 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
MUSAR: Exploring Multi-Subject Customization from Single-Subject Dataset via Attention Routing
May 05, 2025

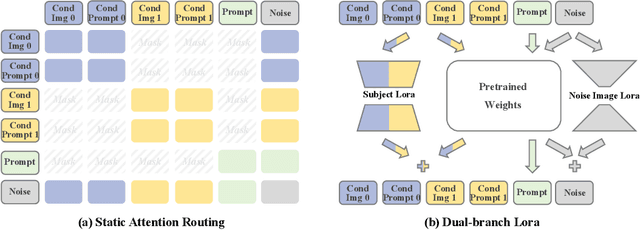
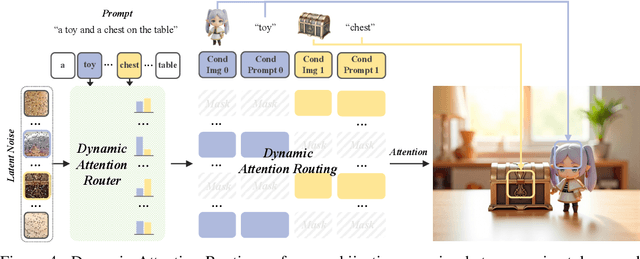
Current multi-subject customization approaches encounter two critical challenges: the difficulty in acquiring diverse multi-subject training data, and attribute entanglement across different subjects. To bridge these gaps, we propose MUSAR - a simple yet effective framework to achieve robust multi-subject customization while requiring only single-subject training data. Firstly, to break the data limitation, we introduce debiased diptych learning. It constructs diptych training pairs from single-subject images to facilitate multi-subject learning, while actively correcting the distribution bias introduced by diptych construction via static attention routing and dual-branch LoRA. Secondly, to eliminate cross-subject entanglement, we introduce dynamic attention routing mechanism, which adaptively establishes bijective mappings between generated images and conditional subjects. This design not only achieves decoupling of multi-subject representations but also maintains scalable generalization performance with increasing reference subjects. Comprehensive experiments demonstrate that our MUSAR outperforms existing methods - even those trained on multi-subject dataset - in image quality, subject consistency, and interaction naturalness, despite requiring only single-subject dataset.
DreamO: A Unified Framework for Image Customization
Apr 23, 2025Recently, extensive research on image customization (e.g., identity, subject, style, background, etc.) demonstrates strong customization capabilities in large-scale generative models. However, most approaches are designed for specific tasks, restricting their generalizability to combine different types of condition. Developing a unified framework for image customization remains an open challenge. In this paper, we present DreamO, an image customization framework designed to support a wide range of tasks while facilitating seamless integration of multiple conditions. Specifically, DreamO utilizes a diffusion transformer (DiT) framework to uniformly process input of different types. During training, we construct a large-scale training dataset that includes various customization tasks, and we introduce a feature routing constraint to facilitate the precise querying of relevant information from reference images. Additionally, we design a placeholder strategy that associates specific placeholders with conditions at particular positions, enabling control over the placement of conditions in the generated results. Moreover, we employ a progressive training strategy consisting of three stages: an initial stage focused on simple tasks with limited data to establish baseline consistency, a full-scale training stage to comprehensively enhance the customization capabilities, and a final quality alignment stage to correct quality biases introduced by low-quality data. Extensive experiments demonstrate that the proposed DreamO can effectively perform various image customization tasks with high quality and flexibly integrate different types of control conditions.
Consistent Human Image and Video Generation with Spatially Conditioned Diffusion
Dec 19, 2024



