 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctoT2I: A Self-Evolving Agentic Text-to-Image Router
Jun 01, 2026The explosive growth of Text-to-Image (T2I) models, from large-scale versions to lightweight, real-time ones, now faces diminishing marginal returns from single-model scaling. Agentic T2I methods emerged to alleviate this bottleneck by using multiple models. However, existing agentic T2I methods suffer from three key challenges: reliance on expensive handcrafted priors or human annotations, rigid single-path decision mechanisms, and a neglect of inference efficiency. To address these challenges, we introduce OctoT2I, a novel agentic framework that reformulates the T2I task as a joint optimization of generation quality and inference efficiency. OctoT2I implements a stateful, multi-round routing strategy that adaptively selects the most suitable tool based on its knowledge and memory. This strategy is enabled by a knowledge base built from scratch by our novel Self-Evolving Mechanism. This mechanism, which requires no human supervision, first autonomously defines foundational Conceptual Dimensions (eg, style, color, count) and then intelligently explores their combinations via an iterative" Propose--Solve--Evaluate--Learn"(PSEL) loop. The PSEL loop efficiently discovers each tool's capability frontier, driving continuous improvement without external guidance. Extensive experiments demonstrate that OctoT2I achieves competitive performance (0.96) on GenEval while delivering a 90.3% inference speedup and a 56.6% energy-efficiency gain over the leading baseline (Flow-GRPO), striking an exceptional balance between performance and efficiency. Code and models will be made available.
ContextGuard: Structured Self-Auditing for Context Learning in Language Models
May 26, 2026Recent benchmarks reveal that despite strong reasoning capabilities, large language models (LLMs) still struggle to faithfully apply complex contextual knowledge. These failures are often not wholesale reasoning collapses: in context-rich tasks, models may follow the central reasoning path while missing peripheral, persistent, or format-sensitive requirements.
Context-CoT: Enhancing Context Learning via High-Quality Reasoning Synthesis
May 25, 2026While LLMs excel at reasoning over prompts using static pretrained knowledge, they struggle significantly with context learning-the ability to dynamically extract, internalize, and apply new knowledge from complex, task-specific contexts. Recent evaluations on the CL-Bench reveal a critical capability gap: frontier models solve only 17.2% of context-dependent tasks on average.
VISD: Enhancing Video Reasoning via Structured Self-Distillation
May 07, 2026Training VideoLLMs for complex reasoning remains challenging due to sparse sequence level rewards and the lack of fine grained credit assignment over long, temporally grounded reasoning trajectories. While reinforcement learning with verifiable rewards (RLVR) provides reliable supervision, it fails to capture token level contributions, leading to inefficient learning. Conversely, existing self distillation methods offer dense supervision but lack structure and diagnostic specificity, and often interact unstably with reinforcement learning. In this work, we propose VISD, a structured self distillation framework that introduces diagnostically meaningful privileged information for video reasoning. VISD employs a video aware judge model to decompose reasoning quality into multiple dimensions, including answer correctness, logical consistency, and spatio-temporal grounding, and uses this structured feedback to guide a teacher policy for token level supervision. To stably integrate dense supervision with RL, we introduce a direction magnitude decoupling mechanism, where rollout level advantages computed from rewards determine update direction, while structured privileged signals modulate token level update magnitudes. This design enables semantically aligned and fine grained credit assignment, improving both reasoning faithfulness and training efficiency. Additionally, VISD incorporates curriculum scheduling and EMA based teacher stabilization to support robust optimization over long video sequences. Experiments on diverse benchmarks show that VISD consistently outperforms strong baselines, improving answer accuracy and spatio temporal grounding quality. Notably, VISD reaches these gains with nearly 2x faster convergence in optimization steps, highlighting the effectiveness of structured self supervision in improving both performance and sample efficiency for VideoLLMs.
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
May 05, 2026Reinforcement learning is crucial for aligning large language models to perform complex reasoning tasks. However, current algorithms such as Group Relative Policy Optimization suffer from coarse grained, sequence level credit assignment, which severely struggles to isolate pivotal reasoning steps within long Chain of Thought generations. Furthermore, the standard unbounded Kullback Leibler divergence penalty induces severe gradient instability and mode seeking conservatism, ultimately stifling the discovery of novel reasoning trajectories. To overcome these limitations, we introduce Distribution Guided Policy Optimization, a novel critic free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty.
