 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroBP: Learning Position-Aware Correspondence for Zero-shot 6D Pose Estimation in Bin-Picking
Feb 03, 2025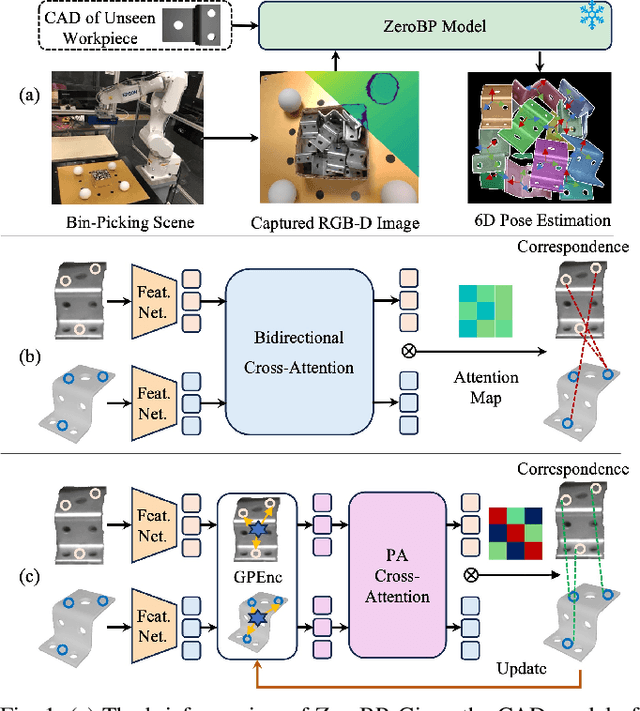



Bin-picking is a practical and challenging robotic manipulation task, where accurate 6D pose estimation plays a pivotal role. The workpieces in bin-picking are typically textureless and randomly stacked in a bin, which poses a significant challenge to 6D pose estimation. Existing solutions are typically learning-based methods, which require object-specific training. Their efficiency of practical deployment for novel workpieces is highly limited by data collection and model retraining. Zero-shot 6D pose estimation is a potential approach to address the issue of deployment efficiency. Nevertheless, existing zero-shot 6D pose estimation methods are designed to leverage feature matching to establish point-to-point correspondences for pose estimation, which is less effective for workpieces with textureless appearances and ambiguous local regions. In this paper, we propose ZeroBP, a zero-shot pose estimation framework designed specifically for the bin-picking task. ZeroBP learns Position-Aware Correspondence (PAC) between the scene instance and its CAD model, leveraging both local features and global positions to resolve the mismatch issue caused by ambiguous regions with similar shapes and appearances. Extensive experiments on the ROBI dataset demonstrate that ZeroBP outperforms state-of-the-art zero-shot pose estimation methods, achieving an improvement of 9.1% in average recall of correct poses.
TPTU-v2: Boosting Task Planning and Tool Usage of Large Language Model-based Agents in Real-world Systems
Nov 19, 2023Large Language Models (LLMs) have demonstrated proficiency in addressing tasks that necessitate a combination of task planning and the usage of external tools that require a blend of task planning and the utilization of external tools, such as APIs. However, real-world complex systems present three prevalent challenges concerning task planning and tool usage: (1) The real system usually has a vast array of APIs, so it is impossible to feed the descriptions of all APIs to the prompt of LLMs as the token length is limited; (2) the real system is designed for handling complex tasks, and the base LLMs can hardly plan a correct sub-task order and API-calling order for such tasks; (3) Similar semantics and functionalities among APIs in real systems create challenges for both LLMs and even humans in distinguishing between them. In response, this paper introduces a comprehensive framework aimed at enhancing the Task Planning and Tool Usage (TPTU) abilities of LLM-based agents operating within real-world systems. Our framework comprises three key components designed to address these challenges: (1) the API Retriever selects the most pertinent APIs for the user task among the extensive array available; (2) LLM Finetuner tunes a base LLM so that the finetuned LLM can be more capable for task planning and API calling; (3) the Demo Selector adaptively retrieves different demonstrations related to hard-to-distinguish APIs, which is further used for in-context learning to boost the final performance. We validate our methods using a real-world commercial system as well as an open-sourced academic dataset, and the outcomes clearly showcase the efficacy of each individual component as well as the integrated framework.
TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents
Aug 07, 2023



With recent advancements in natural language processing, Large Language Models (LLMs) have emerged as powerful tools for various real-world applications. Despite their prowess, the intrinsic generative abilities of LLMs may prove insufficient for handling complex tasks which necessitate a combination of task planning and the usage of external tools. In this paper, we first propose a structured framework tailored for LLM-based AI Agents and discuss the crucial capabilities necessary for tackling intricate problems. Within this framework, we design two distinct types of agents (i.e., one-step agent and sequential agent) to execute the inference process. Subsequently, we instantiate the framework using various LLMs and evaluate their Task Planning and Tool Usage (TPTU) abilities on typical tasks. By highlighting key findings and challenges, our goal is to provide a helpful resource for researchers and practitioners to leverage the power of LLMs in their AI applications. Our study emphasizes the substantial potential of these models, while also identifying areas that need more investigation and improvement.
Balancing Logit Variation for Long-tailed Semantic Segmentation
Jun 03, 2023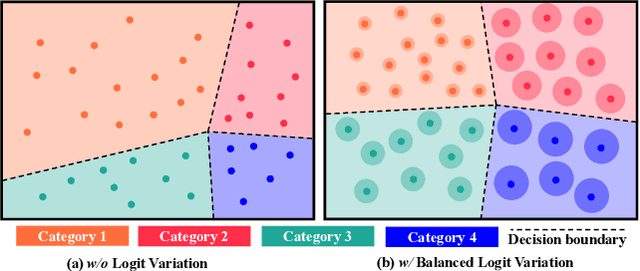

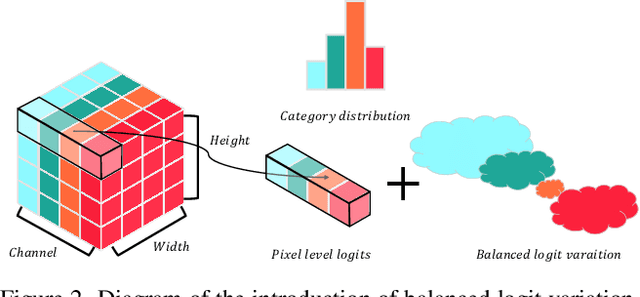
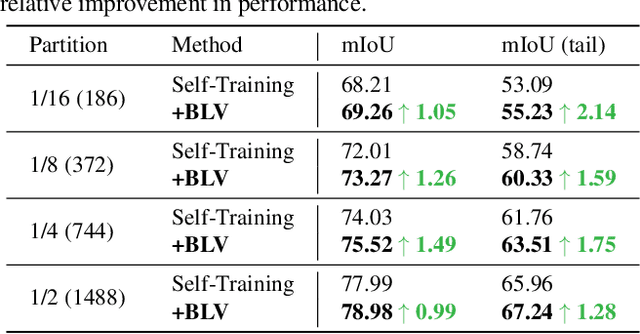
Semantic segmentation usually suffers from a long-tail data distribution. Due to the imbalanced number of samples across categories, the features of those tail classes may get squeezed into a narrow area in the feature space. Towards a balanced feature distribution, we introduce category-wise variation into the network predictions in the training phase such that an instance is no longer projected to a feature point, but a small region instead. Such a perturbation is highly dependent on the category scale, which appears as assigning smaller variation to head classes and larger variation to tail classes. In this way, we manage to close the gap between the feature areas of different categories, resulting in a more balanced representation. It is noteworthy that the introduced variation is discarded at the inference stage to facilitate a confident prediction. Although with an embarrassingly simple implementation, our method manifests itself in strong generalizability to various datasets and task settings. Extensive experiments suggest that our plug-in design lends itself well to a range of state-of-the-art approaches and boosts the performance on top of them.
