 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Take a Memorable Picture? Empowering Users with Actionable Feedback
Feb 25, 2026Image memorability, i.e., how likely an image is to be remembered, has traditionally been studied in computer vision either as a passive prediction task, with models regressing a scalar score, or with generative methods altering the visual input to boost the image likelihood of being remembered. Yet, none of these paradigms supports users at capture time, when the crucial question is how to improve a photo memorability. We introduce the task of Memorability Feedback (MemFeed), where an automated model should provide actionable, human-interpretable guidance to users with the goal to enhance an image future recall. We also present MemCoach, the first approach designed to provide concrete suggestions in natural language for memorability improvement (e.g., "emphasize facial expression," "bring the subject forward"). Our method, based on Multimodal Large Language Models (MLLMs), is training-free and employs a teacher-student steering strategy, aligning the model internal activations toward more memorable patterns learned from a teacher model progressing along least-to-most memorable samples. To enable systematic evaluation on this novel task, we further introduce MemBench, a new benchmark featuring sequence-aligned photoshoots with annotated memorability scores. Our experiments, considering multiple MLLMs, demonstrate the effectiveness of MemCoach, showing consistently improved performance over several zero-shot models. The results indicate that memorability can not only be predicted but also taught and instructed, shifting the focus from mere prediction to actionable feedback for human creators.
SokoBench: Evaluating Long-Horizon Planning and Reasoning in Large Language Models
Jan 28, 2026Although the capabilities of large language models have been increasingly tested on complex reasoning tasks, their long-horizon planning abilities have not yet been extensively investigated. In this work, we provide a systematic assessment of the planning and long-horizon reasoning capabilities of state-of-the-art Large Reasoning Models (LRMs). We propose a novel benchmark based on Sokoban puzzles, intentionally simplified to isolate long-horizon planning from state persistence. Our findings reveal a consistent degradation in planning performance when more than 25 moves are required to reach the solution, suggesting a fundamental constraint on forward planning capacity. We show that equipping LRMs with Planning Domain Definition Language (PDDL) parsing, validation, and solving tools allows for modest improvements, suggesting inherent architectural limitations which might not be overcome by test-time scaling approaches alone.
The LLM Wears Prada: Analysing Gender Bias and Stereotypes through Online Shopping Data
Apr 02, 2025With the wide and cross-domain adoption of Large Language Models, it becomes crucial to assess to which extent the statistical correlations in training data, which underlie their impressive performance, hide subtle and potentially troubling biases. Gender bias in LLMs has been widely investigated from the perspectives of works, hobbies, and emotions typically associated with a specific gender. In this study, we introduce a novel perspective. We investigate whether LLMs can predict an individual's gender based solely on online shopping histories and whether these predictions are influenced by gender biases and stereotypes. Using a dataset of historical online purchases from users in the United States, we evaluate the ability of six LLMs to classify gender and we then analyze their reasoning and products-gender co-occurrences. Results indicate that while models can infer gender with moderate accuracy, their decisions are often rooted in stereotypical associations between product categories and gender. Furthermore, explicit instructions to avoid bias reduce the certainty of model predictions, but do not eliminate stereotypical patterns. Our findings highlight the persistent nature of gender biases in LLMs and emphasize the need for robust bias-mitigation strategies.
Face the Facts! Evaluating RAG-based Fact-checking Pipelines in Realistic Settings
Dec 19, 2024
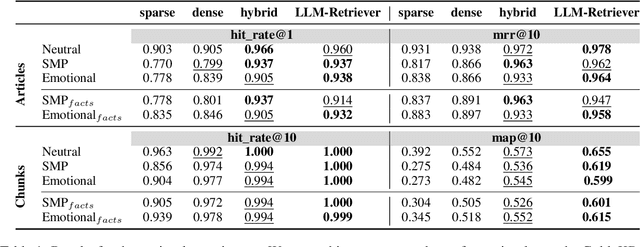
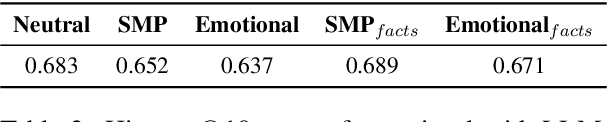

