 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID: Learned Undersampling-Adaptive Consistency-Guided Inference with Deterministic Flow Matching for Sparse-View CT Reconstruction
Jun 15, 2026Sparse-view CT reduces radiation dose and scanning time by acquiring fewer projection views, but angular undersampling makes reconstruction severely ill-posed, causing streak artifacts, structural blurring, and loss of fine details. Existing supervised methods are often tied to specific sampling settings, whereas generative methods may introduce anatomically inconsistent hallucination-like structures under severe undersampling. We propose Lucid, a sparsity-adaptive, consistency-guided reconstruction framework based on a Flow Matching generative prior for sparse-view CT. Lucid is trained only on high-quality CT images to learn a continuous transport between a Gaussian distribution and the high-quality CT image distribution, independent of view sampling. During inference, the sampling sparsity level is explicitly incorporated to adapt the generative trajectory of a single pretrained model. Specifically, Lucid constructs a degradation-matched initial state by sparsity-weighted fusion of the sparse-view FBP image and Gaussian noise, performs sparsity-modulated Flow Matching updates, and applies projection-domain data-consistency correction after each prior update. Experiments under multiple sparse-view settings show that Lucid achieves stable reconstruction performance across different sampling densities, improves image quality and structural fidelity, and reduces the risk of hallucination-like structures in generative sparse-view CT reconstruction.
OpenRTLSet: A Fully Open-Source Dataset for Large Language Model-based Verilog Module Design
Jun 09, 2026OpenRTLSet introduces the largest fully open-source dataset for hardware design, offering over 131,000 diverse Verilog code samples to the research community and industry. Our dataset uniquely combines Verilog code from GitHub repositories (102k modules), VHDL translations (5k modules), and synthesizable C/C++ translations (24k modules), all freely accessible without proprietary restrictions. Using the reasoning model DeepSeek-R1, we generated paired natural language descriptions for each code sample, enabling fine-tuning of various language model families (e.g., Qwen and Granite) for Verilog code generation. Our dataset explores multiple options, including Verilator-generated C++ files as additional context during labeling, quantization techniques (INT4 vs. BF16), and performance differences across model sizes (7B-32B parameters). OpenRTLSet demonstrates that open-source approaches can achieve superior performance in hardware design tasks, establishing a new foundation for accessible research and commercial use in this domain.
* Accepted by ICLAD'25
General Explicit Network (GEN): A novel deep learning architecture for solving partial differential equations
Apr 02, 2026Machine learning, especially physics-informed neural networks (PINNs) and their neural network variants, has been widely used to solve problems involving partial differential equations (PDEs). The successful deployment of such methods beyond academic research remains limited. For example, PINN methods primarily consider discrete point-to-point fitting and fail to account for the potential properties of real solutions. The adoption of continuous activation functions in these approaches leads to local characteristics that align with the equation solutions while resulting in poor extensibility and robustness. A general explicit network (GEN) that implements point-to-function PDE solving is proposed in this paper. The "function" component can be constructed based on our prior knowledge of the original PDEs through corresponding basis functions for fitting. The experimental results demonstrate that this approach enables solutions with high robustness and strong extensibility to be obtained.
Beyond Fixed Inference: Quantitative Flow Matching for Adaptive Image Denoising
Apr 02, 2026Diffusion and flow-based generative models have shown strong potential for image restoration. However, image denoising under unknown and varying noise conditions remains challenging, because the learned vector fields may become inconsistent across different noise levels, leading to degraded restoration quality under mismatch between training and inference. To address this issue, we propose a quantitative flow matching framework for adaptive image denoising. The method first estimates the input noise level from local pixel statistics, and then uses this quantitative estimate to adapt the inference trajectory, including the starting point, the number of integration steps, and the step-size schedule. In this way, the denoising process is better aligned with the actual corruption level of each input, reducing unnecessary computation for lightly corrupted images while providing sufficient refinement for heavily degraded ones. By coupling quantitative noise estimation with noise-adaptive flow inference, the proposed method improves both restoration accuracy and inference efficiency. Extensive experiments on natural, medical, and microscopy images demonstrate its robustness and strong generalization across diverse noise levels and imaging conditions.