3D Model-based Zero-Shot Pose Estimation Pipeline
May 29, 2023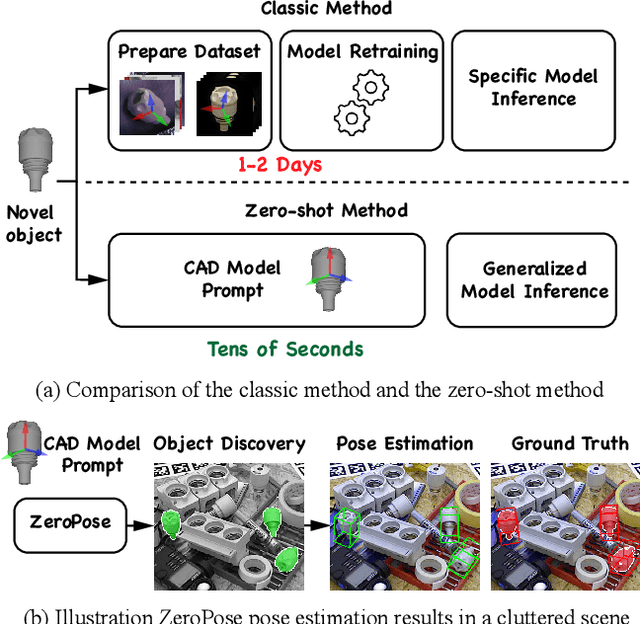
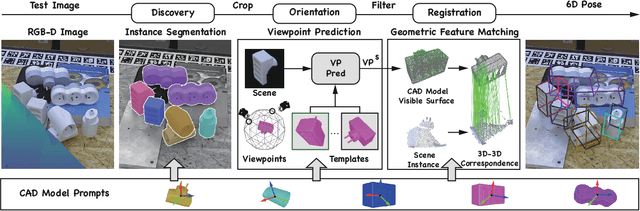
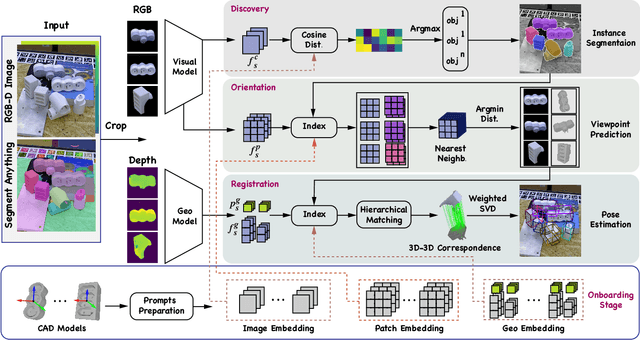
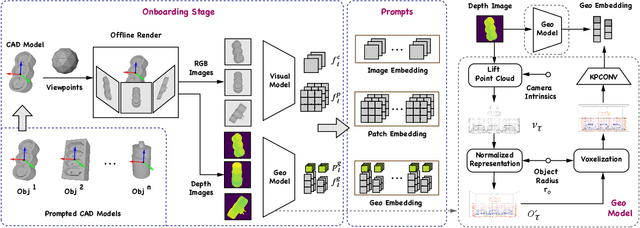
Most existing learning-based pose estimation methods are typically developed for non-zero-shot scenarios, where they can only estimate the poses of objects present in the training dataset. This setting restricts their applicability to unseen objects in the training phase. In this paper, we introduce a fully zero-shot pose estimation pipeline that leverages the 3D models of objects as clues. Specifically, we design a two-step pipeline consisting of 3D model-based zero-shot instance segmentation and a zero-shot pose estimator. For the first step, there is a novel way to perform zero-shot instance segmentation based on the 3D models instead of text descriptions, which can handle complex properties of unseen objects. For the second step, we utilize a hierarchical geometric structure matching mechanism to perform zero-shot pose estimation which is 10 times faster than the current render-based method. Extensive experimental results on the seven core datasets on the BOP challenge show that the proposed method outperforms the zero-shot state-of-the-art method with higher speed and lower computation cost.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023



Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
MIAD: A Maintenance Inspection Dataset for Unsupervised Anomaly Detection
Nov 28, 2022



