 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Real-Time Modeling of Surgical Team Dynamics via Time-Expanded Interaction Graphs
May 05, 2026Surgical team performance arises from complex interactions between technical execution and non-technical skills, including communication and coordination dynamics. However, current surgical AI systems predominantly model visual workflow signals, lacking structured representations of intraoperative team interactions over time. We propose a real-time actionable approach for modeling surgical team dynamics using time-expanded interaction graphs, where team members are modeled as time-indexed nodes and communication exchanges define directed edges. This spatio-temporal expansion enables dynamic interaction modeling, while allowing efficient inference with a static graph neural network. The model predicts procedural efficiency as the deviation from the expected duration and supports real-time deployment. Beyond prediction, we perform a counterfactual analysis to identify minimal changes in communication structure and interpretable behavioral variables associated with improved predicted outcomes. Experiments on recorded surgical procedures show that structured modeling of team interactions improves early identification of prolonged interventions and provides coherent, actionable explanations. This work advances surgical AI toward real-time, team-aware, and actionable decision support in the operating room.
Rethinking GNNs and Missing Features: Challenges, Evaluation and a Robust Solution
Jan 08, 2026Handling missing node features is a key challenge for deploying Graph Neural Networks (GNNs) in real-world domains such as healthcare and sensor networks. Existing studies mostly address relatively benign scenarios, namely benchmark datasets with (a) high-dimensional but sparse node features and (b) incomplete data generated under Missing Completely At Random (MCAR) mechanisms. For (a), we theoretically prove that high sparsity substantially limits the information loss caused by missingness, making all models appear robust and preventing a meaningful comparison of their performance. To overcome this limitation, we introduce one synthetic and three real-world datasets with dense, semantically meaningful features. For (b), we move beyond MCAR and design evaluation protocols with more realistic missingness mechanisms. Moreover, we provide a theoretical background to state explicit assumptions on the missingness process and analyze their implications for different methods. Building on this analysis, we propose GNNmim, a simple yet effective baseline for node classification with incomplete feature data. Experiments show that GNNmim is competitive with respect to specialized architectures across diverse datasets and missingness regimes.
A Benchmark Dataset for Graph Regression with Homogeneous and Multi-Relational Variants
May 29, 2025



Graph-level regression underpins many real-world applications, yet public benchmarks remain heavily skewed toward molecular graphs and citation networks. This limited diversity hinders progress on models that must generalize across both homogeneous and heterogeneous graph structures. We introduce RelSC, a new graph-regression dataset built from program graphs that combine syntactic and semantic information extracted from source code. Each graph is labelled with the execution-time cost of the corresponding program, providing a continuous target variable that differs markedly from those found in existing benchmarks. RelSC is released in two complementary variants. RelSC-H supplies rich node features under a single (homogeneous) edge type, while RelSC-M preserves the original multi-relational structure, connecting nodes through multiple edge types that encode distinct semantic relationships. Together, these variants let researchers probe how representation choice influences model behaviour. We evaluate a diverse set of graph neural network architectures on both variants of RelSC. The results reveal consistent performance differences between the homogeneous and multi-relational settings, emphasising the importance of structural representation. These findings demonstrate RelSC's value as a challenging and versatile benchmark for advancing graph regression methods.
Boosting Relational Deep Learning with Pretrained Tabular Models
Apr 07, 2025Relational databases, organized into tables connected by primary-foreign key relationships, are a common format for organizing data. Making predictions on relational data often involves transforming them into a flat tabular format through table joins and feature engineering, which serve as input to tabular methods. However, designing features that fully capture complex relational patterns remains challenging. Graph Neural Networks (GNNs) offer a compelling alternative by inherently modeling these relationships, but their time overhead during inference limits their applicability for real-time scenarios. In this work, we aim to bridge this gap by leveraging existing feature engineering efforts to enhance the efficiency of GNNs in relational databases. Specifically, we use GNNs to capture complex relationships within relational databases, patterns that are difficult to featurize, while employing engineered features to encode temporal information, thereby avoiding the need to retain the entire historical graph and enabling the use of smaller, more efficient graphs. Our \textsc{LightRDL} approach not only improves efficiency, but also outperforms existing models. Experimental results on the RelBench benchmark demonstrate that our framework achieves up to $33\%$ performance improvement and a $526\times$ inference speedup compared to GNNs, making it highly suitable for real-time inference.
