 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geography of Information Diffusion in Online Discourse on Europe and Migration
Feb 21, 2024The online diffusion of information related to Europe and migration has been little investigated from an external point of view. However, this is a very relevant topic, especially if users have had no direct contact with Europe and its perception depends solely on information retrieved online. In this work we analyse the information circulating online about Europe and migration after retrieving a large amount of data from social media (Twitter), to gain new insights into topics, magnitude, and dynamics of their diffusion. We combine retweets and hashtags network analysis with geolocation of users, linking thus data to geography and allowing analysis from an "outside Europe" perspective, with a special focus on Africa. We also introduce a novel approach based on cross-lingual quotes, i.e. when content in a language is commented and retweeted in another language, assuming these interactions are a proxy for connections between very distant communities. Results show how the majority of online discussions occurs at a national level, especially when discussing migration. Language (English) is pivotal for information to become transnational and reach far. Transnational information flow is strongly unbalanced, with content mainly produced in Europe and amplified outside. Conversely Europe-based accounts tend to be self-referential when they discuss migration-related topics. Football is the most exported topic from Europe worldwide. Moreover, important nodes in the communities discussing migration-related topics include accounts of official institutions and international agencies, together with journalists, news, commentators and activists.
SemEval-2023 Task 11: Learning With Disagreements (LeWiDi)
Apr 28, 2023NLP datasets annotated with human judgments are rife with disagreements between the judges. This is especially true for tasks depending on subjective judgments such as sentiment analysis or offensive language detection. Particularly in these latter cases, the NLP community has come to realize that the approach of 'reconciling' these different subjective interpretations is inappropriate. Many NLP researchers have therefore concluded that rather than eliminating disagreements from annotated corpora, we should preserve them-indeed, some argue that corpora should aim to preserve all annotator judgments. But this approach to corpus creation for NLP has not yet been widely accepted. The objective of the LeWiDi series of shared tasks is to promote this approach to developing NLP models by providing a unified framework for training and evaluating with such datasets. We report on the second LeWiDi shared task, which differs from the first edition in three crucial respects: (i) it focuses entirely on NLP, instead of both NLP and computer vision tasks in its first edition; (ii) it focuses on subjective tasks, instead of covering different types of disagreements-as training with aggregated labels for subjective NLP tasks is a particularly obvious misrepresentation of the data; and (iii) for the evaluation, we concentrate on soft approaches to evaluation. This second edition of LeWiDi attracted a wide array of participants resulting in 13 shared task submission papers.
