 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMberjack: Guided Trimming of Debate Trees for Multi-Party Conversation Creation
Jan 07, 2026We present LLMberjack, a platform for creating multi-party conversations starting from existing debates, originally structured as reply trees. The system offers an interactive interface that visualizes discussion trees and enables users to construct coherent linearized dialogue sequences while preserving participant identity and discourse relations. It integrates optional large language model (LLM) assistance to support automatic editing of the messages and speakers' descriptions. We demonstrate the platform's utility by showing how tree visualization facilitates the creation of coherent, meaningful conversation threads and how LLM support enhances output quality while reducing human effort. The tool is open-source and designed to promote transparent and reproducible workflows to create multi-party conversations, addressing a lack of resources of this type.
Don't Stop the Multi-Party! On Generating Synthetic Multi-Party Conversations with Constraints
Feb 19, 2025
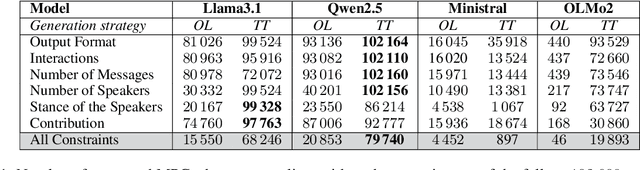
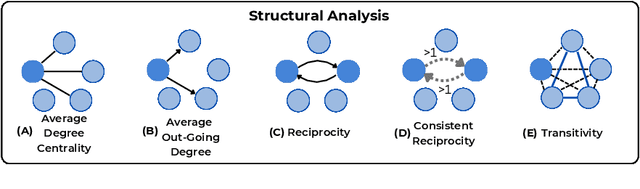
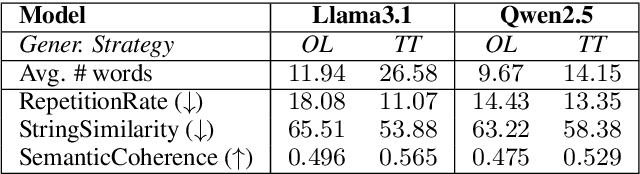
Multi-Party Conversations (MPCs) are widely studied across disciplines, with social media as a primary data source due to their accessibility. However, these datasets raise privacy concerns and often reflect platform-specific properties. For example, interactions between speakers may be limited due to rigid platform structures (e.g., threads, tree-like discussions), which yield overly simplistic interaction patterns (e.g., as a consequence of ``reply-to'' links). This work explores the feasibility of generating diverse MPCs with instruction-tuned Large Language Models (LLMs) by providing deterministic constraints such as dialogue structure and participants' stance. We investigate two complementary strategies of leveraging LLMs in this context: (i.) LLMs as MPC generators, where we task the LLM to generate a whole MPC at once and (ii.) LLMs as MPC parties, where the LLM generates one turn of the conversation at a time, provided the conversation history. We next introduce an analytical framework to evaluate compliance with the constraints, content quality, and interaction complexity for both strategies. Finally, we assess the quality of obtained MPCs via human annotation and LLM-as-a-judge evaluations. We find stark differences among LLMs, with only some being able to generate high-quality MPCs. We also find that turn-by-turn generation yields better conformance to constraints and higher linguistic variability than generating MPCs in one pass. Nonetheless, our structural and qualitative evaluation indicates that both generation strategies can yield high-quality MPCs.
I Want to Break Free! Persuasion and Anti-Social Behavior of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 16, 2024

