 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Computational Efficiency and Explainability of GeoAggregator
Jul 23, 2025Accurate modeling and explaining geospatial tabular data (GTD) are critical for understanding geospatial phenomena and their underlying processes. Recent work has proposed a novel transformer-based deep learning model named GeoAggregator (GA) for this purpose, and has demonstrated that it outperforms other statistical and machine learning approaches. In this short paper, we further improve GA by 1) developing an optimized pipeline that accelerates the dataloading process and streamlines the forward pass of GA to achieve better computational efficiency; and 2) incorporating a model ensembling strategy and a post-hoc model explanation function based on the GeoShapley framework to enhance model explainability. We validate the functionality and efficiency of the proposed strategies by applying the improved GA model to synthetic datasets. Experimental results show that our implementation improves the prediction accuracy and inference speed of GA compared to the original implementation. Moreover, explanation experiments indicate that GA can effectively captures the inherent spatial effects in the designed synthetic dataset. The complete pipeline has been made publicly available for community use (https://github.com/ruid7181/GA-sklearn).
GeoAggregator: An Efficient Transformer Model for Geo-Spatial Tabular Data
Feb 20, 2025



Modeling geospatial tabular data with deep learning has become a promising alternative to traditional statistical and machine learning approaches. However, existing deep learning models often face challenges related to scalability and flexibility as datasets grow. To this end, this paper introduces GeoAggregator, an efficient and lightweight algorithm based on transformer architecture designed specifically for geospatial tabular data modeling. GeoAggregators explicitly account for spatial autocorrelation and spatial heterogeneity through Gaussian-biased local attention and global positional awareness. Additionally, we introduce a new attention mechanism that uses the Cartesian product to manage the size of the model while maintaining strong expressive power. We benchmark GeoAggregator against spatial statistical models, XGBoost, and several state-of-the-art geospatial deep learning methods using both synthetic and empirical geospatial datasets. The results demonstrate that GeoAggregators achieve the best or second-best performance compared to their competitors on nearly all datasets. GeoAggregator's efficiency is underscored by its reduced model size, making it both scalable and lightweight. Moreover, ablation experiments offer insights into the effectiveness of the Gaussian bias and Cartesian attention mechanism, providing recommendations for further optimizing the GeoAggregator's performance.
CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration
Apr 17, 2024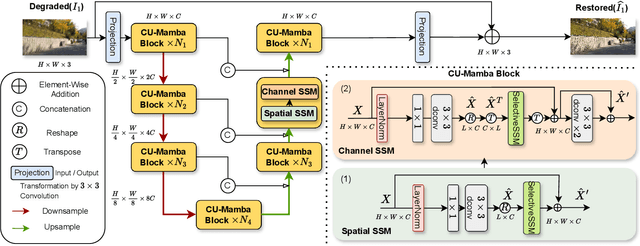
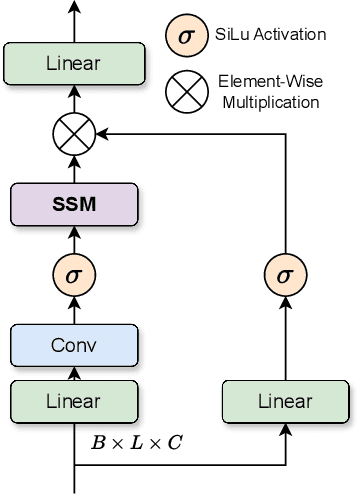


Reconstructing degraded images is a critical task in image processing. Although CNN and Transformer-based models are prevalent in this field, they exhibit inherent limitations, such as inadequate long-range dependency modeling and high computational costs. To overcome these issues, we introduce the Channel-Aware U-Shaped Mamba (CU-Mamba) model, which incorporates a dual State Space Model (SSM) framework into the U-Net architecture. CU-Mamba employs a Spatial SSM module for global context encoding and a Channel SSM component to preserve channel correlation features, both in linear computational complexity relative to the feature map size. Extensive experimental results validate CU-Mamba's superiority over existing state-of-the-art methods, underscoring the importance of integrating both spatial and channel contexts in image restoration.
