 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Input Feature Spaces Towards Graph Foundation Models
May 06, 2026Unlike vision and language domains, graph learning lacks a shared input space, as input features differ across graph datasets not only in semantics, but also in value ranges and dimensionality. This misalignment prevents graph models from generalizing across datasets, limiting their use as foundation models. In this work, we propose ALL-IN, a simple and theoretically grounded method that enables transferability across datasets with different input features. Our approach projects node features into a shared random space and constructs representations via covariance-based statistics, thus eliminating dependence on the original feature space. We show that the computed node-covariance operators and the resulting node representations are invariant in distribution to permutations of the input features. We further demonstrate that the expected operator exhibits invariance to general orthogonal transformations of the input features. Empirically, ALL-IN achieves strong performance across diverse node- and graph-level tasks on unseen datasets with new input features, without requiring architecture changes or retraining. These results point to a promising direction for input-agnostic, transferable graph models.
Membership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
Boosting Relational Deep Learning with Pretrained Tabular Models
Apr 07, 2025Relational databases, organized into tables connected by primary-foreign key relationships, are a common format for organizing data. Making predictions on relational data often involves transforming them into a flat tabular format through table joins and feature engineering, which serve as input to tabular methods. However, designing features that fully capture complex relational patterns remains challenging. Graph Neural Networks (GNNs) offer a compelling alternative by inherently modeling these relationships, but their time overhead during inference limits their applicability for real-time scenarios. In this work, we aim to bridge this gap by leveraging existing feature engineering efforts to enhance the efficiency of GNNs in relational databases. Specifically, we use GNNs to capture complex relationships within relational databases, patterns that are difficult to featurize, while employing engineered features to encode temporal information, thereby avoiding the need to retain the entire historical graph and enabling the use of smaller, more efficient graphs. Our \textsc{LightRDL} approach not only improves efficiency, but also outperforms existing models. Experimental results on the RelBench benchmark demonstrate that our framework achieves up to $33\%$ performance improvement and a $526\times$ inference speedup compared to GNNs, making it highly suitable for real-time inference.
TRIX: A More Expressive Model for Zero-shot Domain Transfer in Knowledge Graphs
Feb 26, 2025Fully inductive knowledge graph models can be trained on multiple domains and subsequently perform zero-shot knowledge graph completion (KGC) in new unseen domains. This is an important capability towards the goal of having foundation models for knowledge graphs. In this work, we introduce a more expressive and capable fully inductive model, dubbed TRIX, which not only yields strictly more expressive triplet embeddings (head entity, relation, tail entity) compared to state-of-the-art methods, but also introduces a new capability: directly handling both entity and relation prediction tasks in inductive settings. Empirically, we show that TRIX outperforms the state-of-the-art fully inductive models in zero-shot entity and relation predictions in new domains, and outperforms large-context LLMs in out-of-domain predictions. The source code is available at https://github.com/yuchengz99/TRIX.
DiTASK: Multi-Task Fine-Tuning with Diffeomorphic Transformations
Feb 09, 2025Pre-trained Vision Transformers now serve as powerful tools for computer vision. Yet, efficiently adapting them for multiple tasks remains a challenge that arises from the need to modify the rich hidden representations encoded by the learned weight matrices, without inducing interference between tasks. Current parameter-efficient methods like LoRA, which apply low-rank updates, force tasks to compete within constrained subspaces, ultimately degrading performance. We introduce DiTASK a novel Diffeomorphic Multi-Task Fine-Tuning approach that maintains pre-trained representations by preserving weight matrix singular vectors, while enabling task-specific adaptations through neural diffeomorphic transformations of the singular values. By following this approach, DiTASK enables both shared and task-specific feature modulations with minimal added parameters. Our theoretical analysis shows that DITASK achieves full-rank updates during optimization, preserving the geometric structure of pre-trained features, and establishing a new paradigm for efficient multi-task learning (MTL). Our experiments on PASCAL MTL and NYUD show that DiTASK achieves state-of-the-art performance across four dense prediction tasks, using 75% fewer parameters than existing methods.
CENSOR: Defense Against Gradient Inversion via Orthogonal Subspace Bayesian Sampling
Jan 27, 2025



