 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
Grounded Misunderstandings in Asymmetric Dialogue: A Perspectivist Annotation Scheme for MapTask
Nov 05, 2025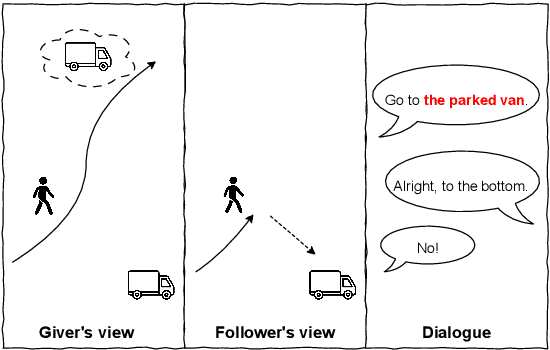
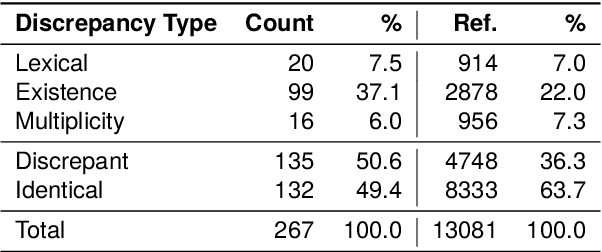

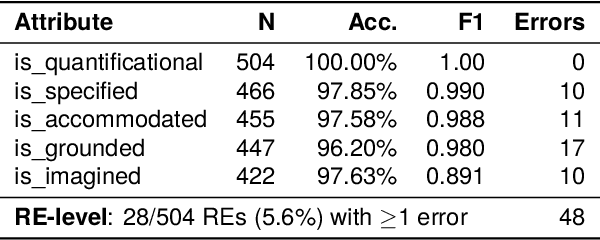
Collaborative dialogue relies on participants incrementally establishing common ground, yet in asymmetric settings they may believe they agree while referring to different entities. We introduce a perspectivist annotation scheme for the HCRC MapTask corpus (Anderson et al., 1991) that separately captures speaker and addressee grounded interpretations for each reference expression, enabling us to trace how understanding emerges, diverges, and repairs over time. Using a scheme-constrained LLM annotation pipeline, we obtain 13k annotated reference expressions with reliability estimates and analyze the resulting understanding states. The results show that full misunderstandings are rare once lexical variants are unified, but multiplicity discrepancies systematically induce divergences, revealing how apparent grounding can mask referential misalignment. Our framework provides both a resource and an analytic lens for studying grounded misunderstanding and for evaluating (V)LLMs' capacity to model perspective-dependent grounding in collaborative dialogue.
Can LLMs Detect Ambiguous Plural Reference? An Analysis of Split-Antecedent and Mereological Reference
Oct 06, 2025Our goal is to study how LLMs represent and interpret plural reference in ambiguous and unambiguous contexts. We ask the following research questions: (1) Do LLMs exhibit human-like preferences in representing plural reference? (2) Are LLMs able to detect ambiguity in plural anaphoric expressions and identify possible referents? To address these questions, we design a set of experiments, examining pronoun production using next-token prediction tasks, pronoun interpretation, and ambiguity detection using different prompting strategies. We then assess how comparable LLMs are to humans in formulating and interpreting plural reference. We find that LLMs are sometimes aware of possible referents of ambiguous pronouns. However, they do not always follow human reference when choosing between interpretations, especially when the possible interpretation is not explicitly mentioned. In addition, they struggle to identify ambiguity without direct instruction. Our findings also reveal inconsistencies in the results across different types of experiments.
Assessing the Reliability of LLMs Annotations in the Context of Demographic Bias and Model Explanation
Jul 17, 2025Understanding the sources of variability in annotations is crucial for developing fair NLP systems, especially for tasks like sexism detection where demographic bias is a concern. This study investigates the extent to which annotator demographic features influence labeling decisions compared to text content. Using a Generalized Linear Mixed Model, we quantify this inf luence, finding that while statistically present, demographic factors account for a minor fraction ( 8%) of the observed variance, with tweet content being the dominant factor. We then assess the reliability of Generative AI (GenAI) models as annotators, specifically evaluating if guiding them with demographic personas improves alignment with human judgments. Our results indicate that simplistic persona prompting often fails to enhance, and sometimes degrades, performance compared to baseline models. Furthermore, explainable AI (XAI) techniques reveal that model predictions rely heavily on content-specific tokens related to sexism, rather than correlates of demographic characteristics. We argue that focusing on content-driven explanations and robust annotation protocols offers a more reliable path towards fairness than potentially persona simulation.
Ancient Script Image Recognition and Processing: A Review
Jun 24, 2025Ancient scripts, e.g., Egyptian hieroglyphs, Oracle Bone Inscriptions, and Ancient Greek inscriptions, serve as vital carriers of human civilization, embedding invaluable historical and cultural information. Automating ancient script image recognition has gained importance, enabling large-scale interpretation and advancing research in archaeology and digital humanities. With the rise of deep learning, this field has progressed rapidly, with numerous script-specific datasets and models proposed. While these scripts vary widely, spanning phonographic systems with limited glyphs to logographic systems with thousands of complex symbols, they share common challenges and methodological overlaps. Moreover, ancient scripts face unique challenges, including imbalanced data distribution and image degradation, which have driven the development of various dedicated methods. This survey provides a comprehensive review of ancient script image recognition methods. We begin by categorizing existing studies based on script types and analyzing respective recognition methods, highlighting both their differences and shared strategies. We then focus on challenges unique to ancient scripts, systematically examining their impact and reviewing recent solutions, including few-shot learning and noise-robust techniques. Finally, we summarize current limitations and outline promising future directions. Our goal is to offer a structured, forward-looking perspective to support ongoing advancements in the recognition, interpretation, and decipherment of ancient scripts.
Data Augmentation for Fake Reviews Detection in Multiple Languages and Multiple Domains
Apr 09, 2025



