 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound in Conversation: LLMs Teach Themselves to Close the Multi-Turn Gap
May 23, 2026Large Language Model (LLM) interactions are typically underspecified, with users clarifying all necessary details across multiple conversational turns. Yet recent work shows that LLMs perform far worse in this multi-turn setting than in a single turn with same information being available at once, a phenomenon termed "Lost-in-Conversation." However, bridging this gap effectively remains an open problem. Here we introduce Found in Conversation (FiC), a training framework where a model teaches itself to find and recover its single-turn competence given underspecified multi-turn prompts. We develop View-Asymmetric Self-Distillation, which distills across two views of the same task information--single-turn view for the teacher, multi-turn view for the student--transferring strong single-turn behavior into weak multi-turn behavior. This requires no stronger external teacher, which is unavailable as even frontier LLMs exhibit this gap. Across model families (Llama, Qwen, Phi, and OLMo) and sizes (3B-14B), FiC recovers at least 92% of single-turn performance and reaches 100% on two Llama backbones, yielding more efficient and helpful multi-turn conversations with single-turn capabilities intact.
Poly-EPO: Training Exploratory Reasoning Models
Apr 19, 2026Exploration is a cornerstone of learning from experience: it enables agents to find solutions to complex problems, generalize to novel ones, and scale performance with test-time compute. In this paper, we present a framework for post-training language models (LMs) that explicitly encourages optimistic exploration and promotes a synergy between exploration and exploitation. The central idea is to train the LM to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies. We first develop a general recipe for optimizing LMs with set reinforcement learning (set RL) under arbitrary objective functions, showing how standard RL algorithms can be adapted to this setting through a modification to the advantage computation. We then propose Polychromic Exploratory Policy Optimization (Poly-EPO), which instantiates this framework with an objective that explicitly synergizes exploration and exploitation. Across a range of reasoning benchmarks, we show that Poly-EPO improves generalization, as evidenced by higher pass@$k$ coverage, preserves greater diversity in model generations, and effectively scales with test-time compute.
SteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios
Feb 09, 2026A fundamental challenge in autonomous driving is the integration of high-level, semantic reasoning for long-tail events with low-level, reactive control for robust driving. While large vision-language models (VLMs) trained on web-scale data offer powerful common-sense reasoning, they lack the grounded experience necessary for safe vehicle control. We posit that an effective autonomous agent should leverage the world knowledge of VLMs to guide a steerable driving policy toward robust control in driving scenarios. To this end, we propose SteerVLA, which leverages the reasoning capabilities of VLMs to produce fine-grained language instructions that steer a vision-language-action (VLA) driving policy. Key to our method is this rich language interface between the high-level VLM and low-level VLA, which allows the high-level policy to more effectively ground its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with detailed language annotations, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 points in overall driving score and by 8.04 points on a long-tail subset. The project website is available at: https://steervla.github.io/.
