 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
SVG-T2I: Scaling Up Text-to-Image Latent Diffusion Model Without Variational Autoencoder
Dec 12, 2025Visual generation grounded in Visual Foundation Model (VFM) representations offers a highly promising unified pathway for integrating visual understanding, perception, and generation. Despite this potential, training large-scale text-to-image diffusion models entirely within the VFM representation space remains largely unexplored. To bridge this gap, we scale the SVG (Self-supervised representations for Visual Generation) framework, proposing SVG-T2I to support high-quality text-to-image synthesis directly in the VFM feature domain. By leveraging a standard text-to-image diffusion pipeline, SVG-T2I achieves competitive performance, reaching 0.75 on GenEval and 85.78 on DPG-Bench. This performance validates the intrinsic representational power of VFMs for generative tasks. We fully open-source the project, including the autoencoder and generation model, together with their training, inference, evaluation pipelines, and pre-trained weights, to facilitate further research in representation-driven visual generation.
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Mar 18, 2025Diffusion models have demonstrated remarkable success in various image generation tasks, but their performance is often limited by the uniform processing of inputs across varying conditions and noise levels. To address this limitation, we propose a novel approach that leverages the inherent heterogeneity of the diffusion process. Our method, DiffMoE, introduces a batch-level global token pool that enables experts to access global token distributions during training, promoting specialized expert behavior. To unleash the full potential of the diffusion process, DiffMoE incorporates a capacity predictor that dynamically allocates computational resources based on noise levels and sample complexity. Through comprehensive evaluation, DiffMoE achieves state-of-the-art performance among diffusion models on ImageNet benchmark, substantially outperforming both dense architectures with 3x activated parameters and existing MoE approaches while maintaining 1x activated parameters. The effectiveness of our approach extends beyond class-conditional generation to more challenging tasks such as text-to-image generation, demonstrating its broad applicability across different diffusion model applications. Project Page: https://shiml20.github.io/DiffMoE/
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning
Jan 08, 2025



Text-to-video generation has made remarkable advancements through diffusion models. However, Multi-Concept Video Customization (MCVC) remains a significant challenge. We identify two key challenges in this task: 1) the identity decoupling problem, where directly adopting existing customization methods inevitably mix attributes when handling multiple concepts simultaneously, and 2) the scarcity of high-quality video-entity pairs, which is crucial for training such a model that represents and decouples various concepts well. To address these challenges, we introduce ConceptMaster, an innovative framework that effectively tackles the critical issues of identity decoupling while maintaining concept fidelity in customized videos. Specifically, we introduce a novel strategy of learning decoupled multi-concept embeddings that are injected into the diffusion models in a standalone manner, which effectively guarantees the quality of customized videos with multiple identities, even for highly similar visual concepts. To further overcome the scarcity of high-quality MCVC data, we carefully establish a data construction pipeline, which enables systematic collection of precise multi-concept video-entity data across diverse concepts. A comprehensive benchmark is designed to validate the effectiveness of our model from three critical dimensions: concept fidelity, identity decoupling ability, and video generation quality across six different concept composition scenarios. Extensive experiments demonstrate that our ConceptMaster significantly outperforms previous approaches for this task, paving the way for generating personalized and semantically accurate videos across multiple concepts.
Consistent Human Image and Video Generation with Spatially Conditioned Diffusion
Dec 19, 2024



Consistent human-centric image and video synthesis aims to generate images or videos with new poses while preserving appearance consistency with a given reference image, which is crucial for low-cost visual content creation. Recent advances based on diffusion models typically rely on separate networks for reference appearance feature extraction and target visual generation, leading to inconsistent domain gaps between references and targets. In this paper, we frame the task as a spatially-conditioned inpainting problem, where the target image is inpainted to maintain appearance consistency with the reference. This approach enables the reference features to guide the generation of pose-compliant targets within a unified denoising network, thereby mitigating domain gaps. Additionally, to better maintain the reference appearance information, we impose a causal feature interaction framework, in which reference features can only query from themselves, while target features can query appearance information from both the reference and the target. To further enhance computational efficiency and flexibility, in practical implementation, we decompose the spatially-conditioned generation process into two stages: reference appearance extraction and conditioned target generation. Both stages share a single denoising network, with interactions restricted to self-attention layers. This proposed method ensures flexible control over the appearance of generated human images and videos. By fine-tuning existing base diffusion models on human video data, our method demonstrates strong generalization to unseen human identities and poses without requiring additional per-instance fine-tuning. Experimental results validate the effectiveness of our approach, showing competitive performance compared to existing methods for consistent human image and video synthesis.
3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
Dec 10, 2024

