 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Transfer Learning for Acceptability Judgements
Jan 15, 2024Hybrid quantum-classical classifiers promise to positively impact critical aspects of natural language processing tasks, particularly classification-related ones. Among the possibilities currently investigated, quantum transfer learning, i.e., using a quantum circuit for fine-tuning pre-trained classical models for a specific task, is attracting significant attention as a potential platform for proving quantum advantage. This work shows potential advantages, both in terms of performance and expressiveness, of quantum transfer learning algorithms trained on embedding vectors extracted from a large language model to perform classification on a classical Linguistics task: acceptability judgments. Acceptability judgment is the ability to determine whether a sentence is considered natural and well-formed by a native speaker. The approach has been tested on sentences extracted from ItaCoLa, a corpus that collects Italian sentences labeled with their acceptability judgment. The evaluation phase shows results for the quantum transfer learning pipeline comparable to state-of-the-art classical transfer learning algorithms, proving current quantum computers' capabilities to tackle NLP tasks for ready-to-use applications. Furthermore, a qualitative linguistic analysis, aided by explainable AI methods, reveals the capabilities of quantum transfer learning algorithms to correctly classify complex and more structured sentences, compared to their classical counterpart. This finding sets the ground for a quantifiable quantum advantage in NLP in the near future.
Monolingual and Cross-Lingual Acceptability Judgments with the Italian CoLA corpus
Sep 24, 2021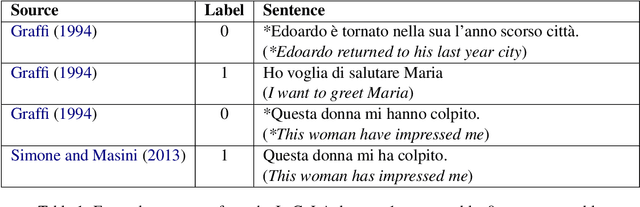
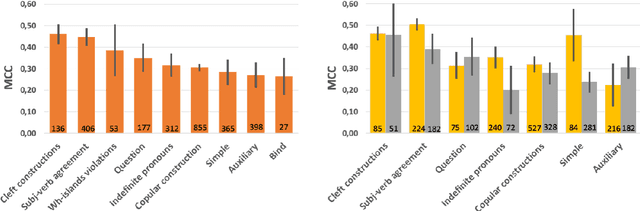
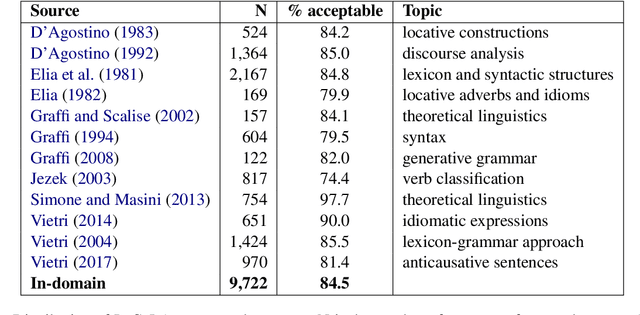
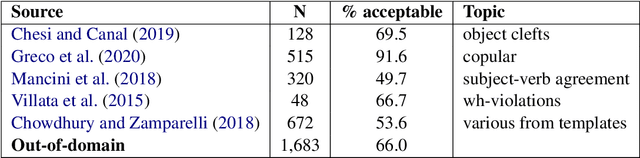
The development of automated approaches to linguistic acceptability has been greatly fostered by the availability of the English CoLA corpus, which has also been included in the widely used GLUE benchmark. However, this kind of research for languages other than English, as well as the analysis of cross-lingual approaches, has been hindered by the lack of resources with a comparable size in other languages. We have therefore developed the ItaCoLA corpus, containing almost 10,000 sentences with acceptability judgments, which has been created following the same approach and the same steps as the English one. In this paper we describe the corpus creation, we detail its content, and we present the first experiments on this new resource. We compare in-domain and out-of-domain classification, and perform a specific evaluation of nine linguistic phenomena. We also present the first cross-lingual experiments, aimed at assessing whether multilingual transformerbased approaches can benefit from using sentences in two languages during fine-tuning.