SiriuS: Self-improving Multi-agent Systems via Bootstrapped Reasoning
Feb 07, 2025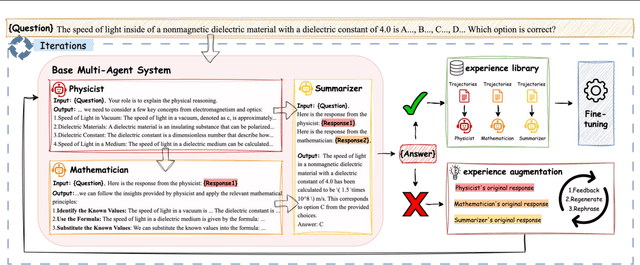
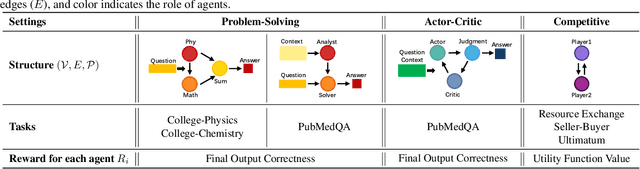

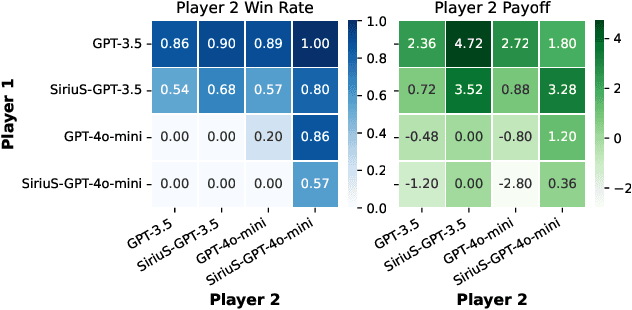
Multi-agent AI systems powered by large language models (LLMs) are increasingly applied to solve complex tasks. However, these systems often rely on fragile, manually designed prompts and heuristics, making optimization difficult. A key challenge in optimizing multi-agent systems is acquiring suitable training data for specialized agents. We introduce SiriuS, a self-improving, reasoning-driven optimization framework for multi-agent systems. Central to our approach is the construction of an experience library: a repository of high-quality reasoning trajectories. The library is built by retaining reasoning steps that lead to successful outcomes, providing a robust training set for optimizing multi-agent system. Additionally, we introduce a library augmentation procedure that refines unsuccessful trajectories, further enriching the library. SiriuS boosts performance by 2.86\% to 21.88\% on reasoning and biomedical QA and enhances agent negotiation in competitive settings. Our results show that SiriuS enhances multi-agent performance while generating reusable data for self-correction and self-play enhancement in the future.
AvaTaR: Optimizing LLM Agents for Tool-Assisted Knowledge Retrieval
Jun 18, 2024



Large language model (LLM) agents have demonstrated impressive capability in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing the prompting techniques that make LLM agents able to effectively use external tools and knowledge is a heuristic and laborious task. Here, we introduce AvaTaR, a novel and automatic framework that optimizes an LLM agent to effectively use the provided tools and improve its performance on a given task/domain. During optimization, we design a comparator module to iteratively provide insightful and holistic prompts to the LLM agent via reasoning between positive and negative examples sampled from training data. We demonstrate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information. We find AvaTaR consistently outperforms state-of-the-art approaches across all four challenging tasks and exhibits strong generalization ability when applied to novel cases, achieving an average relative improvement of 14% on the Hit@1 metric. Code and dataset are available at https://github.com/zou-group/avatar.
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Apr 19, 2024



Answering real-world user queries, such as product search, often requires accurate retrieval of information from semi-structured knowledge bases or databases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. We design a novel pipeline to synthesize natural and realistic user queries that integrate diverse relational information and complex textual properties, as well as their ground-truth answers. Moreover, we rigorously conduct human evaluation to validate the quality of our benchmark, which covers a variety of practical applications, including product recommendations, academic paper searches, and precision medicine inquiries. Our benchmark serves as a comprehensive testbed for evaluating the performance of retrieval systems, with an emphasis on retrieval approaches driven by large language models (LLMs). Our experiments suggest that the STARK datasets present significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems that can handle both textual and relational aspects.