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators' Disagreement
Sep 28, 2021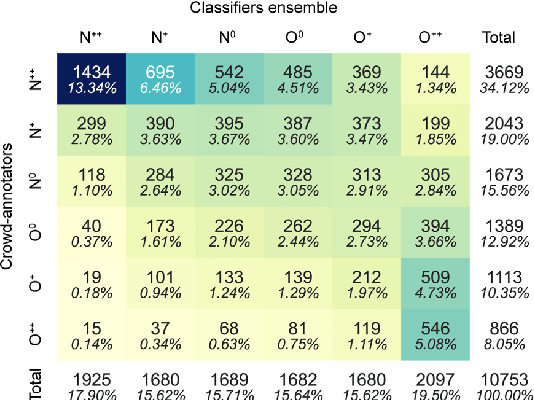

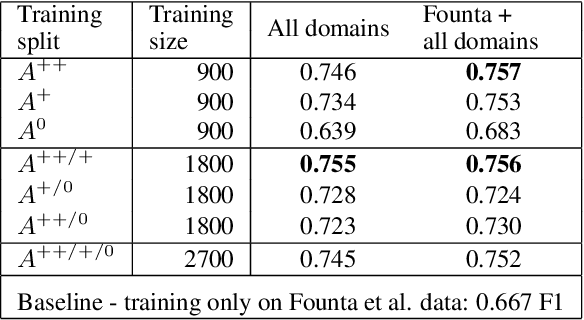
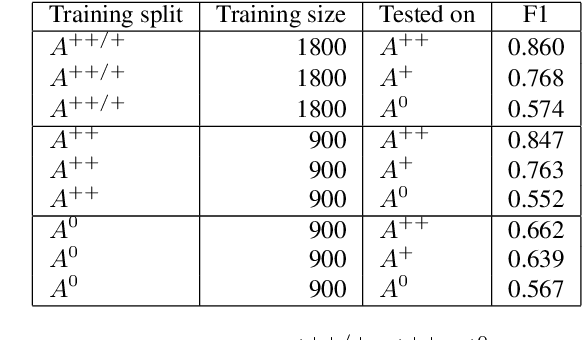
Since state-of-the-art approaches to offensive language detection rely on supervised learning, it is crucial to quickly adapt them to the continuously evolving scenario of social media. While several approaches have been proposed to tackle the problem from an algorithmic perspective, so to reduce the need for annotated data, less attention has been paid to the quality of these data. Following a trend that has emerged recently, we focus on the level of agreement among annotators while selecting data to create offensive language datasets, a task involving a high level of subjectivity. Our study comprises the creation of three novel datasets of English tweets covering different topics and having five crowd-sourced judgments each. We also present an extensive set of experiments showing that selecting training and test data according to different levels of annotators' agreement has a strong effect on classifiers performance and robustness. Our findings are further validated in cross-domain experiments and studied using a popular benchmark dataset. We show that such hard cases, where low agreement is present, are not necessarily due to poor-quality annotation and we advocate for a higher presence of ambiguous cases in future datasets, particularly in test sets, to better account for the different points of view expressed online.
Monolingual and Cross-Lingual Acceptability Judgments with the Italian CoLA corpus
Sep 24, 2021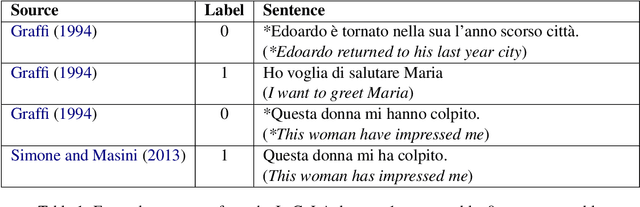
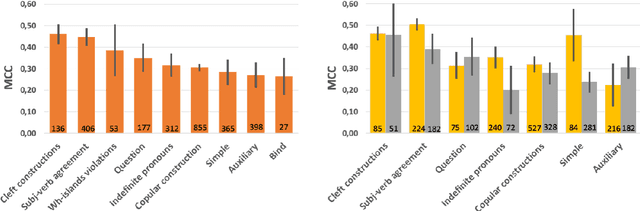
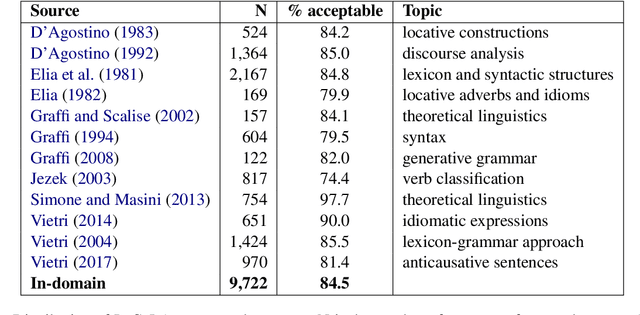
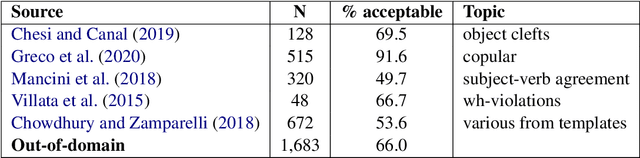
The development of automated approaches to linguistic acceptability has been greatly fostered by the availability of the English CoLA corpus, which has also been included in the widely used GLUE benchmark. However, this kind of research for languages other than English, as well as the analysis of cross-lingual approaches, has been hindered by the lack of resources with a comparable size in other languages. We have therefore developed the ItaCoLA corpus, containing almost 10,000 sentences with acceptability judgments, which has been created following the same approach and the same steps as the English one. In this paper we describe the corpus creation, we detail its content, and we present the first experiments on this new resource. We compare in-domain and out-of-domain classification, and perform a specific evaluation of nine linguistic phenomena. We also present the first cross-lingual experiments, aimed at assessing whether multilingual transformerbased approaches can benefit from using sentences in two languages during fine-tuning.