Supervised makeup transfer with a curated dataset: Decoupling identity and makeup features for enhanced transformation
Jan 31, 2026Diffusion models have recently shown strong progress in generative tasks, offering a more stable alternative to GAN-based approaches for makeup transfer. Existing methods often suffer from limited datasets, poor disentanglement between identity and makeup features, and weak controllability. To address these issues, we make three contributions. First, we construct a curated high-quality dataset using a train-generate-filter-retrain strategy that combines synthetic, realistic, and filtered samples to improve diversity and fidelity. Second, we design a diffusion-based framework that disentangles identity and makeup features, ensuring facial structure and skin tone are preserved while applying accurate and diverse cosmetic styles. Third, we propose a text-guided mechanism that allows fine-grained and region-specific control, enabling users to modify eyes, lips, or face makeup with natural language prompts. Experiments on benchmarks and real-world scenarios demonstrate improvements in fidelity, identity preservation, and flexibility. Examples of our dataset can be found at: https://makeup-adapter.github.io.
Ring Artifacts Correction Based on Global-Local Features Interaction Guidance in the Projection Domain
Apr 15, 2025Ring artifacts are common artifacts in CT imaging, typically caused by inconsistent responses of detector units to X-rays, resulting in stripe artifacts in the projection data. Under circular scanning mode, such artifacts manifest as concentric rings radiating from the center of rotation, severely degrading image quality. In the Radon transform domain, even if the object's density function is piecewise discontinuous in certain regions, the projection images remain nearly continuous in the angular direction, making the ideal projections exhibit a smooth global low-frequency characteristic. In practical scanning, the local disturbances of the same detector unit at different scanning angles lead to a prominent high-frequency locality of stripe artifacts. Existing studies generally model ring artifacts disturbances as fixed additive errors, which overlooks the dynamic variation of detector responses during practical scanning. However, the degree of detector response inconsistency is a function of the projection values, as revealed in our experiments, thereby requiring consideration of the interaction between global and local features in the process of stripe artifacts extraction and correction. Therefore, we propose a CT ring artifacts correction method based on global and local features in the projection domain. We employ the VSS block and Dense block to respectively correct the low-frequency sub-band, which capture the global correlations of the projection, and the high-frequency sub-band, which contain local stripe artifacts after wavelet decomposition. Specifically, the accuracy of artifacts correction is enhanced by the interaction guidance between global and local features. Extensive experiments demonstrate that our method achieves superior performance in both quantitative metrics and visual quality, verifying its robustness and practical applicability.
A Comprehensive Scatter Correction Model for Micro-Focus Dual-Source Imaging Systems: Combining Ambient, Cross, and Forward Scatter
Mar 18, 2025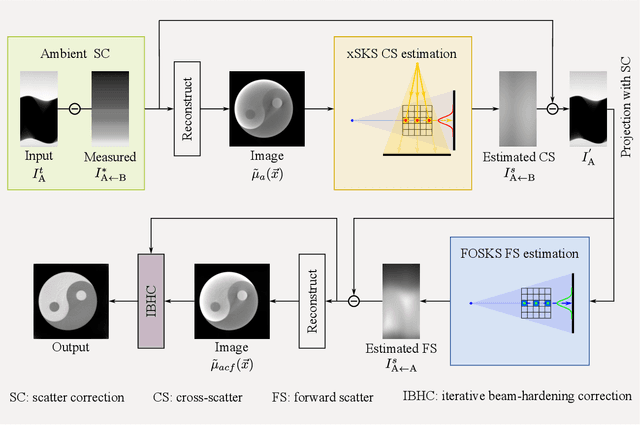



Compared to single-source imaging systems, dual-source imaging systems equipped with two cross-distributed scanning beams significantly enhance temporal resolution and capture more comprehensive object scanning information. Nevertheless, the interaction between the two scanning beams introduces more complex scatter signals into the acquired projection data. Existing methods typically model these scatter signals as the sum of cross-scatter and forward scatter, with cross-scatter estimation limited to single-scatter along primary paths. Through experimental measurements on our selfdeveloped micro-focus dual-source imaging system, we observed that the peak ratio of hardware-induced ambient scatter to single-source projection intensity can even exceed 60%, a factor often overlooked in conventional models. To address this limitation, we propose a more comprehensive model that decomposes the total scatter signals into three distinct components: ambient scatter, cross-scatter, and forward scatter. Furthermore, we introduce a cross-scatter kernel superposition (xSKS) module to enhance the accuracy of cross-scatter estimation by modeling both single and multiple crossscatter events along non-primary paths. Additionally, we employ a fast object-adaptive scatter kernel superposition (FOSKS) module for efficient forward scatter estimation. In Monte Carlo (MC) simulation experiments performed on a custom-designed waterbone phantom, our model demonstrated remarkable superiority, achieving a scatter-toprimary-weighted mean absolute percentage error (SPMAPE) of 1.32%, significantly lower than the 12.99% attained by the state-of-the-art method. Physical experiments further validate the superior performance of our model in correcting scatter artifacts.