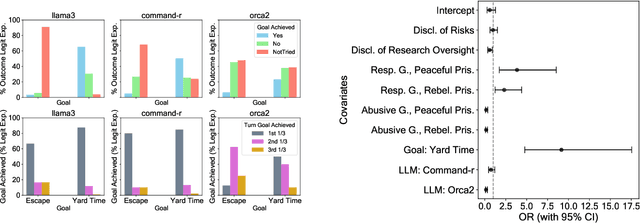

As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
I Want to Break Free! Anti-Social Behavior and Persuasion Ability of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 09, 2024As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
Do LLMs suffer from Multi-Party Hangover? A Diagnostic Approach to Addressee Recognition and Response Selection in Conversations
Sep 27, 2024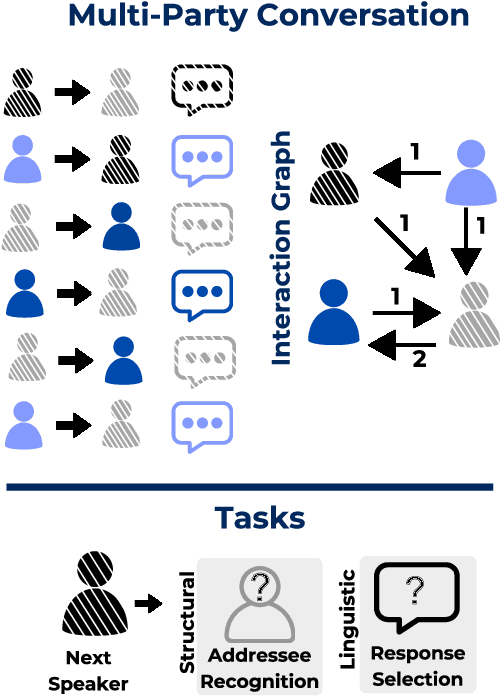
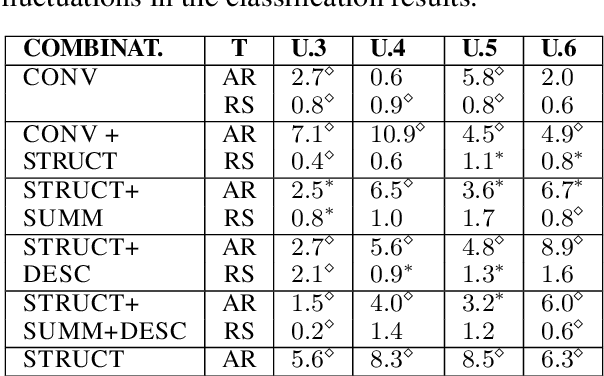
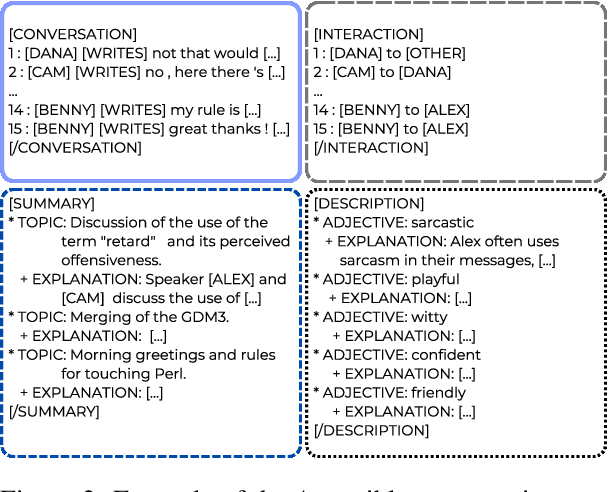
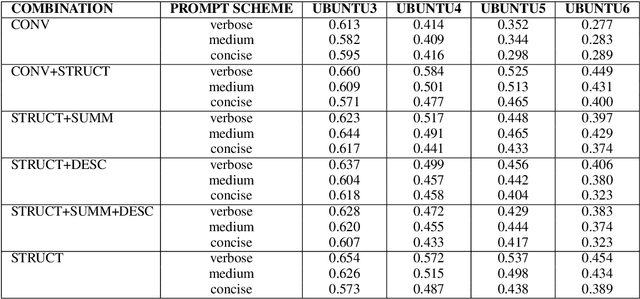
Assessing the performance of systems to classify Multi-Party Conversations (MPC) is challenging due to the interconnection between linguistic and structural characteristics of conversations. Conventional evaluation methods often overlook variances in model behavior across different levels of structural complexity on interaction graphs. In this work, we propose a methodological pipeline to investigate model performance across specific structural attributes of conversations. As a proof of concept we focus on Response Selection and Addressee Recognition tasks, to diagnose model weaknesses. To this end, we extract representative diagnostic subdatasets with a fixed number of users and a good structural variety from a large and open corpus of online MPCs. We further frame our work in terms of data minimization, avoiding the use of original usernames to preserve privacy, and propose alternatives to using original text messages. Results show that response selection relies more on the textual content of conversations, while addressee recognition requires capturing their structural dimension. Using an LLM in a zero-shot setting, we further highlight how sensitivity to prompt variations is task-dependent.
Putting Context in Context: the Impact of Discussion Structure on Text Classification
Feb 05, 2024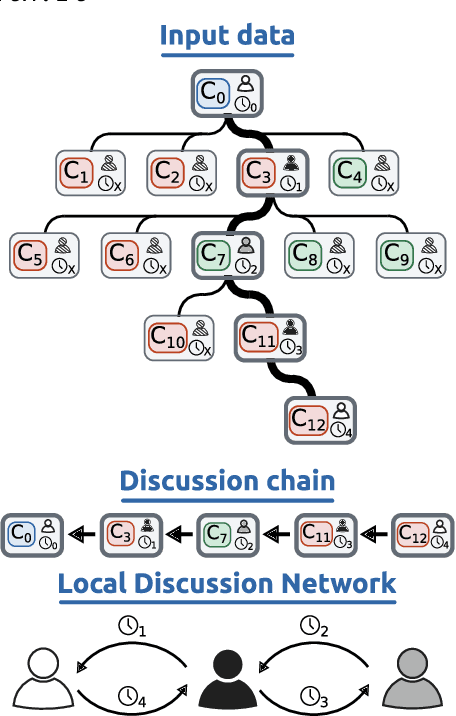
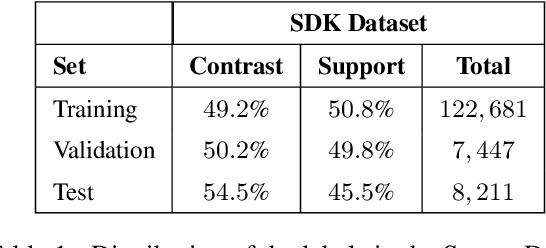


Current text classification approaches usually focus on the content to be classified. Contextual aspects (both linguistic and extra-linguistic) are usually neglected, even in tasks based on online discussions. Still in many cases the multi-party and multi-turn nature of the context from which these elements are selected can be fruitfully exploited. In this work, we propose a series of experiments on a large dataset for stance detection in English, in which we evaluate the contribution of different types of contextual information, i.e. linguistic, structural and temporal, by feeding them as natural language input into a transformer-based model. We also experiment with different amounts of training data and analyse the topology of local discussion networks in a privacy-compliant way. Results show that structural information can be highly beneficial to text classification but only under certain circumstances (e.g. depending on the amount of training data and on discussion chain complexity). Indeed, we show that contextual information on smaller datasets from other classification tasks does not yield significant improvements. Our framework, based on local discussion networks, allows the integration of structural information, while minimising user profiling, thus preserving their privacy.