Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIND: an Italian Multi-Domain Dataset for Named Entity Recognition
Paper and Code
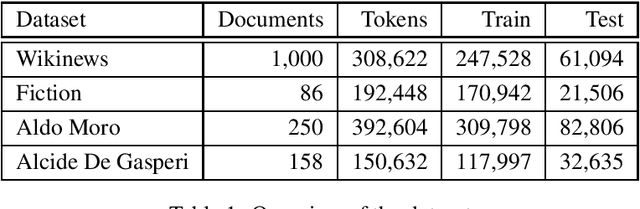
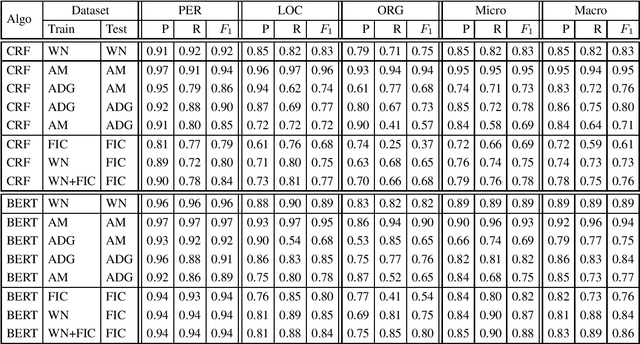
In this paper we present KIND, an Italian dataset for Named-Entity Recognition. It contains more than one million tokens with the annotation covering three classes: persons, locations, and organizations. Most of the dataset (around 600K tokens) contains manual gold annotations in three different domains: news, literature, and political discourses. Texts and annotations are downloadable for free from the Github repository.
View paper on