 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-DFM: A Remote Sensing Distributed Foundation Model for Diverse Downstream Tasks
Jun 11, 2024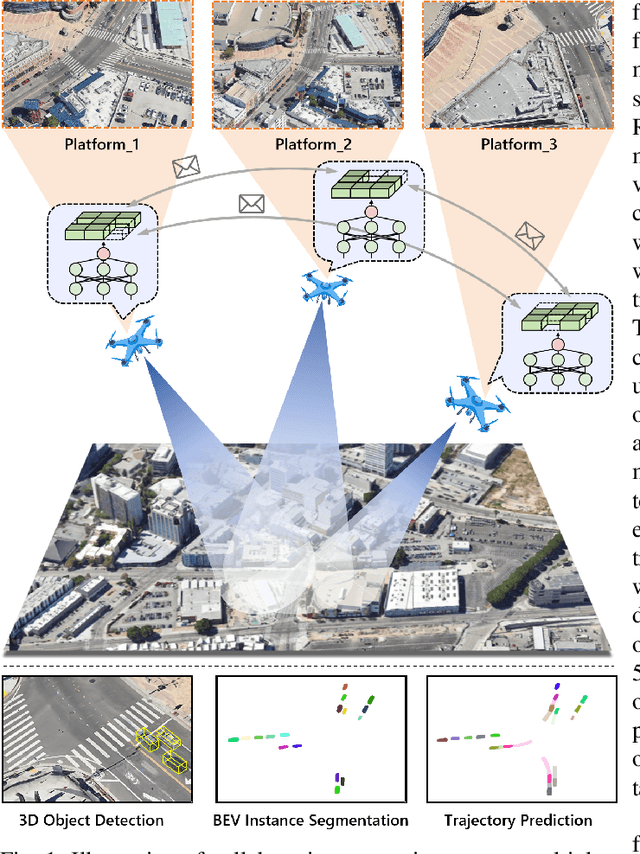
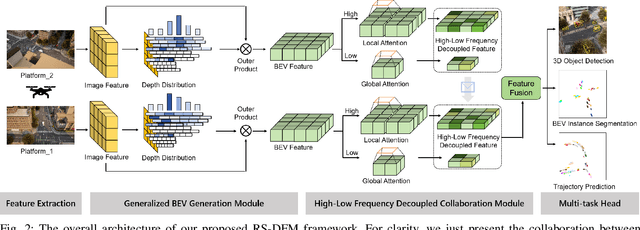
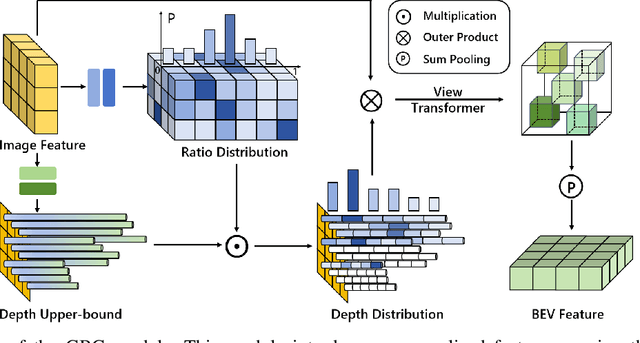
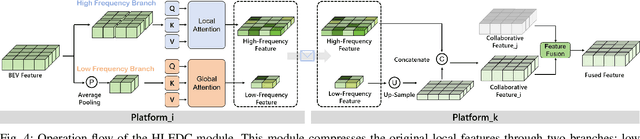
Remote sensing lightweight foundation models have achieved notable success in online perception within remote sensing. However, their capabilities are restricted to performing online inference solely based on their own observations and models, thus lacking a comprehensive understanding of large-scale remote sensing scenarios. To overcome this limitation, we propose a Remote Sensing Distributed Foundation Model (RS-DFM) based on generalized information mapping and interaction. This model can realize online collaborative perception across multiple platforms and various downstream tasks by mapping observations into a unified space and implementing a task-agnostic information interaction strategy. Specifically, we leverage the ground-based geometric prior of remote sensing oblique observations to transform the feature mapping from absolute depth estimation to relative depth estimation, thereby enhancing the model's ability to extract generalized features across diverse heights and perspectives. Additionally, we present a dual-branch information compression module to decouple high-frequency and low-frequency feature information, achieving feature-level compression while preserving essential task-agnostic details. In support of our research, we create a multi-task simulation dataset named AirCo-MultiTasks for multi-UAV collaborative observation. We also conduct extensive experiments, including 3D object detection, instance segmentation, and trajectory prediction. The numerous results demonstrate that our RS-DFM achieves state-of-the-art performance across various downstream tasks.