GraphMETRO: Mitigating Complex Distribution Shifts in GNNs via Mixture of Aligned Experts
Dec 07, 2023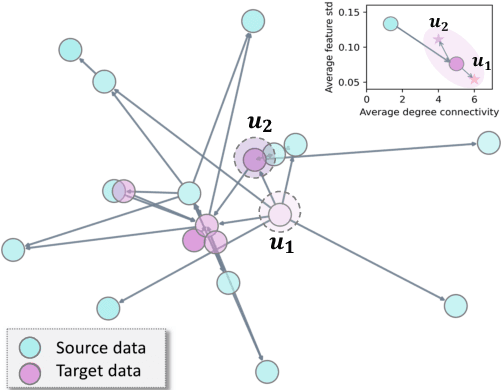
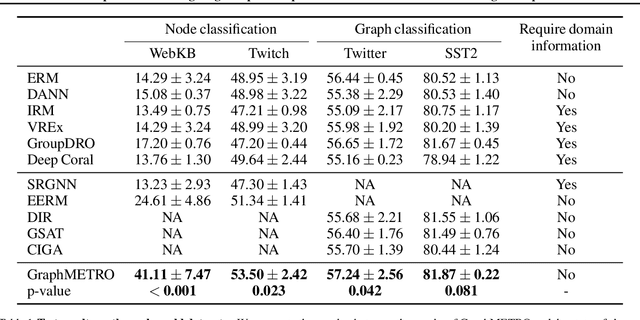
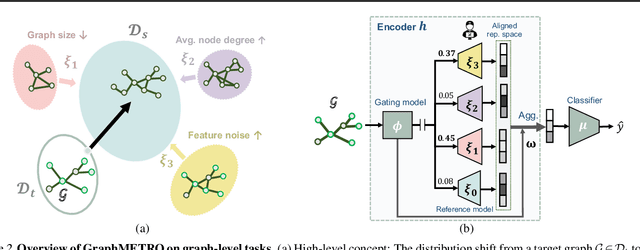
Graph Neural Networks' (GNNs) ability to generalize across complex distributions is crucial for real-world applications. However, prior research has primarily focused on specific types of distribution shifts, such as larger graph size, or inferred shifts from constructed data environments, which is highly limited when confronted with multiple and nuanced distribution shifts. For instance, in a social graph, a user node might experience increased interactions and content alterations, while other user nodes encounter distinct shifts. Neglecting such complexities significantly impedes generalization. To address it, we present GraphMETRO, a novel framework that enhances GNN generalization under complex distribution shifts in both node and graph-level tasks. Our approach employs a mixture-of-experts (MoE) architecture with a gating model and expert models aligned in a shared representation space. The gating model identifies key mixture components governing distribution shifts, while each expert generates invariant representations w.r.t. a mixture component. Finally, GraphMETRO aggregates representations from multiple experts to generate the final invariant representation. Our experiments on synthetic and realworld datasets demonstrate GraphMETRO's superiority and interpretability. To highlight, GraphMETRO achieves state-of-the-art performances on four real-world datasets from GOOD benchmark, outperforming the best baselines on WebKB and Twitch datasets by 67% and 4.2%, respectively.
Holistic Analysis of Hallucination in GPT-4V: Bias and Interference Challenges
Nov 07, 2023While GPT-4V(ision) impressively models both visual and textual information simultaneously, it's hallucination behavior has not been systematically assessed. To bridge this gap, we introduce a new benchmark, namely, the Bias and Interference Challenges in Visual Language Models (Bingo). This benchmark is designed to evaluate and shed light on the two common types of hallucinations in visual language models: bias and interference. Here, bias refers to the model's tendency to hallucinate certain types of responses, possibly due to imbalance in its training data. Interference pertains to scenarios where the judgment of GPT-4V(ision) can be disrupted due to how the text prompt is phrased or how the input image is presented. We identify a notable regional bias, whereby GPT-4V(ision) is better at interpreting Western images or images with English writing compared to images from other countries or containing text in other languages. Moreover, GPT-4V(ision) is vulnerable to leading questions and is often confused when interpreting multiple images together. Popular mitigation approaches, such as self-correction and chain-of-thought reasoning, are not effective in resolving these challenges. We also identified similar biases and interference vulnerabilities with LLaVA and Bard. Our results characterize the hallucination challenges in GPT-4V(ision) and state-of-the-art visual-language models, and highlight the need for new solutions. The Bingo benchmark is available at https://github.com/gzcch/Bingo.