With the growth of the Internet, buying habits have changed, and customers have become more dependent on the online opinions of other customers to guide their purchases. Identifying fake reviews thus became an important area for Natural Language Processing (NLP) research. However, developing high-performance NLP models depends on the availability of large amounts of training data, which are often not available for low-resource languages or domains. In this research, we used large language models to generate datasets to train fake review detectors. Our approach was used to generate fake reviews in different domains (book reviews, restaurant reviews, and hotel reviews) and different languages (English and Chinese). Our results demonstrate that our data augmentation techniques result in improved performance at fake review detection for all domains and languages. The accuracy of our fake review detection model can be improved by 0.3 percentage points on DeRev TEST, 10.9 percentage points on Amazon TEST, 8.3 percentage points on Yelp TEST and 7.2 percentage points on DianPing TEST using the augmented datasets.
Understanding The Effect Of Temperature On Alignment With Human Opinions
Nov 15, 2024



With the increasing capabilities of LLMs, recent studies focus on understanding whose opinions are represented by them and how to effectively extract aligned opinion distributions. We conducted an empirical analysis of three straightforward methods for obtaining distributions and evaluated the results across a variety of metrics. Our findings suggest that sampling and log-probability approaches with simple parameter adjustments can return better aligned outputs in subjective tasks compared to direct prompting. Yet, assuming models reflect human opinions may be limiting, highlighting the need for further research on how human subjectivity affects model uncertainty.
ClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024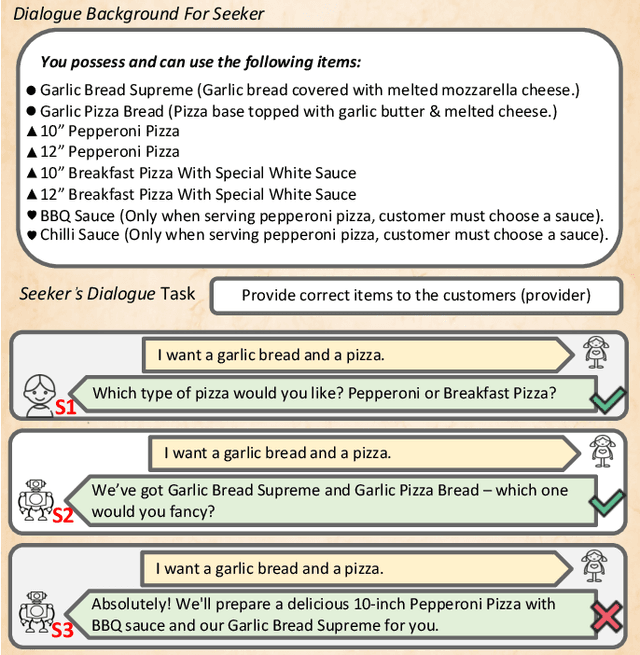



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
A LLM Benchmark based on the Minecraft Builder Dialog Agent Task
Jul 17, 2024In this work we proposing adapting the Minecraft builder task into an LLM benchmark suitable for evaluating LLM ability in spatially orientated tasks, and informing builder agent design. Previous works have proposed corpora with varying complex structures, and human written instructions. We instead attempt to provide a comprehensive synthetic benchmark for testing builder agents over a series of distinct tasks that comprise of common building operations. We believe this approach allows us to probe specific strengths and weaknesses of different agents, and test the ability of LLMs in the challenging area of spatial reasoning and vector based math.
The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
May 02, 2024Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.