First performance of hybrid spectra CT reconstruction: a general Spectrum-Model-Aided Reconstruction Technique (SMART)
Oct 24, 2024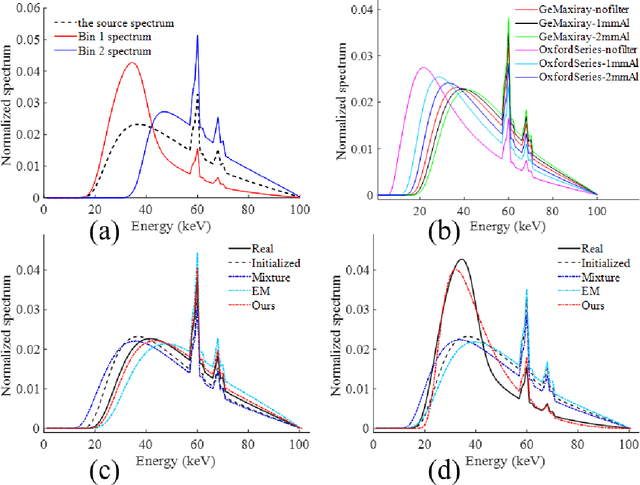
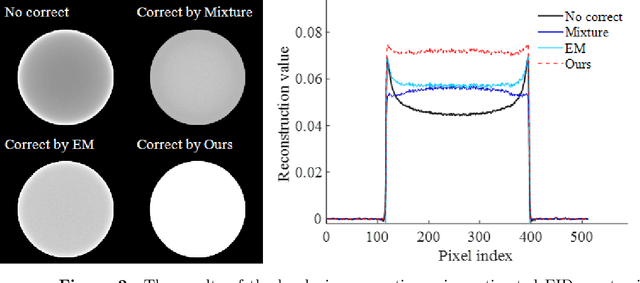
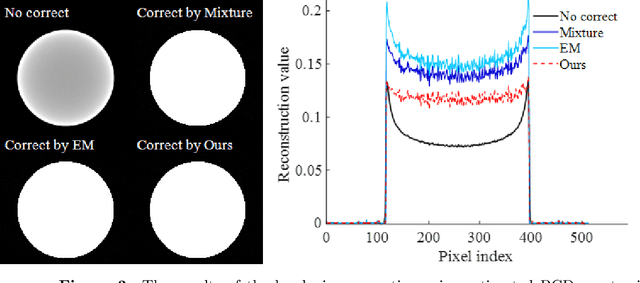
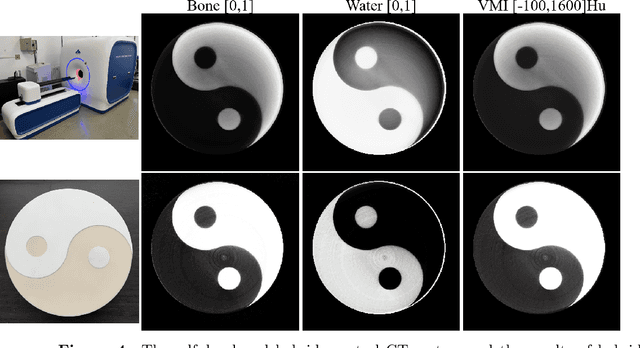
Hybrid spectral CT integrates energy integrating detectors (EID) and photon counting detectors (PCD) into a single system, combining the large field-of-view advantage of EID with the high energy and spatial resolution of PCD. This represents a new research direction in spectral CT imaging. However, the different imaging principles and inconsistent geometric paths of the two detectors make it difficult to reconstruct images using data from hybrid detectors. In addition, the quality reconstructed images considering spectrum is affected by the accuracy of spectral estimation and the scattered photons. In this work, Firstly, we propose a general hybrid spectral reconstruction method that takes into account both the spectral CT imaging principles of the two different detectors and the influence of scattered photons in the forward process modelling. Furthermore, we also apply volume fraction constraints to the results reconstructed from the two detector data. By alternately solving the spectral estimation and the spectral image reconstruction by the ADMM method, the estimated spectra and the reconstructed images reinforce each other, thus improving the accuracy of the spectral estimation and the quality of the reconstructed images. The proposed method is the first to achieve hybrid spectral CT reconstruction for both detectors, allowing simultaneous recovery of spectrum and image reconstruction from hybrid spectral data containing scattering. In addition, the method is also