Consistent human-centric image and video synthesis aims to generate images or videos with new poses while preserving appearance consistency with a given reference image, which is crucial for low-cost visual content creation. Recent advances based on diffusion models typically rely on separate networks for reference appearance feature extraction and target visual generation, leading to inconsistent domain gaps between references and targets. In this paper, we frame the task as a spatially-conditioned inpainting problem, where the target image is inpainted to maintain appearance consistency with the reference. This approach enables the reference features to guide the generation of pose-compliant targets within a unified denoising network, thereby mitigating domain gaps. Additionally, to better maintain the reference appearance information, we impose a causal feature interaction framework, in which reference features can only query from themselves, while target features can query appearance information from both the reference and the target. To further enhance computational efficiency and flexibility, in practical implementation, we decompose the spatially-conditioned generation process into two stages: reference appearance extraction and conditioned target generation. Both stages share a single denoising network, with interactions restricted to self-attention layers. This proposed method ensures flexible control over the appearance of generated human images and videos. By fine-tuning existing base diffusion models on human video data, our method demonstrates strong generalization to unseen human identities and poses without requiring additional per-instance fine-tuning. Experimental results validate the effectiveness of our approach, showing competitive performance compared to existing methods for consistent human image and video synthesis.
OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation
Dec 12, 2024



As virtual reality gains popularity, the demand for controllable creation of immersive and dynamic omnidirectional videos (ODVs) is increasing. While previous text-to-ODV generation methods achieve impressive results, they struggle with content inaccuracies and inconsistencies due to reliance solely on textual inputs. Although recent motion control techniques provide fine-grained control for video generation, directly applying these methods to ODVs often results in spatial distortion and unsatisfactory performance, especially with complex spherical motions. To tackle these challenges, we propose OmniDrag, the first approach enabling both scene- and object-level motion control for accurate, high-quality omnidirectional image-to-video generation. Building on pretrained video diffusion models, we introduce an omnidirectional control module, which is jointly fine-tuned with temporal attention layers to effectively handle complex spherical motion. In addition, we develop a novel spherical motion estimator that accurately extracts motion-control signals and allows users to perform drag-style ODV generation by simply drawing handle and target points. We also present a new dataset, named Move360, addressing the scarcity of ODV data with large scene and object motions. Experiments demonstrate the significant superiority of OmniDrag in achieving holistic scene-level and fine-grained object-level control for ODV generation. The project page is available at https://lwq20020127.github.io/OmniDrag.
ReVideo: Remake a Video with Motion and Content Control
May 22, 2024Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing. In this paper, we present a novel attempt to Remake a Video (ReVideo) which stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience. ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine. Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations. Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories. Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.
Diffusion-Based Hierarchical Image Steganography
May 19, 2024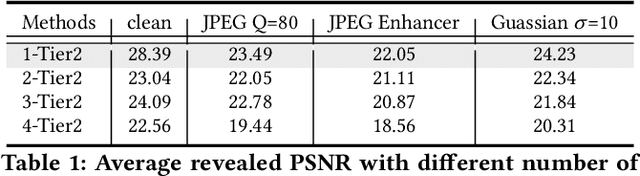
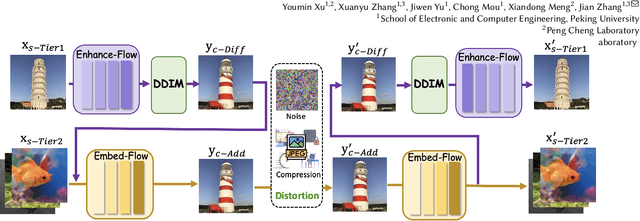


This paper introduces Hierarchical Image Steganography, a novel method that enhances the security and capacity of embedding multiple images into a single container using diffusion models. HIS assigns varying levels of robustness to images based on their importance, ensuring enhanced protection against manipulation. It adaptively exploits the robustness of the Diffusion Model alongside the reversibility of the Flow Model. The integration of Embed-Flow and Enhance-Flow improves embedding efficiency and image recovery quality, respectively, setting HIS apart from conventional multi-image steganography techniques. This innovative structure can autonomously generate a container image, thereby securely and efficiently concealing multiple images and text. Rigorous subjective and objective evaluations underscore our advantage in analytical resistance, robustness, and capacity, illustrating its expansive applicability in content safeguarding and privacy fortification.
DiffEditor: Boosting Accuracy and Flexibility on Diffusion-based Image Editing
Feb 04, 2024