Simple Path Structural Encoding for Graph Transformers
Feb 13, 2025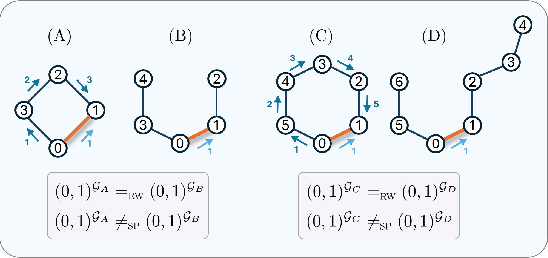
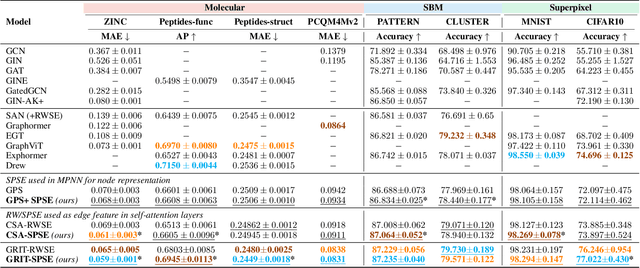
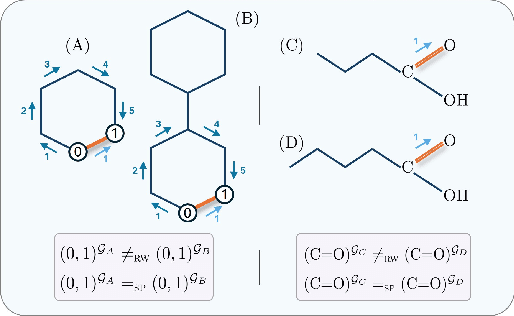
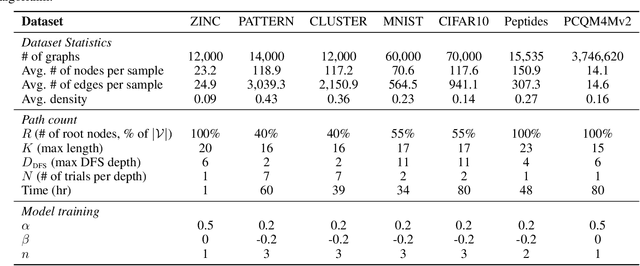
Graph transformers extend global self-attention to graph-structured data, achieving notable success in graph learning. Recently, random walk structural encoding (RWSE) has been found to further enhance their predictive power by encoding both structural and positional information into the edge representation. However, RWSE cannot always distinguish between edges that belong to different local graph patterns, which reduces its ability to capture the full structural complexity of graphs. This work introduces Simple Path Structural Encoding (SPSE), a novel method that utilizes simple path counts for edge encoding. We show theoretically and experimentally that SPSE overcomes the limitations of RWSE, providing a richer representation of graph structures, particularly for capturing local cyclic patterns. To make SPSE computationally tractable, we propose an efficient approximate algorithm for simple path counting. SPSE demonstrates significant performance improvements over RWSE on various benchmarks, including molecular and long-range graph datasets, achieving statistically significant gains in discriminative tasks. These results pose SPSE as a powerful edge encoding alternative for enhancing the expressivity of graph transformers.