D4Explainer: In-Distribution GNN Explanations via Discrete Denoising Diffusion
Oct 30, 2023The widespread deployment of Graph Neural Networks (GNNs) sparks significant interest in their explainability, which plays a vital role in model auditing and ensuring trustworthy graph learning. The objective of GNN explainability is to discern the underlying graph structures that have the most significant impact on model predictions. Ensuring that explanations generated are reliable necessitates consideration of the in-distribution property, particularly due to the vulnerability of GNNs to out-of-distribution data. Unfortunately, prevailing explainability methods tend to constrain the generated explanations to the structure of the original graph, thereby downplaying the significance of the in-distribution property and resulting in explanations that lack reliability. To address these challenges, we propose D4Explainer, a novel approach that provides in-distribution GNN explanations for both counterfactual and model-level explanation scenarios. The proposed D4Explainer incorporates generative graph distribution learning into the optimization objective, which accomplishes two goals: 1) generate a collection of diverse counterfactual graphs that conform to the in-distribution property for a given instance, and 2) identify the most discriminative graph patterns that contribute to a specific class prediction, thus serving as model-level explanations. It is worth mentioning that D4Explainer is the first unified framework that combines both counterfactual and model-level explanations. Empirical evaluations conducted on synthetic and real-world datasets provide compelling evidence of the state-of-the-art performance achieved by D4Explainer in terms of explanation accuracy, faithfulness, diversity, and robustness.
Communication-Free Distributed GNN Training with Vertex Cut
Aug 06, 2023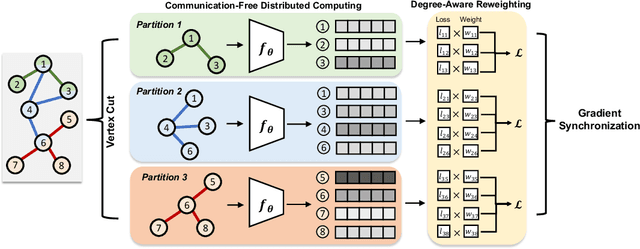
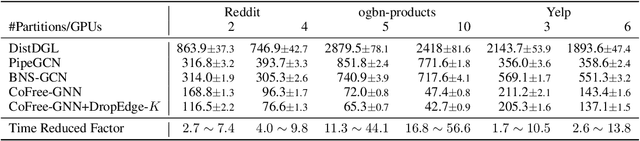
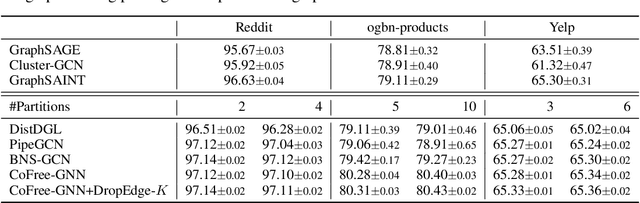

Training Graph Neural Networks (GNNs) on real-world graphs consisting of billions of nodes and edges is quite challenging, primarily due to the substantial memory needed to store the graph and its intermediate node and edge features, and there is a pressing need to speed up the training process. A common approach to achieve speed up is to divide the graph into many smaller subgraphs, which are then distributed across multiple GPUs in one or more machines and processed in parallel. However, existing distributed methods require frequent and substantial cross-GPU communication, leading to significant time overhead and progressively diminishing scalability. Here, we introduce CoFree-GNN, a novel distributed GNN training framework that significantly speeds up the training process by implementing communication-free training. The framework utilizes a Vertex Cut partitioning, i.e., rather than partitioning the graph by cutting the edges between partitions, the Vertex Cut partitions the edges and duplicates the node information to preserve the graph structure. Furthermore, the framework maintains high model accuracy by incorporating a reweighting mechanism to handle a distorted graph distribution that arises from the duplicated nodes. We also propose a modified DropEdge technique to further speed up the training process. Using an extensive set of experiments on real-world networks, we demonstrate that CoFree-GNN speeds up the GNN training process by up to 10 times over the existing state-of-the-art GNN training approaches.