UVCPNet: A UAV-Vehicle Collaborative Perception Network for 3D Object Detection
Jun 07, 2024With the advancement of collaborative perception, the role of aerial-ground collaborative perception, a crucial component, is becoming increasingly important. The demand for collaborative perception across different perspectives to construct more comprehensive perceptual information is growing. However, challenges arise due to the disparities in the field of view between cross-domain agents and their varying sensitivity to information in images. Additionally, when we transform image features into Bird's Eye View (BEV) features for collaboration, we need accurate depth information. To address these issues, we propose a framework specifically designed for aerial-ground collaboration. First, to mitigate the lack of datasets for aerial-ground collaboration, we develop a virtual dataset named V2U-COO for our research. Second, we design a Cross-Domain Cross-Adaptation (CDCA) module to align the target information obtained from different domains, thereby achieving more accurate perception results. Finally, we introduce a Collaborative Depth Optimization (CDO) module to obtain more precise depth estimation results, leading to more accurate perception outcomes. We conduct extensive experiments on both our virtual dataset and a public dataset to validate the effectiveness of our framework. Our experiments on the V2U-COO dataset and the DAIR-V2X dataset demonstrate that our method improves detection accuracy by 6.1% and 2.7%, respectively.
UCDNet: Multi-UAV Collaborative 3D Object Detection Network by Reliable Feature Mapping
Jun 07, 2024Multi-UAV collaborative 3D object detection can perceive and comprehend complex environments by integrating complementary information, with applications encompassing traffic monitoring, delivery services and agricultural management. However, the extremely broad observations in aerial remote sensing and significant perspective differences across multiple UAVs make it challenging to achieve precise and consistent feature mapping from 2D images to 3D space in multi-UAV collaborative 3D object detection paradigm. To address the problem, we propose an unparalleled camera-based multi-UAV collaborative 3D object detection paradigm called UCDNet. Specifically, the depth information from the UAVs to the ground is explicitly utilized as a strong prior to provide a reference for more accurate and generalizable feature mapping. Additionally, we design a homologous points geometric consistency loss as an auxiliary self-supervision, which directly influences the feature mapping module, thereby strengthening the global consistency of multi-view perception. Experiments on AeroCollab3D and CoPerception-UAVs datasets show our method increases 4.7% and 10% mAP respectively compared to the baseline, which demonstrates the superiority of UCDNet.
Using Unreliable Pseudo-Labels for Label-Efficient Semantic Segmentation
Jun 04, 2023The crux of label-efficient semantic segmentation is to produce high-quality pseudo-labels to leverage a large amount of unlabeled or weakly labeled data. A common practice is to select the highly confident predictions as the pseudo-ground-truths for each pixel, but it leads to a problem that most pixels may be left unused due to their unreliability. However, we argue that every pixel matters to the model training, even those unreliable and ambiguous pixels. Intuitively, an unreliable prediction may get confused among the top classes, however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative key to those most unlikely categories. Therefore, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative keys, and manage to train the model with all candidate pixels. Considering the training evolution, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.
Balancing Logit Variation for Long-tailed Semantic Segmentation
Jun 03, 2023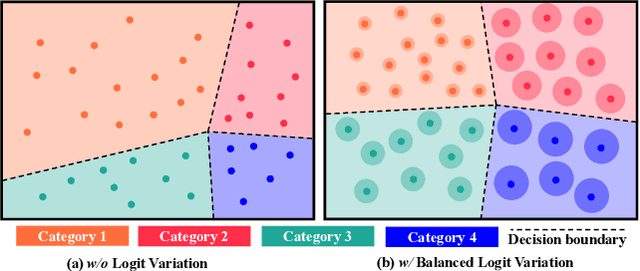

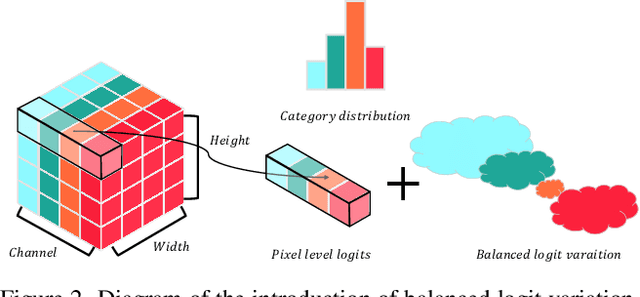
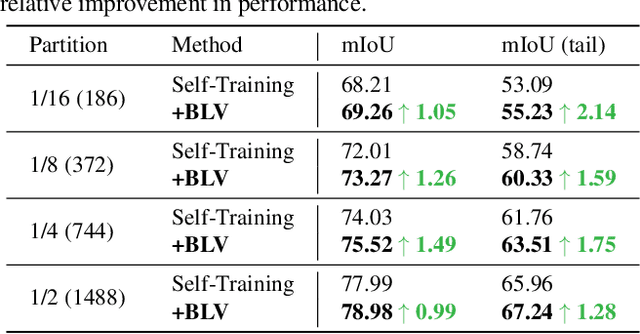
Semantic segmentation usually suffers from a long-tail data distribution. Due to the imbalanced number of samples across categories, the features of those tail classes may get squeezed into a narrow area in the feature space. Towards a balanced feature distribution, we introduce category-wise variation into the network predictions in the training phase such that an instance is no longer projected to a feature point, but a small region instead. Such a perturbation is highly dependent on the category scale, which appears as assigning smaller variation to head classes and larger variation to tail classes. In this way, we manage to close the gap between the feature areas of different categories, resulting in a more balanced representation. It is noteworthy that the introduced variation is discarded at the inference stage to facilitate a confident prediction. Although with an embarrassingly simple implementation, our method manifests itself in strong generalizability to various datasets and task settings. Extensive experiments suggest that our plug-in design lends itself well to a range of state-of-the-art approaches and boosts the performance on top of them.