Beyond Fixed Inference: Quantitative Flow Matching for Adaptive Image Denoising
Apr 02, 2026Diffusion and flow-based generative models have shown strong potential for image restoration. However, image denoising under unknown and varying noise conditions remains challenging, because the learned vector fields may become inconsistent across different noise levels, leading to degraded restoration quality under mismatch between training and inference. To address this issue, we propose a quantitative flow matching framework for adaptive image denoising. The method first estimates the input noise level from local pixel statistics, and then uses this quantitative estimate to adapt the inference trajectory, including the starting point, the number of integration steps, and the step-size schedule. In this way, the denoising process is better aligned with the actual corruption level of each input, reducing unnecessary computation for lightly corrupted images while providing sufficient refinement for heavily degraded ones. By coupling quantitative noise estimation with noise-adaptive flow inference, the proposed method improves both restoration accuracy and inference efficiency. Extensive experiments on natural, medical, and microscopy images demonstrate its robustness and strong generalization across diverse noise levels and imaging conditions.
LogicGraph : Benchmarking Multi-Path Logical Reasoning via Neuro-Symbolic Generation and Verification
Feb 24, 2026Evaluations of large language models (LLMs) primarily emphasize convergent logical reasoning, where success is defined by producing a single correct proof. However, many real-world reasoning problems admit multiple valid derivations, requiring models to explore diverse logical paths rather than committing to one route. To address this limitation, we introduce LogicGraph, the first benchmark aimed to systematically evaluate multi-path logical reasoning, constructed via a neuro-symbolic framework that leverages backward logic generation and semantic instantiation. This pipeline yields solver-verified reasoning problems formalized by high-depth multi-path reasoning and inherent logical distractions, where each instance is associated with an exhaustive set of minimal proofs. We further propose a reference-free evaluation framework to rigorously assess model performance in both convergent and divergent regimes. Experiments on state-of-the-art language models reveal a common limitation: models tend to commit early to a single route and fail to explore alternatives, and the coverage gap grows substantially with reasoning depth. LogicGraph exposes this divergence gap and provides actionable insights to motivate future improvements. Our code and data will be released at https://github.com/kkkkarry/LogicGraph.
T2MBench: A Benchmark for Out-of-Distribution Text-to-Motion Generation
Feb 14, 2026Most existing evaluations of text-to-motion generation focus on in-distribution textual inputs and a limited set of evaluation criteria, which restricts their ability to systematically assess model generalization and motion generation capabilities under complex out-of-distribution (OOD) textual conditions. To address this limitation, we propose a benchmark specifically designed for OOD text-to-motion evaluation, which includes a comprehensive analysis of 14 representative baseline models and the two datasets derived from evaluation results. Specifically, we construct an OOD prompt dataset consisting of 1,025 textual descriptions. Based on this prompt dataset, we introduce a unified evaluation framework that integrates LLM-based Evaluation, Multi-factor Motion evaluation, and Fine-grained Accuracy Evaluation. Our experimental results reveal that while different baseline models demonstrate strengths in areas such as text-to-motion semantic alignment, motion generalizability, and physical quality, most models struggle to achieve strong performance with Fine-grained Accuracy Evaluation. These findings highlight the limitations of existing methods in OOD scenarios and offer practical guidance for the design and evaluation of future production-level text-to-motion models.
TalkPhoto: A Versatile Training-Free Conversational Assistant for Intelligent Image Editing
Jan 05, 2026Thanks to the powerful language comprehension capabilities of Large Language Models (LLMs), existing instruction-based image editing methods have introduced Multimodal Large Language Models (MLLMs) to promote information exchange between instructions and images, ensuring the controllability and flexibility of image editing. However, these frameworks often build a multi-instruction dataset to train the model to handle multiple editing tasks, which is not only time-consuming and labor-intensive but also fails to achieve satisfactory results. In this paper, we present TalkPhoto, a versatile training-free image editing framework that facilitates precise image manipulation through conversational interaction. We instruct the open-source LLM with a specially designed prompt template to analyze user needs after receiving instructions and hierarchically invoke existing advanced editing methods, all without additional training. Moreover, we implement a plug-and-play and efficient invocation of image editing methods, allowing complex and unseen editing tasks to be integrated into the current framework, achieving stable and high-quality editing results. Extensive experiments demonstrate that our method not only provides more accurate invocation with fewer token consumption but also achieves higher editing quality across various image editing tasks.