A Self-Explainable Heterogeneous GNN for Relational Deep Learning
Nov 30, 2024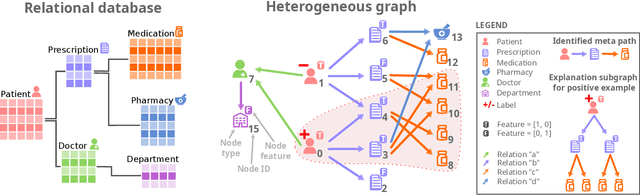



Recently, significant attention has been given to the idea of viewing relational databases as heterogeneous graphs, enabling the application of graph neural network (GNN) technology for predictive tasks. However, existing GNN methods struggle with the complexity of the heterogeneous graphs induced by databases with numerous tables and relations. Traditional approaches either consider all possible relational meta-paths, thus failing to scale with the number of relations, or rely on domain experts to identify relevant meta-paths. A recent solution does manage to learn informative meta-paths without expert supervision, but assumes that a node's class depends solely on the existence of a meta-path occurrence. In this work, we present a self-explainable heterogeneous GNN for relational data, that supports models in which class membership depends on aggregate information obtained from multiple occurrences of a meta-path. Experimental results show that in the context of relational databases, our approach effectively identifies informative meta-paths that faithfully capture the model's reasoning mechanisms. It significantly outperforms existing methods in both synthetic and real-world scenario.
xAI-Drop: Don't Use What You Cannot Explain
Jul 29, 2024

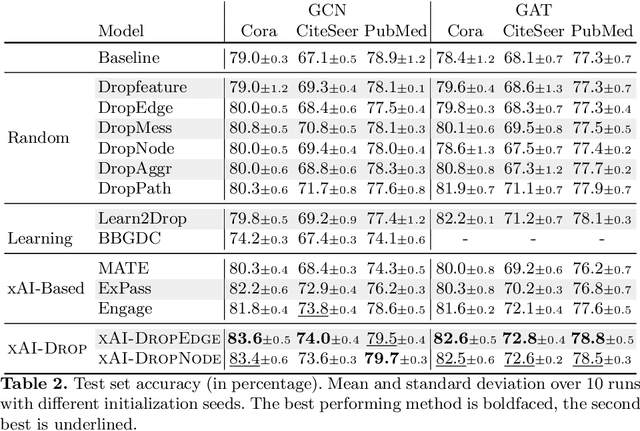

Graph Neural Networks (GNNs) have emerged as the predominant paradigm for learning from graph-structured data, offering a wide range of applications from social network analysis to bioinformatics. Despite their versatility, GNNs face challenges such as oversmoothing, lack of generalization and poor interpretability, which hinder their wider adoption and reliability in critical applications. Dropping has emerged as an effective paradigm for reducing noise during training and improving robustness of GNNs. However, existing approaches often rely on random or heuristic-based selection criteria, lacking a principled method to identify and exclude nodes that contribute to noise and over-complexity in the model. In this work, we argue that explainability should be a key indicator of a model's robustness throughout its training phase. To this end, we introduce xAI-Drop, a novel topological-level dropping regularizer that leverages explainability to pinpoint noisy network elements to be excluded from the GNN propagation mechanism. An empirical evaluation on diverse real-world datasets demonstrates that our method outperforms current state-of-the-art dropping approaches in accuracy, effectively reduces over-smoothing, and improves explanation quality.
Perks and Pitfalls of Faithfulness in Regular, Self-Explainable and Domain Invariant GNNs
Jun 21, 2024As Graph Neural Networks (GNNs) become more pervasive, it becomes paramount to build robust tools for computing explanations of their predictions. A key desideratum is that these explanations are faithful, i.e., that they portray an accurate picture of the GNN's reasoning process. A number of different faithfulness metrics exist, begging the question of what faithfulness is exactly, and what its properties are. We begin by showing that existing metrics are not interchangeable -- i.e., explanations attaining high faithfulness according to one metric may be unfaithful according to others -- and can be systematically insensitive to important properties of the explanation, and suggest how to address these issues. We proceed to show that, surprisingly, optimizing for faithfulness is not always a sensible design goal. Specifically, we show that for injective regular GNN architectures, perfectly faithful explanations are completely uninformative. The situation is different for modular GNNs, such as self-explainable and domain-invariant architectures, where optimizing faithfulness does not compromise informativeness, and is also unexpectedly tied to out-of-distribution generalization.
