 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuide Me Out: A Framework to Benchmark VLM Operators Communication in Crisis Scenarios
Jun 08, 2026Effective crisis response requires spatially grounded communication that bridges linguistic guidance of civilians with the physical environment, accounting for structural bottlenecks, evolving threats, and agent-specific contexts. Yet, current NLP research in crisis communication remains mainly limited to static, text-only classification settings, overlooking the critical communicative role of AI operators in dynamic, embodied scenarios. We address this gap with a novel benchmarking framework for evaluating Vision-Language Models (VLMs) tasked with guiding civilian agents through simulated evacuations. We test two communication strategies (narrowcast vs. broadcast), two environment representations (visual vs. graph-based), and two threat behaviors (static vs. moving) across nine maps of varying structural complexity. Our results show that Narrowcast consistently reduces civilian Fail rates compared to Broadcast across all difficulty levels. Guidance quality depends heavily on how the VLM operator represents the world: the visual modality drives performance, while adding an adjacency graph is model-dependent and often harmful. Moving threats raise Fail rates across all conditions as communication must continuously adapt over time. Together, these findings show that deploying VLMs as AI operators in evacuation scenarios remains a non-trivial challenge, where the choice of communication strategy and input representation can directly determine the success or failure of the intervention.
Face the Facts! Evaluating RAG-based Fact-checking Pipelines in Realistic Settings
Dec 19, 2024
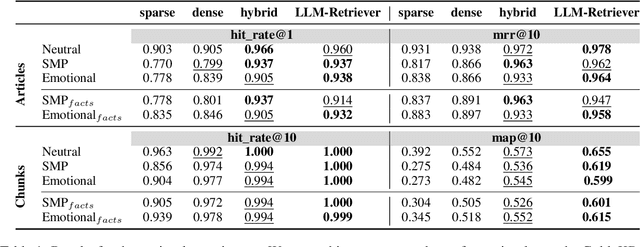
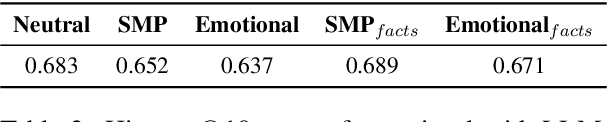

Natural Language Processing and Generation systems have recently shown the potential to complement and streamline the costly and time-consuming job of professional fact-checkers. In this work, we lift several constraints of current state-of-the-art pipelines for automated fact-checking based on the Retrieval-Augmented Generation (RAG) paradigm. Our goal is to benchmark, under more realistic scenarios, RAG-based methods for the generation of verdicts - i.e., short texts discussing the veracity of a claim - evaluating them on stylistically complex claims and heterogeneous, yet reliable, knowledge bases. Our findings show a complex landscape, where, for example, LLM-based retrievers outperform other retrieval techniques, though they still struggle with heterogeneous knowledge bases; larger models excel in verdict faithfulness, while smaller models provide better context adherence, with human evaluations favouring zero-shot and one-shot approaches for informativeness, and fine-tuned models for emotional alignment.
Variationist: Exploring Multifaceted Variation and Bias in Written Language Data
Jun 25, 2024