Neural Collapse in Test-Time Adaptation
Dec 11, 2025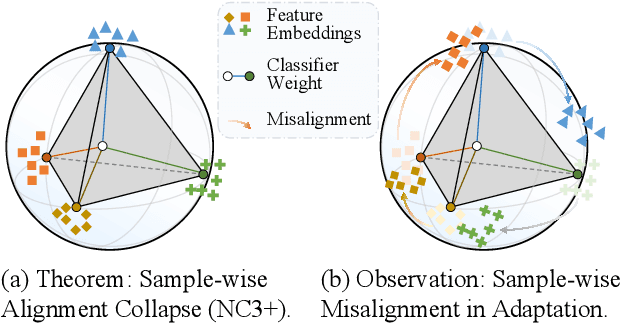
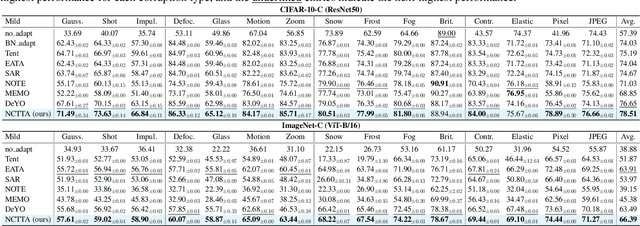
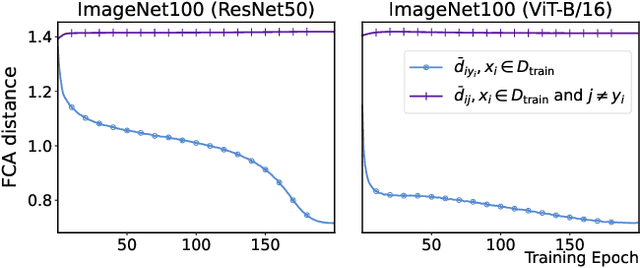
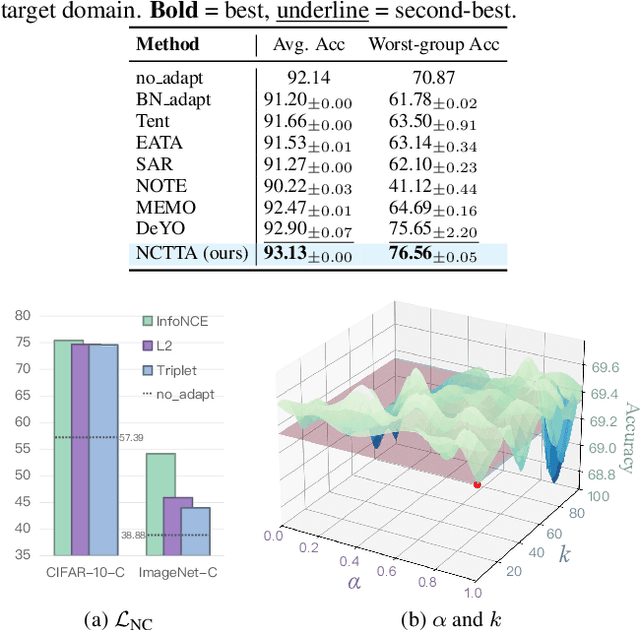
Test-Time Adaptation (TTA) enhances model robustness to out-of-distribution (OOD) data by updating the model online during inference, yet existing methods lack theoretical insights into the fundamental causes of performance degradation under domain shifts. Recently, Neural Collapse (NC) has been proposed as an emergent geometric property of deep neural networks (DNNs), providing valuable insights for TTA. In this work, we extend NC to the sample-wise level and discover a novel phenomenon termed Sample-wise Alignment Collapse (NC3+), demonstrating that a sample's feature embedding, obtained by a trained model, aligns closely with the corresponding classifier weight. Building on NC3+, we identify that the performance degradation stems from sample-wise misalignment in adaptation which exacerbates under larger distribution shifts. This indicates the necessity of realigning the feature embeddings with their corresponding classifier weights. However, the misalignment makes pseudo-labels unreliable under domain shifts. To address this challenge, we propose NCTTA, a novel feature-classifier alignment method with hybrid targets to mitigate the impact of unreliable pseudo-labels, which blends geometric proximity with predictive confidence. Extensive experiments demonstrate the effectiveness of NCTTA in enhancing robustness to domain shifts. For example, NCTTA outperforms Tent by 14.52% on ImageNet-C.