 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation
Dec 12, 2024



As virtual reality gains popularity, the demand for controllable creation of immersive and dynamic omnidirectional videos (ODVs) is increasing. While previous text-to-ODV generation methods achieve impressive results, they struggle with content inaccuracies and inconsistencies due to reliance solely on textual inputs. Although recent motion control techniques provide fine-grained control for video generation, directly applying these methods to ODVs often results in spatial distortion and unsatisfactory performance, especially with complex spherical motions. To tackle these challenges, we propose OmniDrag, the first approach enabling both scene- and object-level motion control for accurate, high-quality omnidirectional image-to-video generation. Building on pretrained video diffusion models, we introduce an omnidirectional control module, which is jointly fine-tuned with temporal attention layers to effectively handle complex spherical motion. In addition, we develop a novel spherical motion estimator that accurately extracts motion-control signals and allows users to perform drag-style ODV generation by simply drawing handle and target points. We also present a new dataset, named Move360, addressing the scarcity of ODV data with large scene and object motions. Experiments demonstrate the significant superiority of OmniDrag in achieving holistic scene-level and fine-grained object-level control for ODV generation. The project page is available at https://lwq20020127.github.io/OmniDrag.
RealOSR: Latent Unfolding Boosting Diffusion-based Real-world Omnidirectional Image Super-Resolution
Dec 11, 2024



Omnidirectional image super-resolution (ODISR) aims to upscale low-resolution (LR) omnidirectional images (ODIs) to high-resolution (HR), addressing the growing demand for detailed visual content across a $180^{\circ}\times360^{\circ}$ viewport. Existing methods are limited by simple degradation assumptions (e.g., bicubic downsampling), which fail to capture the complex, unknown real-world degradation processes. Recent diffusion-based approaches suffer from slow inference due to their hundreds of sampling steps and frequent pixel-latent space conversions. To tackle these challenges, in this paper, we propose RealOSR, a novel diffusion-based approach for real-world ODISR (Real-ODISR) with single-step diffusion denoising. To sufficiently exploit the input information, RealOSR introduces a lightweight domain alignment module, which facilitates the efficient injection of LR ODI into the single-step latent denoising. Additionally, to better utilize the rich semantic and multi-scale feature modeling ability of denoising UNet, we develop a latent unfolding module that simulates the gradient descent process directly in latent space. Experimental results demonstrate that RealOSR outperforms previous methods in both ODI recovery quality and efficiency. Compared to the recent state-of-the-art diffusion-based ODISR method, OmniSSR, RealOSR achieves significant improvements in visual quality and over \textbf{200$\times$} inference acceleration. Our code and models will be released.
Face2Face: Label-driven Facial Retouching Restoration
Apr 22, 2024



With the popularity of social media platforms such as Instagram and TikTok, and the widespread availability and convenience of retouching tools, an increasing number of individuals are utilizing these tools to beautify their facial photographs. This poses challenges for fields that place high demands on the authenticity of photographs, such as identity verification and social media. By altering facial images, users can easily create deceptive images, leading to the dissemination of false information. This may pose challenges to the reliability of identity verification systems and social media, and even lead to online fraud. To address this issue, some work has proposed makeup removal methods, but they still lack the ability to restore images involving geometric deformations caused by retouching. To tackle the problem of facial retouching restoration, we propose a framework, dubbed Face2Face, which consists of three components: a facial retouching detector, an image restoration model named FaceR, and a color correction module called Hierarchical Adaptive Instance Normalization (H-AdaIN). Firstly, the facial retouching detector predicts a retouching label containing three integers, indicating the retouching methods and their corresponding degrees. Then FaceR restores the retouched image based on the predicted retouching label. Finally, H-AdaIN is applied to address the issue of color shift arising from diffusion models. Extensive experiments demonstrate the effectiveness of our framework and each module.
OmniSSR: Zero-shot Omnidirectional Image Super-Resolution using Stable Diffusion Model
Apr 17, 2024