Visual anomaly detection plays a crucial role in not only manufacturing inspection to find defects of products during manufacturing processes, but also maintenance inspection to keep equipment in optimum working condition particularly outdoors. Due to the scarcity of the defective samples, unsupervised anomaly detection has attracted great attention in recent years. However, existing datasets for unsupervised anomaly detection are biased towards manufacturing inspection, not considering maintenance inspection which is usually conducted under outdoor uncontrolled environment such as varying camera viewpoints, messy background and degradation of object surface after long-term working. We focus on outdoor maintenance inspection and contribute a comprehensive Maintenance Inspection Anomaly Detection (MIAD) dataset which contains more than 100K high-resolution color images in various outdoor industrial scenarios. This dataset is generated by a 3D graphics software and covers both surface and logical anomalies with pixel-precise ground truth. Extensive evaluations of representative algorithms for unsupervised anomaly detection are conducted, and we expect MIAD and corresponding experimental results can inspire research community in outdoor unsupervised anomaly detection tasks. Worthwhile and related future work can be spawned from our new dataset.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022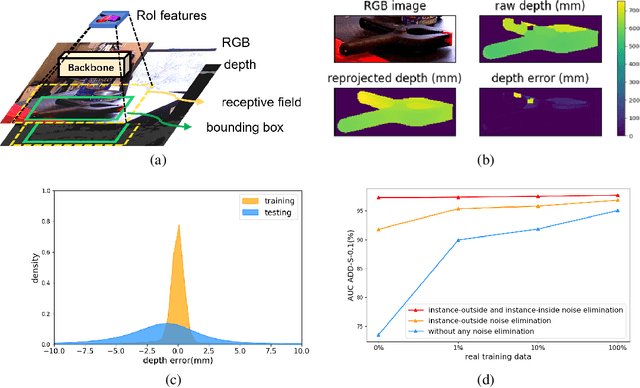
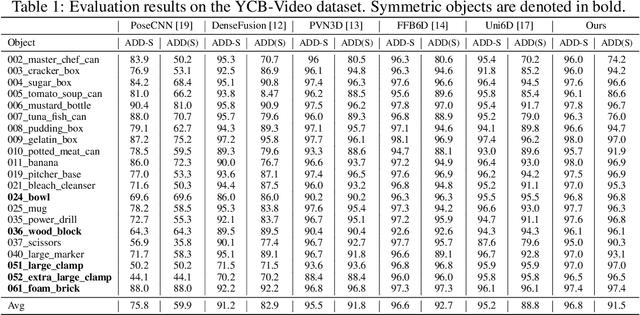
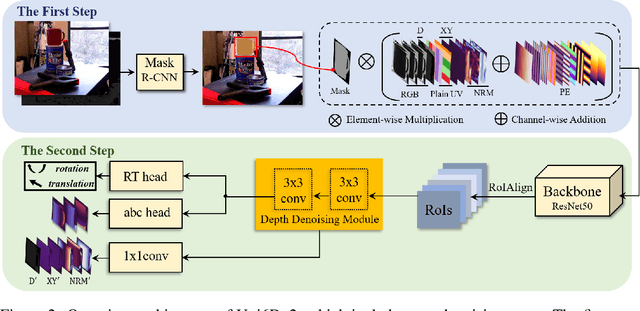
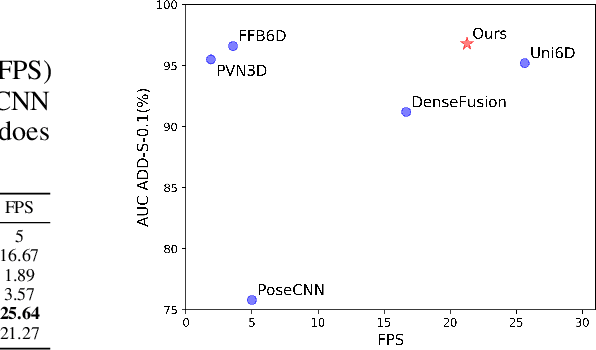
