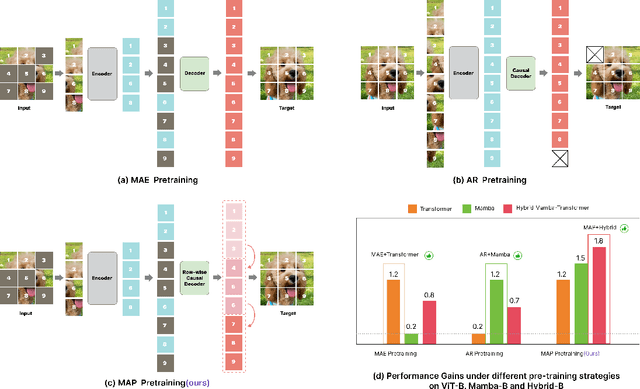
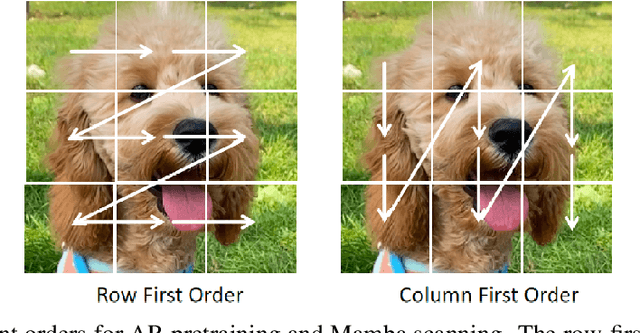
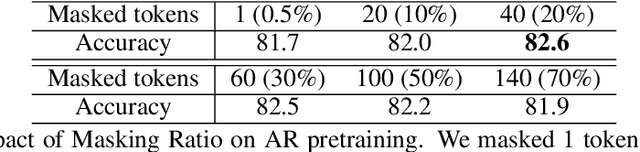
Mamba has achieved significant advantages in long-context modeling and autoregressive tasks, but its scalability with large parameters remains a major limitation in vision applications. pretraining is a widely used strategy to enhance backbone model performance. Although the success of Masked Autoencoder in Transformer pretraining is well recognized, it does not significantly improve Mamba's visual learning performance. We found that using the correct autoregressive pretraining can significantly boost the performance of the Mamba architecture. Based on this analysis, we propose Masked Autoregressive Pretraining (MAP) to pretrain a hybrid Mamba-Transformer vision backbone network. This strategy combines the strengths of both MAE and Autoregressive pretraining, improving the performance of Mamba and Transformer modules within a unified paradigm. Additionally, in terms of integrating Mamba and Transformer modules, we empirically found that inserting Transformer layers at regular intervals within Mamba layers can significantly enhance downstream task performance. Experimental results show that both the pure Mamba architecture and the hybrid Mamba-Transformer vision backbone network pretrained with MAP significantly outperform other pretraining strategies, achieving state-of-the-art performance. We validate the effectiveness of the method on both 2D and 3D datasets and provide detailed ablation studies to support the design choices for each component.
Physics-aware Hand-object Interaction Denoising
May 19, 2024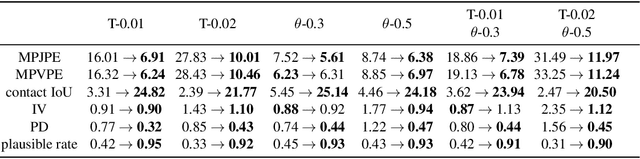
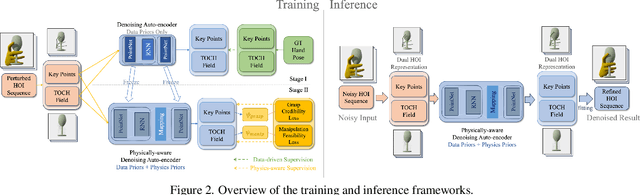


The credibility and practicality of a reconstructed hand-object interaction sequence depend largely on its physical plausibility. However, due to high occlusions during hand-object interaction, physical plausibility remains a challenging criterion for purely vision-based tracking methods. To address this issue and enhance the results of existing hand trackers, this paper proposes a novel physically-aware hand motion de-noising method. Specifically, we introduce two learned loss terms that explicitly capture two crucial aspects of physical plausibility: grasp credibility and manipulation feasibility. These terms are used to train a physically-aware de-noising network. Qualitative and quantitative experiments demonstrate that our approach significantly improves both fine-grained physical plausibility and overall pose accuracy, surpassing current state-of-the-art de-noising methods.
PhysReaction: Physically Plausible Real-Time Humanoid Reaction Synthesis via Forward Dynamics Guided 4D Imitation
Apr 01, 2024



Humanoid Reaction Synthesis is pivotal for creating highly interactive and empathetic robots that can seamlessly integrate into human environments, enhancing the way we live, work, and communicate. However, it is difficult to learn the diverse interaction patterns of multiple humans and generate physically plausible reactions. The kinematics-based approaches face challenges, including issues like floating feet, sliding, penetration, and other problems that defy physical plausibility. The existing physics-based method often relies on kinematics-based methods to generate reference states, which struggle with the challenges posed by kinematic noise during action execution. Constrained by their reliance on diffusion models, these methods are unable to achieve real-time inference. In this work, we propose a Forward Dynamics Guided 4D Imitation method to generate physically plausible human-like reactions. The learned policy is capable of generating physically plausible and human-like reactions in real-time, significantly improving the speed(x33) and quality of reactions compared with the existing method. Our experiments on the InterHuman and Chi3D datasets, along with ablation studies, demonstrate the effectiveness of our approach.