Differentiable Resolution Compression and Alignment for Efficient Video Classification and Retrieval
Sep 15, 2023Optimizing video inference efficiency has become increasingly important with the growing demand for video analysis in various fields. Some existing methods achieve high efficiency by explicit discard of spatial or temporal information, which poses challenges in fast-changing and fine-grained scenarios. To address these issues, we propose an efficient video representation network with Differentiable Resolution Compression and Alignment mechanism, which compresses non-essential information in the early stage of the network to reduce computational costs while maintaining consistent temporal correlations. Specifically, we leverage a Differentiable Context-aware Compression Module to encode the saliency and non-saliency frame features, refining and updating the features into a high-low resolution video sequence. To process the new sequence, we introduce a new Resolution-Align Transformer Layer to capture global temporal correlations among frame features with different resolutions, while reducing spatial computation costs quadratically by utilizing fewer spatial tokens in low-resolution non-saliency frames. The entire network can be end-to-end optimized via the integration of the differentiable compression module. Experimental results show that our method achieves the best trade-off between efficiency and performance on near-duplicate video retrieval and competitive results on dynamic video classification compared to state-of-the-art methods. Code:https://github.com/dun-research/DRCA
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023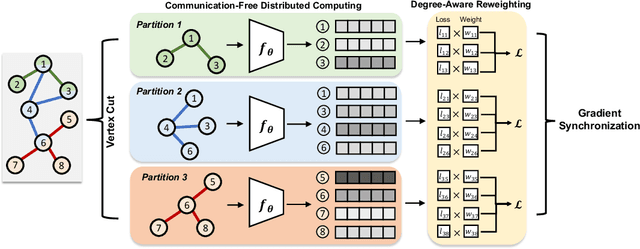
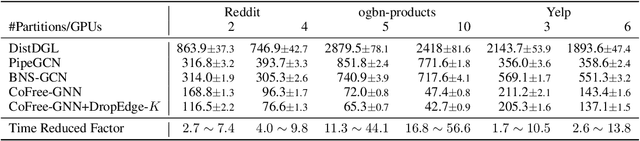
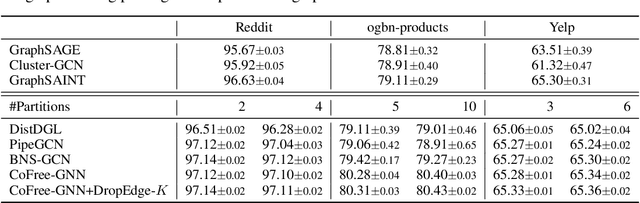

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.
The System Description of dun_oscar team for The ICPR MSR Challenge
Mar 13, 2023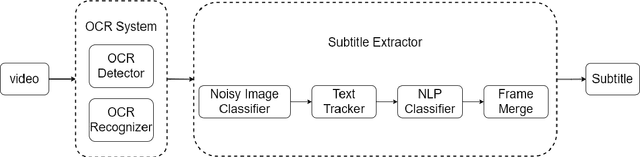


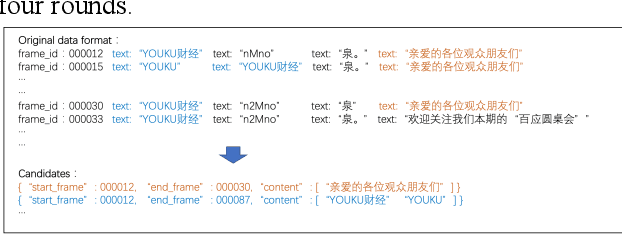
This paper introduces the system submitted by dun_oscar team for the ICPR MSR Challenge. Three subsystems for task1-task3 are descripted respectively. In task1, we develop a visual system which includes a OCR model, a text tracker, and a NLP classifier for distinguishing subtitles and non-subtitles. In task2, we employ an ASR system which includes an AM with 18 layers and a 4-gram LM. Semi-supervised learning on unlabeled data is also vital. In task3, we employ the ASR system to improve the visual system, some false subtitles can be corrected by a fusion module.