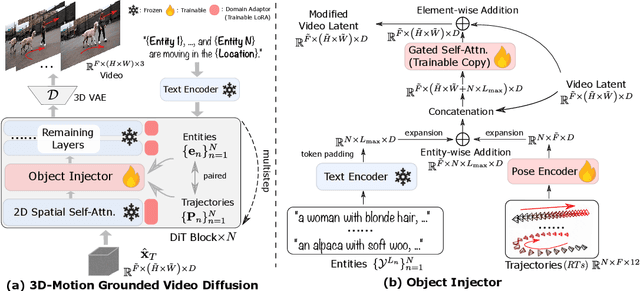
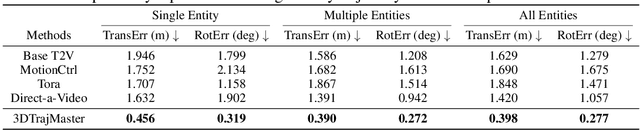
This paper aims to manipulate multi-entity 3D motions in video generation. Previous methods on controllable video generation primarily leverage 2D control signals to manipulate object motions and have achieved remarkable synthesis results. However, 2D control signals are inherently limited in expressing the 3D nature of object motions. To overcome this problem, we introduce 3DTrajMaster, a robust controller that regulates multi-entity dynamics in 3D space, given user-desired 6DoF pose (location and rotation) sequences of entities. At the core of our approach is a plug-and-play 3D-motion grounded object injector that fuses multiple input entities with their respective 3D trajectories through a gated self-attention mechanism. In addition, we exploit an injector architecture to preserve the video diffusion prior, which is crucial for generalization ability. To mitigate video quality degradation, we introduce a domain adaptor during training and employ an annealed sampling strategy during inference. To address the lack of suitable training data, we construct a 360-Motion Dataset, which first correlates collected 3D human and animal assets with GPT-generated trajectory and then captures their motion with 12 evenly-surround cameras on diverse 3D UE platforms. Extensive experiments show that 3DTrajMaster sets a new state-of-the-art in both accuracy and generalization for controlling multi-entity 3D motions. Project page: http://fuxiao0719.github.io/projects/3dtrajmaster
SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
Dec 10, 2024



Recent advancements in video diffusion models have shown exceptional abilities in simulating real-world dynamics and maintaining 3D consistency. This progress inspires us to investigate the potential of these models to ensure dynamic consistency across various viewpoints, a highly desirable feature for applications such as virtual filming. Unlike existing methods focused on multi-view generation of single objects for 4D reconstruction, our interest lies in generating open-world videos from arbitrary viewpoints, incorporating 6 DoF camera poses. To achieve this, we propose a plug-and-play module that enhances a pre-trained text-to-video model for multi-camera video generation, ensuring consistent content across different viewpoints. Specifically, we introduce a multi-view synchronization module to maintain appearance and geometry consistency across these viewpoints. Given the scarcity of high-quality training data, we design a hybrid training scheme that leverages multi-camera images and monocular videos to supplement Unreal Engine-rendered multi-camera videos. Furthermore, our method enables intriguing extensions, such as re-rendering a video from novel viewpoints. We also release a multi-view synchronized video dataset, named SynCamVideo-Dataset. Project page: https://jianhongbai.github.io/SynCamMaster/.
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
Jul 08, 2024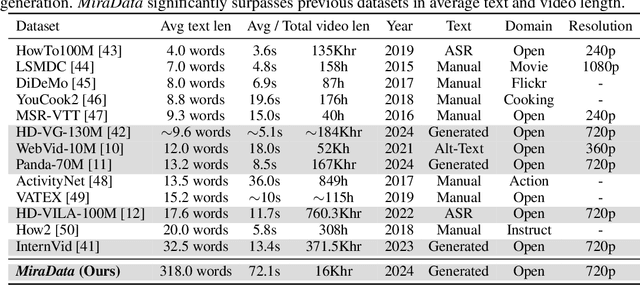
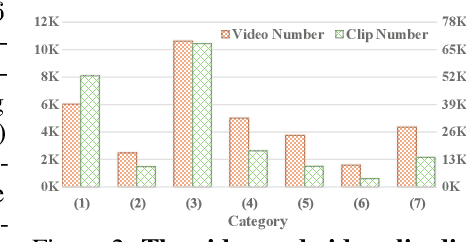


Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips. GPT-4V is employed to annotate structured captions, providing detailed descriptions from four different perspectives along with a summarized dense caption. To better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. MiraBench includes 150 evaluation prompts and 17 metrics covering temporal consistency, motion strength, 3D consistency, visual quality, text-video alignment, and distribution similarity. To demonstrate the utility and effectiveness of MiraData, we conduct experiments using our DiT-based video generation model, MiraDiT. The experimental results on MiraBench demonstrate the superiority of MiraData, especially in motion strength.