Large-scale Text-to-Image (T2I) diffusion models have revolutionized image generation over the last few years. Although owning diverse and high-quality generation capabilities, translating these abilities to fine-grained image editing remains challenging. In this paper, we propose DiffEditor to rectify two weaknesses in existing diffusion-based image editing: (1) in complex scenarios, editing results often lack editing accuracy and exhibit unexpected artifacts; (2) lack of flexibility to harmonize editing operations, e.g., imagine new content. In our solution, we introduce image prompts in fine-grained image editing, cooperating with the text prompt to better describe the editing content. To increase the flexibility while maintaining content consistency, we locally combine stochastic differential equation (SDE) into the ordinary differential equation (ODE) sampling. In addition, we incorporate regional score-based gradient guidance and a time travel strategy into the diffusion sampling, further improving the editing quality. Extensive experiments demonstrate that our method can efficiently achieve state-of-the-art performance on various fine-grained image editing tasks, including editing within a single image (e.g., object moving, resizing, and content dragging) and across images (e.g., appearance replacing and object pasting). Our source code is released at https://github.com/MC-E/DragonDiffusion.
360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model
Jan 12, 2024



360-degree panoramic videos recently attract more interest in both studies and applications, courtesy of the heightened immersive experiences they engender. Due to the expensive cost of capturing 360-degree panoramic videos, generating desirable panoramic videos by given prompts is urgently required. Recently, the emerging text-to-video (T2V) diffusion methods demonstrate notable effectiveness in standard video generation. However, due to the significant gap in content and motion patterns between panoramic and standard videos, these methods encounter challenges in yielding satisfactory 360-degree panoramic videos. In this paper, we propose a controllable panorama video generation pipeline named 360-Degree Video Diffusion model (360DVD) for generating panoramic videos based on the given prompts and motion conditions. Concretely, we introduce a lightweight module dubbed 360-Adapter and assisted 360 Enhancement Techniques to transform pre-trained T2V models for 360-degree video generation. We further propose a new panorama dataset named WEB360 consisting of 360-degree video-text pairs for training 360DVD, addressing the absence of captioned panoramic video datasets. Extensive experiments demonstrate the superiority and effectiveness of 360DVD for panorama video generation. The code and dataset will be released soon.
Neural Video Fields Editing
Dec 12, 2023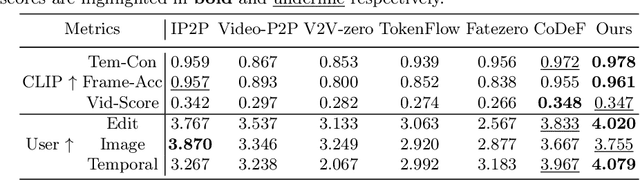
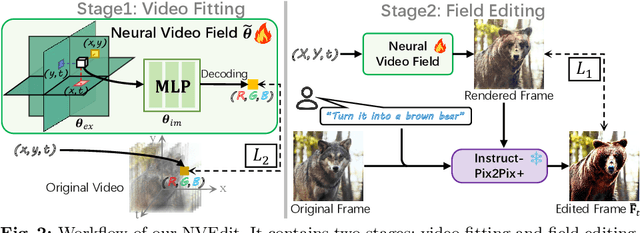


Diffusion models have revolutionized text-driven video editing. However, applying these methods to real-world editing encounters two significant challenges: (1) the rapid increase in graphics memory demand as the number of frames grows, and (2) the inter-frame inconsistency in edited videos. To this end, we propose NVEdit, a novel text-driven video editing framework designed to mitigate memory overhead and improve consistent editing for real-world long videos. Specifically, we construct a neural video field, powered by tri-plane and sparse grid, to enable encoding long videos with hundreds of frames in a memory-efficient manner. Next, we update the video field through off-the-shelf Text-to-Image (T2I) models to impart text-driven editing effects. A progressive optimization strategy is developed to preserve original temporal priors. Importantly, both the neural video field and T2I model are adaptable and replaceable, thus inspiring future research. Experiments demonstrate that our approach successfully edits hundreds of frames with impressive inter-frame consistency.