3D-CSL: self-supervised 3D context similarity learning for Near-Duplicate Video Retrieval
Nov 10, 2022In this paper, we introduce 3D-CSL, a compact pipeline for Near-Duplicate Video Retrieval (NDVR), and explore a novel self-supervised learning strategy for video similarity learning. Most previous methods only extract video spatial features from frames separately and then design kinds of complex mechanisms to learn the temporal correlations among frame features. However, parts of spatiotemporal dependencies have already been lost. To address this, our 3D-CSL extracts global spatiotemporal dependencies in videos end-to-end with a 3D transformer and find a good balance between efficiency and effectiveness by matching on clip-level. Furthermore, we propose a two-stage self-supervised similarity learning strategy to optimize the entire network. Firstly, we propose PredMAE to pretrain the 3D transformer with video prediction task; Secondly, ShotMix, a novel video-specific augmentation, and FCS loss, a novel triplet loss, are proposed further promote the similarity learning results. The experiments on FIVR-200K and CC_WEB_VIDEO demonstrate the superiority and reliability of our method, which achieves the state-of-the-art performance on clip-level NDVR.
Focus Your Distribution: Coarse-to-Fine Non-Contrastive Learning for Anomaly Detection and Localization
Oct 09, 2021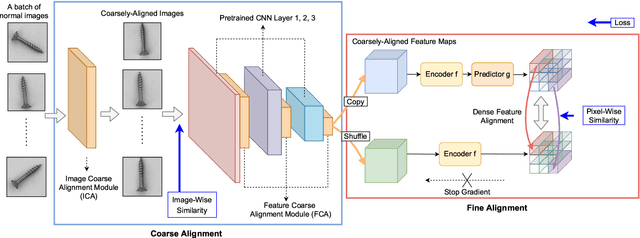
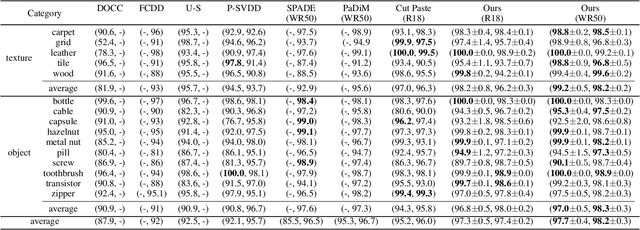
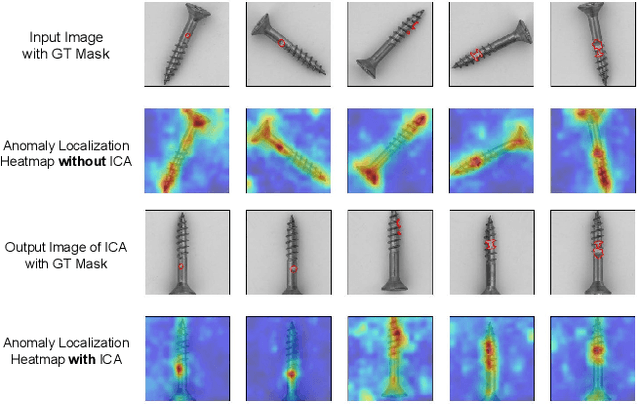
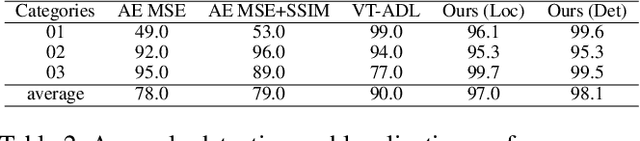
The essence of unsupervised anomaly detection is to learn the compact distribution of normal samples and detect outliers as anomalies in testing. Meanwhile, the anomalies in real-world are usually subtle and fine-grained in a high-resolution image especially for industrial applications. Towards this end, we propose a novel framework for unsupervised anomaly detection and localization. Our method aims at learning dense and compact distribution from normal images with a coarse-to-fine alignment process. The coarse alignment stage standardizes the pixel-wise position of objects in both image and feature levels. The fine alignment stage then densely maximizes the similarity of features among all corresponding locations in a batch. To facilitate the learning with only normal images, we propose a new pretext task called non-contrastive learning for the fine alignment stage. Non-contrastive learning extracts robust and discriminating normal image representations without making assumptions on abnormal samples, and it thus empowers our model to generalize to various anomalous scenarios. Extensive experiments on two typical industrial datasets of MVTec AD and BenTech AD demonstrate that our framework is effective in detecting various real-world defects and achieves a new state-of-the-art in industrial unsupervised anomaly detection.