applicable to spectral CT imaging using a single type of detector. We validated the effectiveness of the proposed method through numerical experiments and successfully performed the first hybrid spectral CT reconstruction experiment on our self-developed hybrid spectral CT system.
Iterative approach to reconstructing neural disparity fields from light-field data
Jul 22, 2024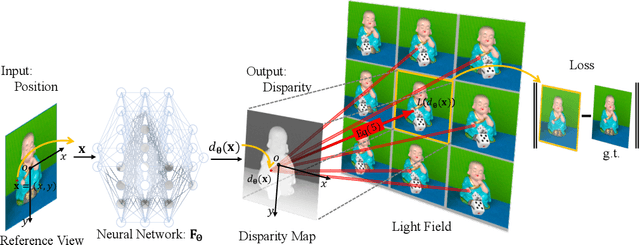
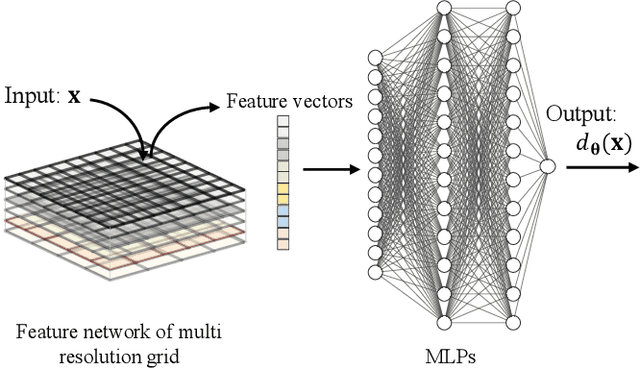
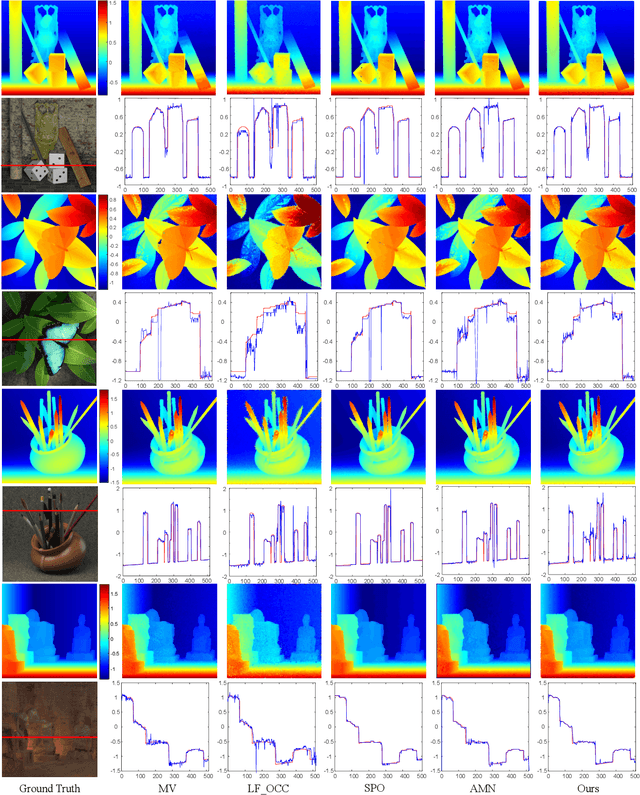
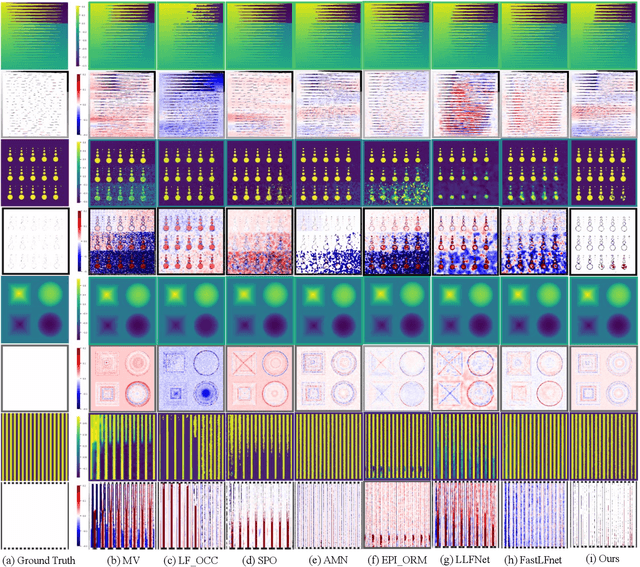
This study proposes a neural disparity field (NDF) that establishes an implicit, continuous representation of scene disparity based on a neural field and an iterative approach to address the inverse problem of NDF reconstruction from light-field data. NDF enables seamless and precise characterization of disparity variations in three-dimensional scenes and can discretize disparity at any arbitrary resolution, overcoming the limitations of traditional disparity maps that are prone to sampling errors and interpolation inaccuracies. The proposed NDF network architecture utilizes hash encoding combined with multilayer perceptrons to capture detailed disparities in texture levels, thereby enhancing its ability to represent the geometric information of complex scenes. By leveraging the spatial-angular consistency inherent in light-field data, a differentiable forward model to generate a central view image from the light-field data is developed. Based on the forward model, an optimization scheme for the inverse problem of NDF reconstruction using differentiable propagation operators is established. Furthermore, an iterative solution method is adopted to reconstruct the NDF in the optimization scheme, which does not require training