 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIND: an Italian Multi-Domain Dataset for Named Entity Recognition
Dec 30, 2021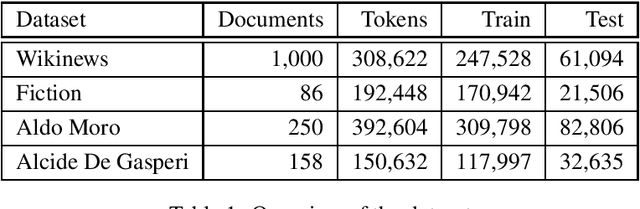
In this paper we present KIND, an Italian dataset for Named-Entity Recognition. It contains more than one million tokens with the annotation covering three classes: persons, locations, and organizations. Most of the dataset (around 600K tokens) contains manual gold annotations in three different domains: news, literature, and political discourses. Texts and annotations are downloadable for free from the Github repository.
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators' Disagreement
Sep 28, 2021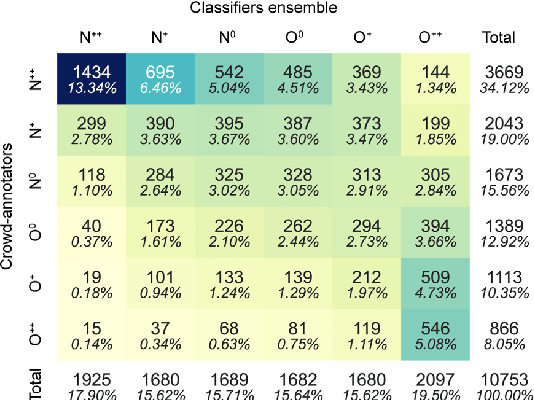

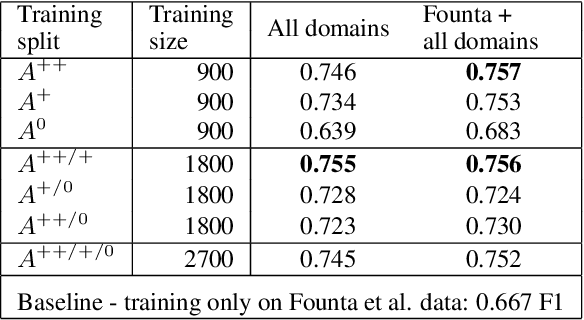
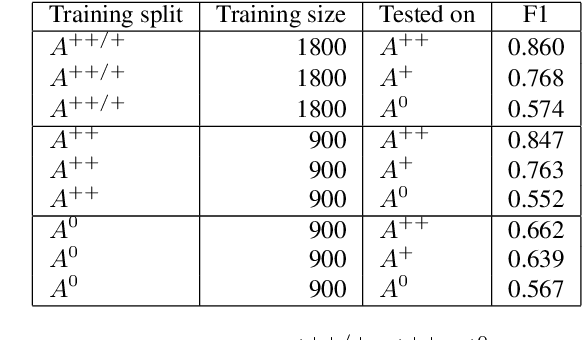
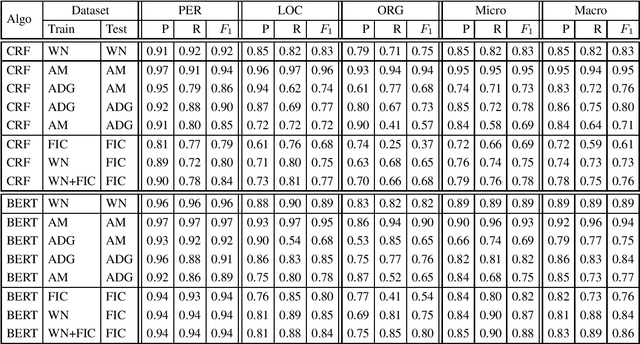
Since state-of-the-art approaches to offensive language detection rely on supervised learning, it is crucial to quickly adapt them to the continuously evolving scenario of social media. While several approaches have been proposed to tackle the problem from an algorithmic perspective, so to reduce the need for annotated data, less attention has been paid to the quality of these data. Following a trend that has emerged recently, we focus on the level of agreement among annotators while selecting data to create offensive language datasets, a task involving a high level of subjectivity. Our study comprises the creation of three novel datasets of English tweets covering different topics and having five crowd-sourced judgments each. We also present an extensive set of experiments showing that selecting training and test data according to different levels of annotators' agreement has a strong effect on classifiers performance and robustness. Our findings are further validated in cross-domain experiments and studied using a popular benchmark dataset. We show that such hard cases, where low agreement is present, are not necessarily due to poor-quality annotation and we advocate for a higher presence of ambiguous cases in future datasets, particularly in test sets, to better account for the different points of view expressed online.