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization
Oct 09, 2021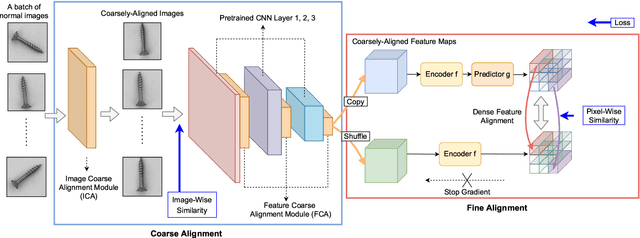
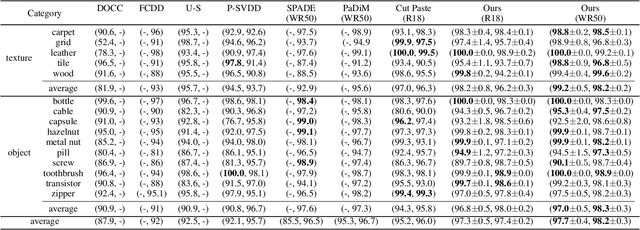
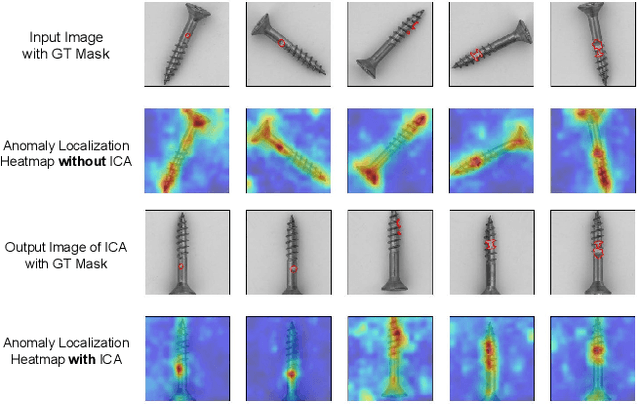
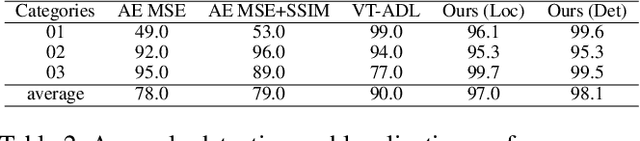
The essence of unsupervised anomaly detection is to learn the compact distribution of normal samples and detect outliers as anomalies in testing. Meanwhile, the anomalies in real-world are usually subtle and fine-grained in a high-resolution image especially for industrial applications. Towards this end, we propose a novel framework for unsupervised anomaly detection and localization. Our method aims at learning dense and compact distribution from normal images with a coarse-to-fine alignment process. The coarse alignment stage standardizes the pixel-wise position of objects in both image and feature levels. The fine alignment stage then densely maximizes the similarity of features among all corresponding locations in a batch. To facilitate the learning with only normal images, we propose a new pretext task called non-contrastive learning for the fine alignment stage. Non-contrastive learning extracts robust and discriminating normal image representations without making assumptions on abnormal samples, and it thus empowers our model to generalize to various anomalous scenarios. Extensive experiments on two typical industrial datasets of MVTec AD and BenTech AD demonstrate that our framework is effective in detecting various real-world defects and achieves a new state-of-the-art in industrial unsupervised anomaly detection.