Omnidirectional images (ODIs) are commonly used in real-world visual tasks, and high-resolution ODIs help improve the performance of related visual tasks. Most existing super-resolution methods for ODIs use end-to-end learning strategies, resulting in inferior realness of generated images and a lack of effective out-of-domain generalization capabilities in training methods. Image generation methods represented by diffusion model provide strong priors for visual tasks and have been proven to be effectively applied to image restoration tasks. Leveraging the image priors of the Stable Diffusion (SD) model, we achieve omnidirectional image super-resolution with both fidelity and realness, dubbed as OmniSSR. Firstly, we transform the equirectangular projection (ERP) images into tangent projection (TP) images, whose distribution approximates the planar image domain. Then, we use SD to iteratively sample initial high-resolution results. At each denoising iteration, we further correct and update the initial results using the proposed Octadecaplex Tangent Information Interaction (OTII) and Gradient Decomposition (GD) technique to ensure better consistency. Finally, the TP images are transformed back to obtain the final high-resolution results. Our method is zero-shot, requiring no training or fine-tuning. Experiments of our method on two benchmark datasets demonstrate the effectiveness of our proposed method.
Hybrid Transformer and CNN Attention Network for Stereo Image Super-resolution
May 09, 2023



Multi-stage strategies are frequently employed in image restoration tasks. While transformer-based methods have exhibited high efficiency in single-image super-resolution tasks, they have not yet shown significant advantages over CNN-based methods in stereo super-resolution tasks. This can be attributed to two key factors: first, current single-image super-resolution transformers are unable to leverage the complementary stereo information during the process; second, the performance of transformers is typically reliant on sufficient data, which is absent in common stereo-image super-resolution algorithms. To address these issues, we propose a Hybrid Transformer and CNN Attention Network (HTCAN), which utilizes a transformer-based network for single-image enhancement and a CNN-based network for stereo information fusion. Furthermore, we employ a multi-patch training strategy and larger window sizes to activate more input pixels for super-resolution. We also revisit other advanced techniques, such as data augmentation, data ensemble, and model ensemble to reduce overfitting and data bias. Finally, our approach achieved a score of 23.90dB and emerged as the winner in Track 1 of the NTIRE 2023 Stereo Image Super-Resolution Challenge.
OPDN: Omnidirectional Position-aware Deformable Network for Omnidirectional Image Super-Resolution
Apr 26, 2023
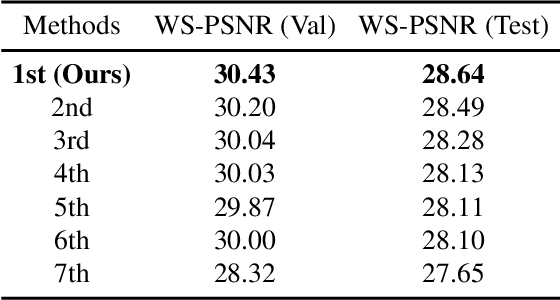

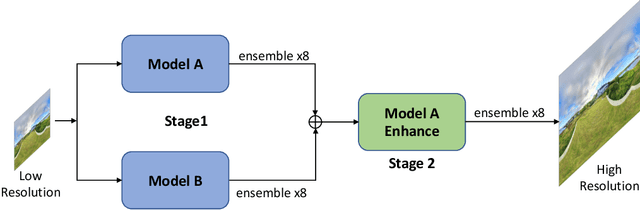
360{\deg} omnidirectional images have gained research attention due to their immersive and interactive experience, particularly in AR/VR applications. However, they suffer from lower angular resolution due to being captured by fisheye lenses with the same sensor size for capturing planar images. To solve the above issues, we propose a two-stage framework for 360{\deg} omnidirectional image superresolution. The first stage employs two branches: model A, which incorporates omnidirectional position-aware deformable blocks (OPDB) and Fourier upsampling, and model B, which adds a spatial frequency fusion module (SFF) to model A. Model A aims to enhance the feature extraction ability of 360{\deg} image positional information, while Model B further focuses on the high-frequency information of 360{\deg} images. The second stage performs same-resolution enhancement based on the structure of model A with a pixel unshuffle operation. In addition, we collected data from YouTube to improve the fitting ability of the transformer, and created pseudo low-resolution images using a degradation network. Our proposed method achieves superior performance and wins the NTIRE 2023 challenge of 360{\deg} omnidirectional image super-resolution.