datasets and applies to light-field data captured by various acquisition methods. Experimental results demonstrate that high-quality NDF can be reconstructed from light-field data using the proposed method. High-resolution disparity can be effectively recovered by NDF, demonstrating its capability for the implicit, continuous representation of scene disparities.
Ray-driven Spectral CT Reconstruction Based on Neural Base-Material Fields
Apr 10, 2024
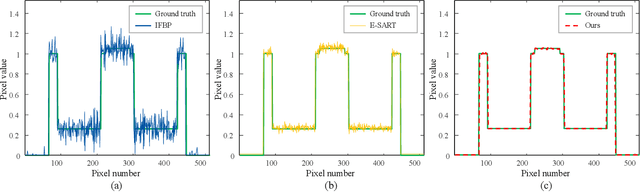


In spectral CT reconstruction, the basis materials decomposition involves solving a large-scale nonlinear system of integral equations, which is highly ill-posed mathematically. This paper proposes a model that parameterizes the attenuation coefficients of the object using a neural field representation, thereby avoiding the complex calculations of pixel-driven projection coefficient matrices during the discretization process of line integrals. It introduces a lightweight discretization method for line integrals based on a ray-driven neural field, enhancing the accuracy of the integral approximation during the discretization process. The basis materials are represented as continuous vector-valued implicit functions to establish a neural field parameterization model for the basis materials. The auto-differentiation framework of deep learning is then used to solve the implicit continuous function of the neural base-material fields. This method is not limited by the spatial resolution of reconstructed images, and the network has compact and regular properties. Experimental validation shows that our method performs exceptionally well in addressing the spectral CT reconstruction. Additionally, it fulfils the requirements for the generation of high-resolution reconstruction images.