 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonolingual and Cross-Lingual Acceptability Judgments with the Italian CoLA corpus
Paper and Code
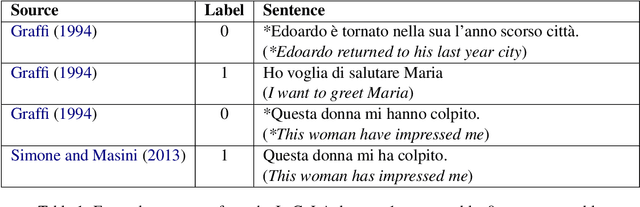
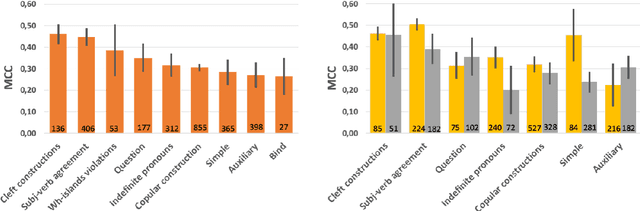
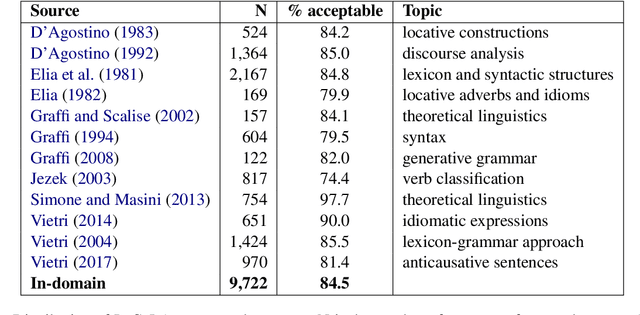
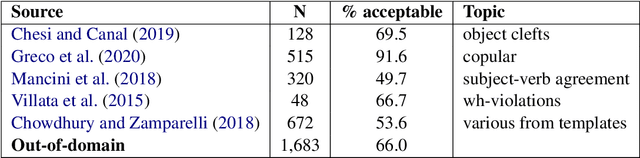
The development of automated approaches to linguistic acceptability has been greatly fostered by the availability of the English CoLA corpus, which has also been included in the widely used GLUE benchmark. However, this kind of research for languages other than English, as well as the analysis of cross-lingual approaches, has been hindered by the lack of resources with a comparable size in other languages. We have therefore developed the ItaCoLA corpus, containing almost 10,000 sentences with acceptability judgments, which has been created following the same approach and the same steps as the English one. In this paper we describe the corpus creation, we detail its content, and we present the first experiments on this new resource. We compare in-domain and out-of-domain classification, and perform a specific evaluation of nine linguistic phenomena. We also present the first cross-lingual experiments, aimed at assessing whether multilingual transformerbased approaches can benefit from using sentences in two languages during fine-tuning.