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Mar 14, 2022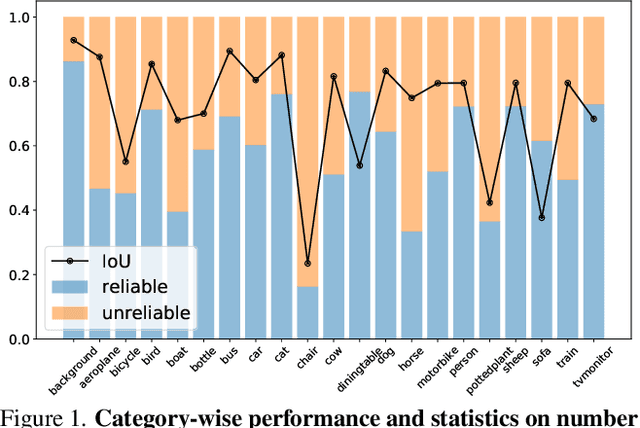
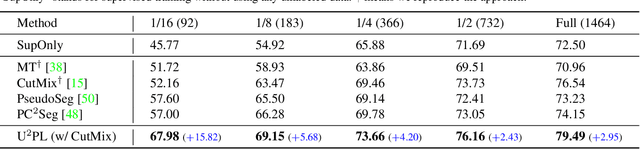
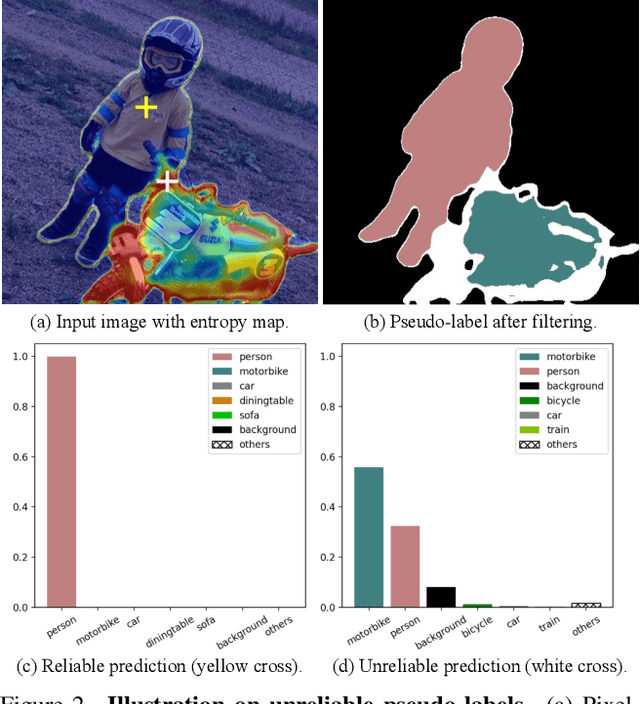
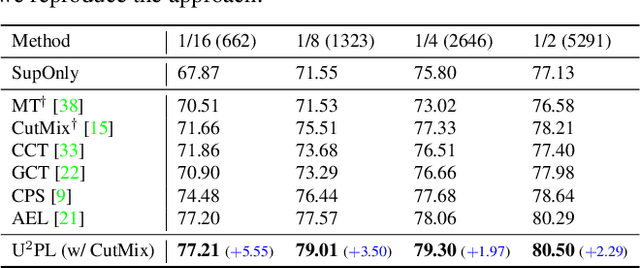
The crux of semi-supervised semantic segmentation is to assign adequate pseudo-labels to the pixels of unlabeled images. A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability. We argue that every pixel matters to the model training, even its prediction is ambiguous. Intuitively, an unreliable prediction may get confused among the top classes (i.e., those with the highest probabilities), however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative sample to those most unlikely categories. Based on this insight, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative samples, and manage to train the model with all candidate pixels. Considering the training evolution, where the prediction becomes more and more accurate, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.