Abuse is Contextual, What about NLP? The Role of Context in Abusive Language Annotation and Detection
Mar 27, 2021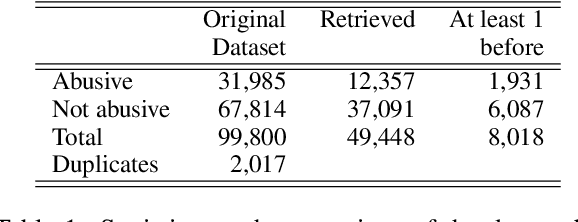


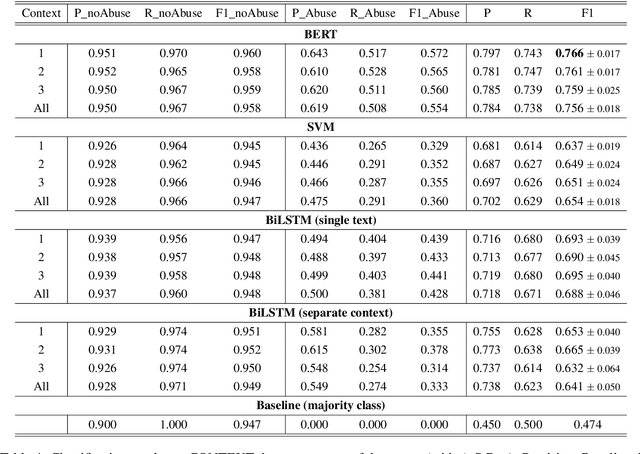
The datasets most widely used for abusive language detection contain lists of messages, usually tweets, that have been manually judged as abusive or not by one or more annotators, with the annotation performed at message level. In this paper, we investigate what happens when the hateful content of a message is judged also based on the context, given that messages are often ambiguous and need to be interpreted in the context of occurrence. We first re-annotate part of a widely used dataset for abusive language detection in English in two conditions, i.e. with and without context. Then, we compare the performance of three classification algorithms obtained on these two types of dataset, arguing that a context-aware classification is more challenging but also more similar to a real application scenario.
Creating a Multimodal Dataset of Images and Text to Study Abusive Language
May 05, 2020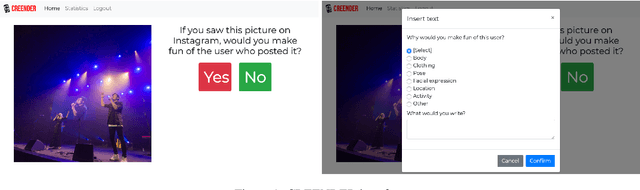

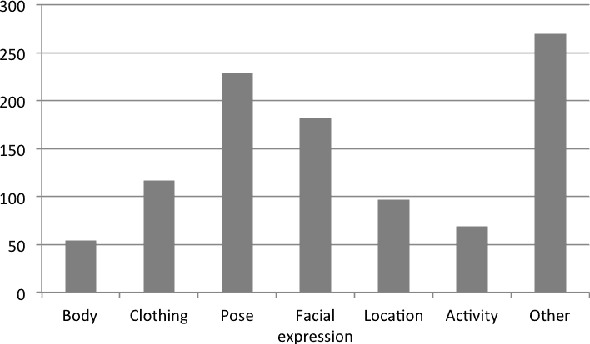
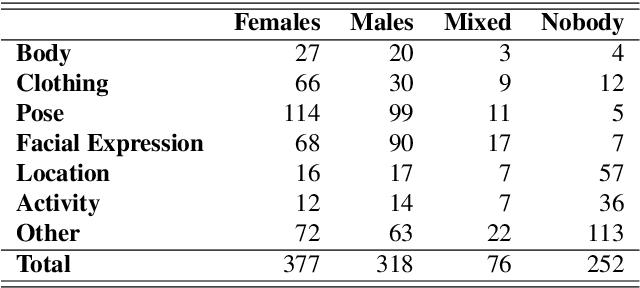
In order to study online hate speech, the availability of datasets containing the linguistic phenomena of interest are of crucial importance. However, when it comes to specific target groups, for example teenagers, collecting such data may be problematic due to issues with consent and privacy restrictions. Furthermore, while text-only datasets of this kind have been widely used, limitations set by image-based social media platforms like Instagram make it difficult for researchers to experiment with multimodal hate speech data. We therefore developed CREENDER, an annotation tool that has been used in school classes to create a multimodal dataset of images and abusive comments, which we make freely available under Apache 2.0 license. The corpus, with Italian comments, has been analysed from different perspectives, to investigate whether the subject of the images plays a role in triggering a comment. We find that users judge the same images in different ways, although the presence of a person in the picture increases the probability to get an offensive comment.