Natural Language Processing and Generation systems have recently shown the potential to complement and streamline the costly and time-consuming job of professional fact-checkers. In this work, we lift several constraints of current state-of-the-art pipelines for automated fact-checking based on the Retrieval-Augmented Generation (RAG) paradigm. Our goal is to benchmark, under more realistic scenarios, RAG-based methods for the generation of verdicts - i.e., short texts discussing the veracity of a claim - evaluating them on stylistically complex claims and heterogeneous, yet reliable, knowledge bases. Our findings show a complex landscape, where, for example, LLM-based retrievers outperform other retrieval techniques, though they still struggle with heterogeneous knowledge bases; larger models excel in verdict faithfulness, while smaller models provide better context adherence, with human evaluations favouring zero-shot and one-shot approaches for informativeness, and fine-tuned models for emotional alignment.
I Want to Break Free! Persuasion and Anti-Social Behavior of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 16, 2024

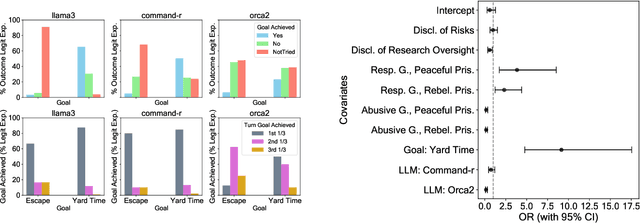

As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
I Want to Break Free! Anti-Social Behavior and Persuasion Ability of LLMs in Multi-Agent Settings with Social Hierarchy
Oct 09, 2024As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
Hopfield Networks for Asset Allocation
Jul 24, 2024



We present the first application of modern Hopfield networks to the problem of portfolio optimization. We performed an extensive study based on combinatorial purged cross-validation over several datasets and compared our results to both traditional and deep-learning-based methods for portfolio selection. Compared to state-of-the-art deep-learning methods such as Long-Short Term Memory networks and Transformers, we find that the proposed approach performs on par or better, while providing faster training times and better stability. Our results show that Modern Hopfield Networks represent a promising approach to portfolio optimization, allowing for an efficient, scalable, and robust solution for asset allocation, risk management, and dynamic rebalancing.
Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph
Apr 04, 2024Large Language Models (LLMs) demonstrate an impressive capacity to recall a vast range of common factual knowledge information. However, unravelling the underlying reasoning of LLMs and explaining their internal mechanisms of exploiting this factual knowledge remain active areas of investigation. Our work analyzes the factual knowledge encoded in the latent representation of LLMs when prompted to assess the truthfulness of factual claims. We propose an end-to-end framework that jointly decodes the factual knowledge embedded in the latent space of LLMs from a vector space to a set of ground predicates and represents its evolution across the layers using a temporal knowledge graph. Our framework relies on the technique of activation patching which intervenes in the inference computation of a model by dynamically altering its latent representations. Consequently, we neither rely on external models nor training processes. We showcase our framework with local and global interpretability analyses using two claim verification datasets: FEVER and CLIMATE-FEVER. The local interpretability analysis exposes different latent errors from representation to multi-hop reasoning errors. On the other hand, the global analysis uncovered patterns in the underlying evolution of the model's factual knowledge (e.g., store-and-seek factual information). By enabling graph-based analyses of the latent representations, this work represents a step towards the mechanistic interpretability of LLMs.
Can LLMs Correct Physicians, Yet? Investigating Effective Interaction Methods in the Medical Domain
Mar 29, 2024



We explore the potential of Large Language Models (LLMs) to assist and potentially correct physicians in medical decision-making tasks. We evaluate several LLMs, including Meditron, Llama2, and Mistral, to analyze the ability of these models to interact effectively with physicians across different scenarios. We consider questions from PubMedQA and several tasks, ranging from binary (yes/no) responses to long answer generation, where the answer of the model is produced after an interaction with a physician. Our findings suggest that prompt design significantly influences the downstream accuracy of LLMs and that LLMs can provide valuable feedback to physicians, challenging incorrect diagnoses and contributing to more accurate decision-making. For example, when the physician is accurate 38% of the time, Mistral can produce the correct answer, improving accuracy up to 74% depending on the prompt being used, while Llama2 and Meditron models exhibit greater sensitivity to prompt choice. Our analysis also uncovers the challenges of ensuring that LLM-generated suggestions are pertinent and useful, emphasizing the need for further research in this area.
The Garden of Forking Paths: Observing Dynamic Parameters Distribution in Large Language Models
Mar 13, 2024



A substantial gap persists in understanding the reasons behind the exceptional performance of the Transformer architecture in NLP. A particularly unexplored area involves the mechanistic description of how the distribution of parameters evolves over time during training. In this work we suggest that looking at the time evolution of the statistic distribution of model parameters, and specifically at bifurcation effects, can help understanding the model quality, potentially reducing training costs and evaluation efforts and empirically showing the reasons behind the effectiveness of weights sparsification.