Federated learning collaboratively trains a neural network on a global server, where each local client receives the current global model weights and sends back parameter updates (gradients) based on its local private data. The process of sending these model updates may leak client's private data information. Existing gradient inversion attacks can exploit this vulnerability to recover private training instances from a client's gradient vectors. Recently, researchers have proposed advanced gradient inversion techniques that existing defenses struggle to handle effectively. In this work, we present a novel defense tailored for large neural network models. Our defense capitalizes on the high dimensionality of the model parameters to perturb gradients within a subspace orthogonal to the original gradient. By leveraging cold posteriors over orthogonal subspaces, our defense implements a refined gradient update mechanism. This enables the selection of an optimal gradient that not only safeguards against gradient inversion attacks but also maintains model utility. We conduct comprehensive experiments across three different datasets and evaluate our defense against various state-of-the-art attacks and defenses. Code is available at https://censor-gradient.github.io.
Scalable Out-of-distribution Robustness in the Presence of Unobserved Confounders
Nov 29, 2024We consider the task of out-of-distribution (OOD) generalization, where the distribution shift is due to an unobserved confounder ($Z$) affecting both the covariates ($X$) and the labels ($Y$). In this setting, traditional assumptions of covariate and label shift are unsuitable due to the confounding, which introduces heterogeneity in the predictor, i.e., $\hat{Y} = f_Z(X)$. OOD generalization differs from traditional domain adaptation by not assuming access to the covariate distribution ($X^\text{te}$) of the test samples during training. These conditions create a challenging scenario for OOD robustness: (a) $Z^\text{tr}$ is an unobserved confounder during training, (b) $P^\text{te}{Z} \neq P^\text{tr}{Z}$, (c) $X^\text{te}$ is unavailable during training, and (d) the posterior predictive distribution depends on $P^\text{te}(Z)$, i.e., $\hat{Y} = E_{P^\text{te}(Z)}[f_Z(X)]$. In general, accurate predictions are unattainable in this scenario, and existing literature has proposed complex predictors based on identifiability assumptions that require multiple additional variables. Our work investigates a set of identifiability assumptions that tremendously simplify the predictor, whose resulting elegant simplicity outperforms existing approaches.
Vertical Validation: Evaluating Implicit Generative Models for Graphs on Thin Support Regions
Nov 20, 2024
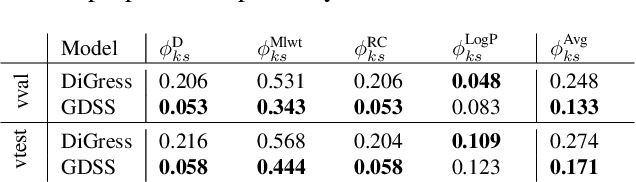

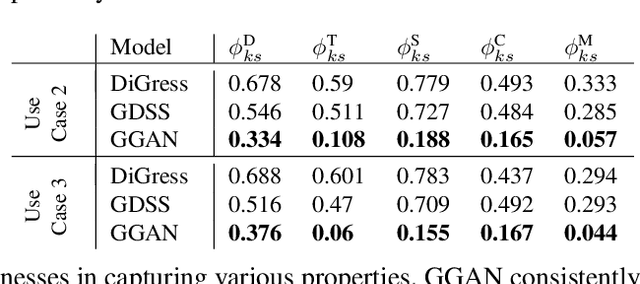
There has been a growing excitement that implicit graph generative models could be used to design or discover new molecules for medicine or material design. Because these molecules have not been discovered, they naturally lie in unexplored or scarcely supported regions of the distribution of known molecules. However, prior evaluation methods for implicit graph generative models have focused on validating statistics computed from the thick support (e.g., mean and variance of a graph property). Therefore, there is a mismatch between the goal of generating novel graphs and the evaluation methods. To address this evaluation gap, we design a novel evaluation method called Vertical Validation (VV) that systematically creates thin support regions during the train-test splitting procedure and then reweights generated samples so that they can be compared to the held-out test data. This procedure can be seen as a generalization of the standard train-test procedure except that the splits are dependent on sample features. We demonstrate that our method can be used to perform model selection if performance on thin support regions is the desired goal. As a side benefit, we also show that our approach can better detect overfitting as exemplified by memorization.
DiGRAF: Diffeomorphic Graph-Adaptive Activation Function
Jul 02, 2024



In this paper, we propose a novel activation function tailored specifically for graph data in Graph Neural Networks (GNNs). Motivated by the need for graph-adaptive and flexible activation functions, we introduce DiGRAF, leveraging Continuous Piecewise-Affine Based (CPAB) transformations, which we augment with an additional GNN to learn a graph-adaptive diffeomorphic activation function in an end-to-end manner. In addition to its graph-adaptivity and flexibility, DiGRAF also possesses properties that are widely recognized as desirable for activation functions, such as differentiability, boundness within the domain and computational efficiency. We conduct an extensive set of experiments across diverse datasets and tasks, demonstrating a consistent and superior performance of DiGRAF compared to traditional and graph-specific activation functions, highlighting its effectiveness as an activation function for GNNs.