MST: Masked Self-Supervised Transformer for Visual Representation
Jun 10, 2021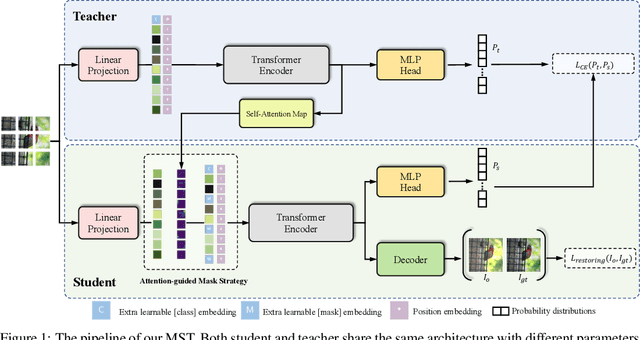
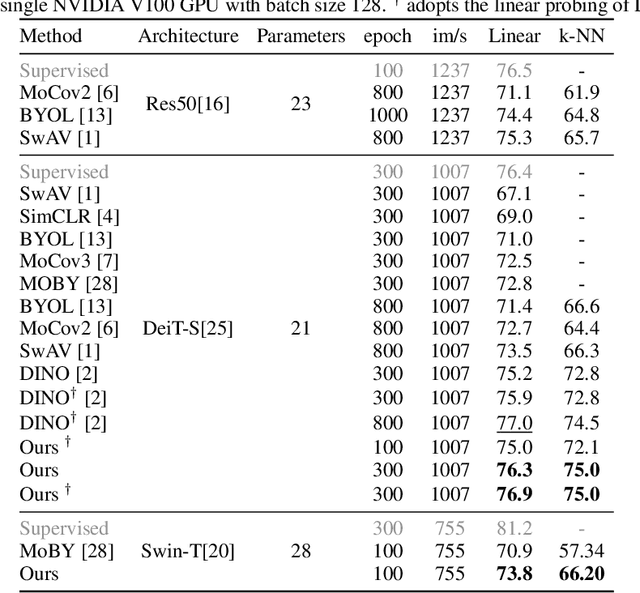

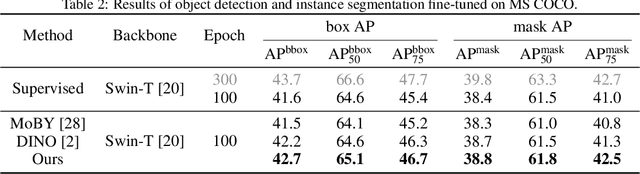
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the high-level feature and learning representation from a global perspective, which may fail to transfer to the downstream dense prediction tasks focusing on local features. In this paper, we present a novel Masked Self-supervised Transformer approach named MST, which can explicitly capture the local context of an image while preserving the global semantic information. Specifically, inspired by the Masked Language Modeling (MLM) in NLP, we propose a masked token strategy based on the multi-head self-attention map, which dynamically masks some tokens of local patches without damaging the crucial structure for self-supervised learning. More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks. The experiments on multiple datasets demonstrate the effectiveness and generality of the proposed method. For instance, MST achieves Top-1 accuracy of 76.9% with DeiT-S only using 300-epoch pre-training by linear evaluation, which outperforms supervised methods with the same epoch by 0.4% and its comparable variant DINO by 1.0\%. For dense prediction tasks, MST also achieves 42.7% mAP on MS COCO object detection and 74.04% mIoU on Cityscapes segmentation only with 100-epoch pre-training.