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Jun 17, 2024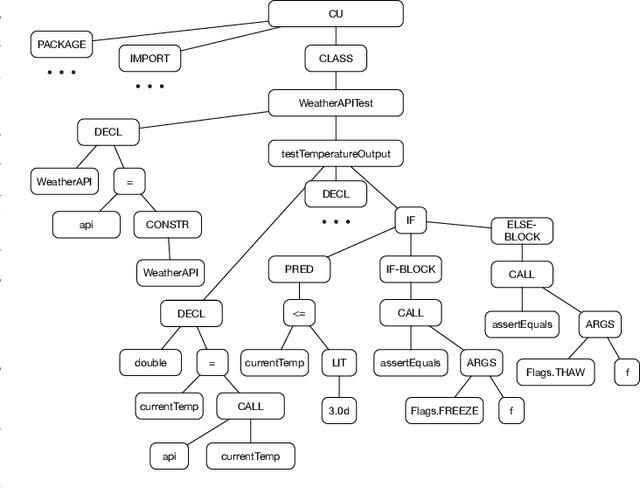



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
Putting Context in Context: the Impact of Discussion Structure on Text Classification
Feb 05, 2024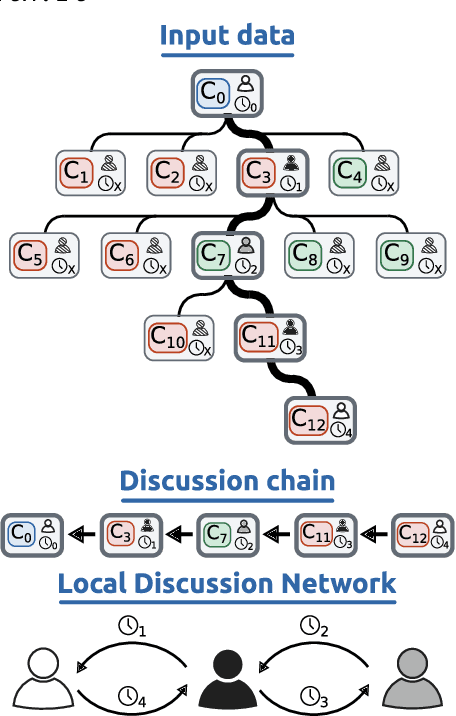
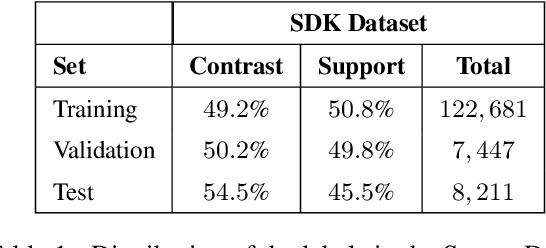


Current text classification approaches usually focus on the content to be classified. Contextual aspects (both linguistic and extra-linguistic) are usually neglected, even in tasks based on online discussions. Still in many cases the multi-party and multi-turn nature of the context from which these elements are selected can be fruitfully exploited. In this work, we propose a series of experiments on a large dataset for stance detection in English, in which we evaluate the contribution of different types of contextual information, i.e. linguistic, structural and temporal, by feeding them as natural language input into a transformer-based model. We also experiment with different amounts of training data and analyse the topology of local discussion networks in a privacy-compliant way. Results show that structural information can be highly beneficial to text classification but only under certain circumstances (e.g. depending on the amount of training data and on discussion chain complexity). Indeed, we show that contextual information on smaller datasets from other classification tasks does not yield significant improvements. Our framework, based on local discussion networks, allows the integration of structural information, while minimising user profiling, thus preserving their privacy.