Exploring and understanding language data is a fundamental stage in all areas dealing with human language. It allows NLP practitioners to uncover quality concerns and harmful biases in data before training, and helps linguists and social scientists to gain insight into language use and human behavior. Yet, there is currently a lack of a unified, customizable tool to seamlessly inspect and visualize language variation and bias across multiple variables, language units, and diverse metrics that go beyond descriptive statistics. In this paper, we introduce Variationist, a highly-modular, extensible, and task-agnostic tool that fills this gap. Variationist handles at once a potentially unlimited combination of variable types and semantics across diversity and association metrics with regards to the language unit of choice, and orchestrates the creation of up to five-dimensional interactive charts for over 30 variable type-semantics combinations. Through our case studies on computational dialectology, human label variation, and text generation, we show how Variationist enables researchers from different disciplines to effortlessly answer specific research questions or unveil undesired associations in language data. A Python library, code, documentation, and tutorials are made publicly available to the research community.
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators' Disagreement
Sep 28, 2021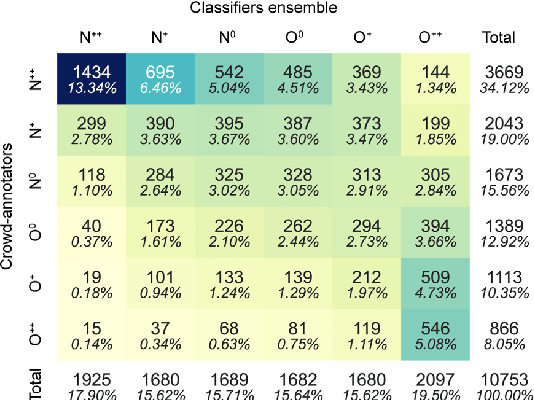

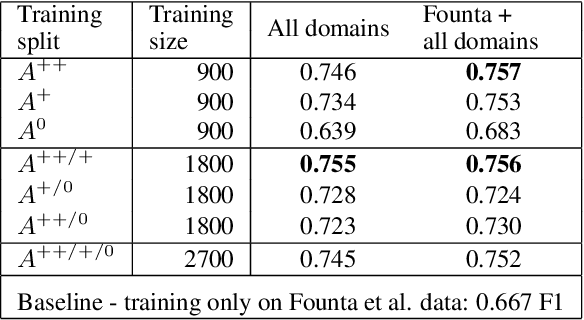
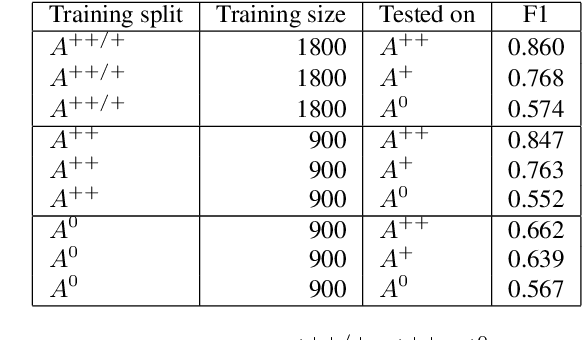
Since state-of-the-art approaches to offensive language detection rely on supervised learning, it is crucial to quickly adapt them to the continuously evolving scenario of social media. While several approaches have been proposed to tackle the problem from an algorithmic perspective, so to reduce the need for annotated data, less attention has been paid to the quality of these data. Following a trend that has emerged recently, we focus on the level of agreement among annotators while selecting data to create offensive language datasets, a task involving a high level of subjectivity. Our study comprises the creation of three novel datasets of English tweets covering different topics and having five crowd-sourced judgments each. We also present an extensive set of experiments showing that selecting training and test data according to different levels of annotators' agreement has a strong effect on classifiers performance and robustness. Our findings are further validated in cross-domain experiments and studied using a popular benchmark dataset. We show that such hard cases, where low agreement is present, are not necessarily due to poor-quality annotation and we advocate for a higher presence of ambiguous cases in future datasets, particularly in test sets, to better account for the different points of view expressed online.
Abuse is Contextual, What about NLP? The Role of Context in Abusive Language Annotation and Detection
Mar 27, 2021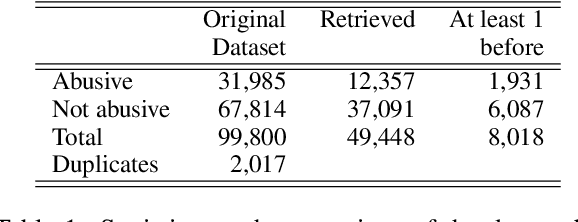


