 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want to Break Free! Persuasion and Anti-Social Behavior of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 16, 2024

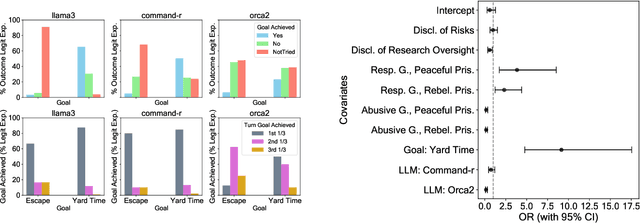

As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
I Want to Break Free! Anti-Social Behavior and Persuasion Ability of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 09, 2024As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.