Fuzzy inference system application for oil-water flow patterns identification
May 24, 2021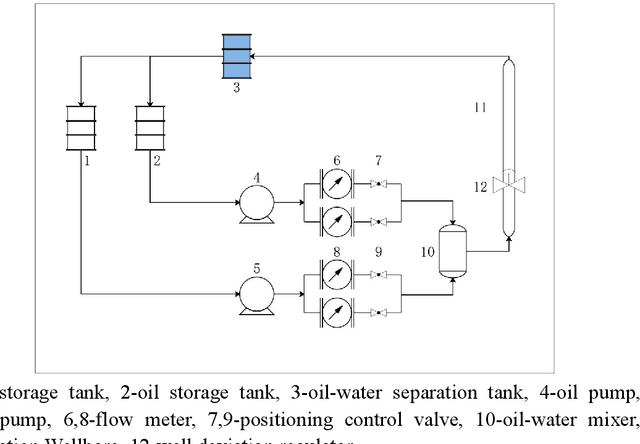
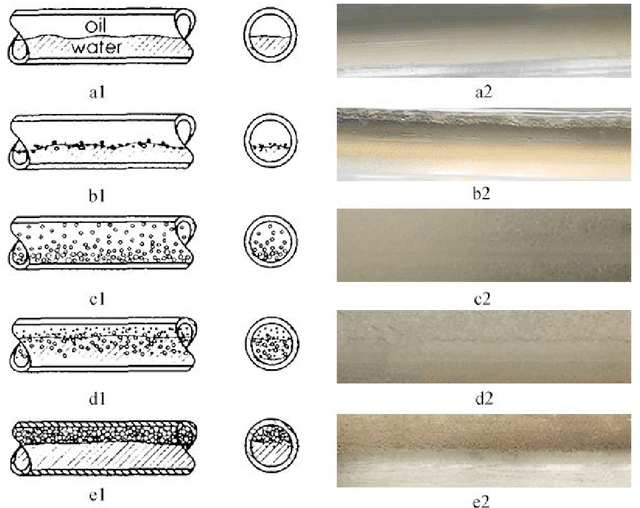
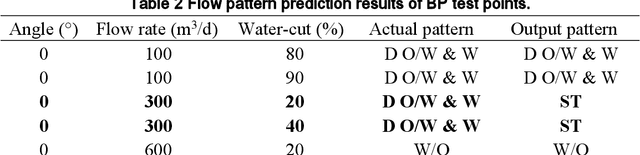
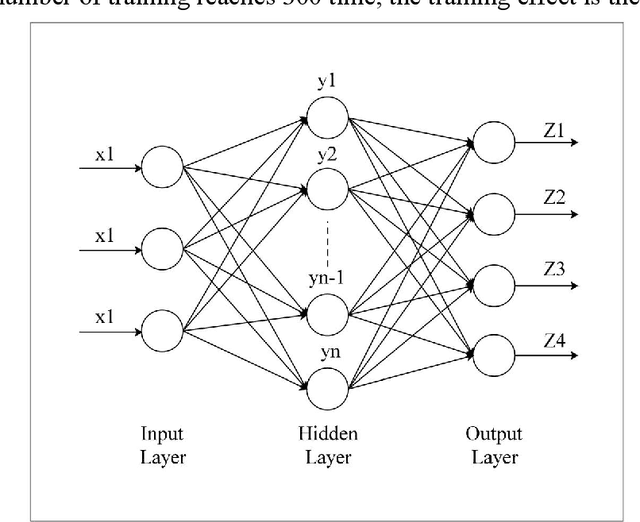
With the continuous development of the petroleum industry, long-distance transportation of oil and gas has been the norm. Due to gravity differentiation in horizontal wells and highly deviated wells (non-vertical wells), the water phase at the bottom of the pipeline will cause scaling and corrosion in the pipeline. Scaling and corrosion will make the transportation process difficult, and transportation costs will be considerably increased. Therefore, the study of the oil-water two-phase flow pattern is of great importance to oil production. In this paper, a fuzzy inference system is used to predict the flow pattern of the fluid, get the prediction result, and compares it with the prediction result of the BP neural network. From the comparison of the results, we found that the prediction results of the fuzzy inference system are more accurate and reliable than the prediction results of the BP neural network. At the same time, it can realize real-time monitoring and has less error control. Experimental results demonstrate that in the entire production logging process of non-vertical wells, the use of a fuzzy inference system to predict fluid flow patterns can greatly save production costs while ensuring the safe operation of production equipment.