Italy goes to Stanford: a collection of CoreNLP modules for Italian
Apr 13, 2017
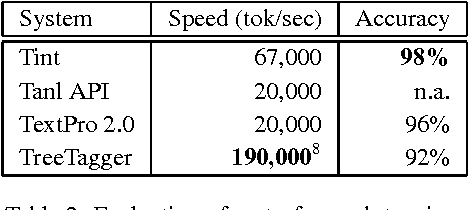
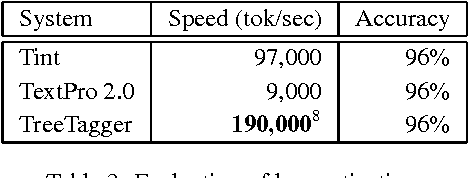
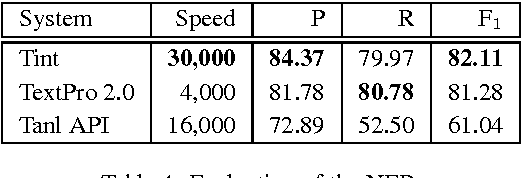
In this we paper present Tint, an easy-to-use set of fast, accurate and extendable Natural Language Processing modules for Italian. It is based on Stanford CoreNLP and is freely available as a standalone software or a library that can be integrated in an existing project.
On Coreferring Text-extracted Event Descriptions with the aid of Ontological Reasoning
Dec 01, 2016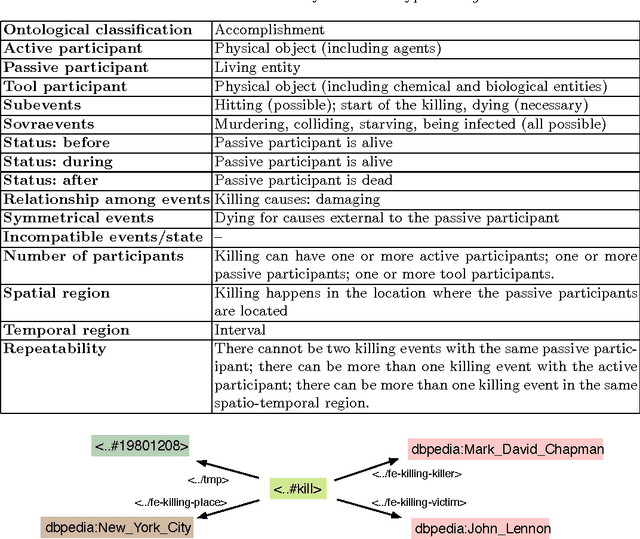

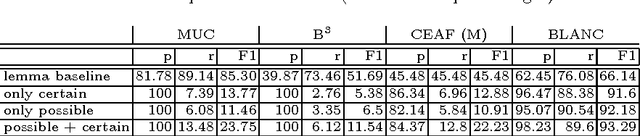
Systems for automatic extraction of semantic information about events from large textual resources are now available: these tools are capable to generate RDF datasets about text extracted events and this knowledge can be used to reason over the recognized events. On the other hand, text based tasks for event recognition, as for example event coreference (i.e. recognizing whether two textual descriptions refer to the same event), do not take into account ontological information of the extracted events in their process. In this paper, we propose a method to derive event coreference on text extracted event data using semantic based rule reasoning. We demonstrate our method considering a limited (yet representative) set of event types: we introduce a formal analysis on their ontological properties and, on the base of this, we define a set of coreference criteria. We then implement these criteria as RDF-based reasoning rules to be applied on text extracted event data. We evaluate the effectiveness of our approach over a standard coreference benchmark dataset.