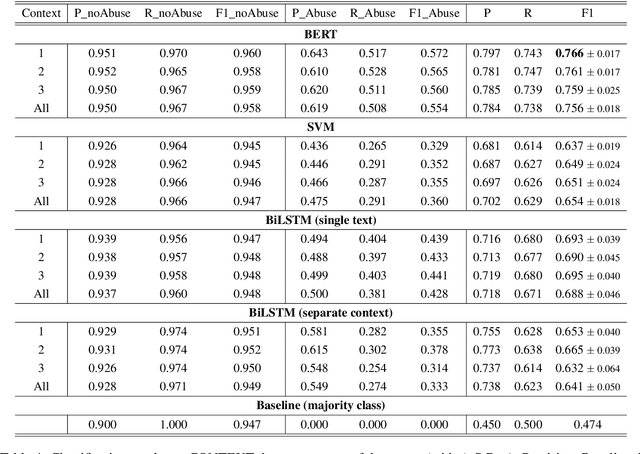
The datasets most widely used for abusive language detection contain lists of messages, usually tweets, that have been manually judged as abusive or not by one or more annotators, with the annotation performed at message level. In this paper, we investigate what happens when the hateful content of a message is judged also based on the context, given that messages are often ambiguous and need to be interpreted in the context of occurrence. We first re-annotate part of a widely used dataset for abusive language detection in English in two conditions, i.e. with and without context. Then, we compare the performance of three classification algorithms obtained on these two types of dataset, arguing that a context-aware classification is more challenging but also more similar to a real application scenario.
Creating a Multimodal Dataset of Images and Text to Study Abusive Language
May 05, 2020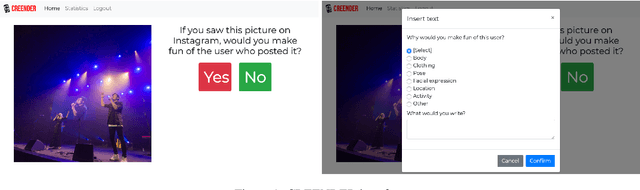

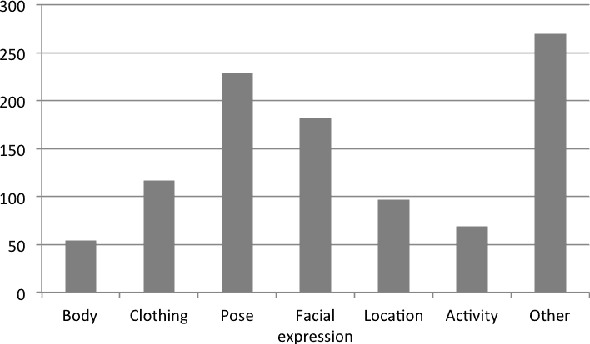
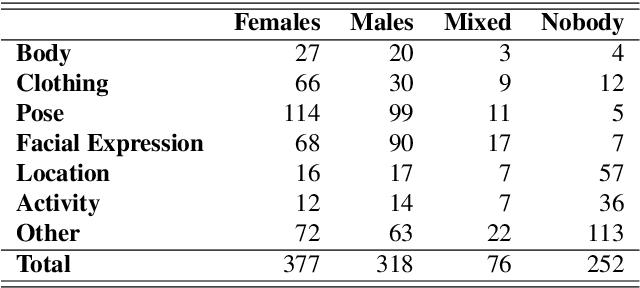
In order to study online hate speech, the availability of datasets containing the linguistic phenomena of interest are of crucial importance. However, when it comes to specific target groups, for example teenagers, collecting such data may be problematic due to issues with consent and privacy restrictions. Furthermore, while text-only datasets of this kind have been widely used, limitations set by image-based social media platforms like Instagram make it difficult for researchers to experiment with multimodal hate speech data. We therefore developed CREENDER, an annotation tool that has been used in school classes to create a multimodal dataset of images and abusive comments, which we make freely available under Apache 2.0 license. The corpus, with Italian comments, has been analysed from different perspectives, to investigate whether the subject of the images plays a role in triggering a comment. We find that users judge the same images in different ways, although the presence of a person in the picture increases the probability to get an offensive comment.