 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Crowdsourced and Automatic Judgments to Scale Up a Corpus of Anaphoric Reference for Fiction and Wikipedia Texts
Oct 11, 2022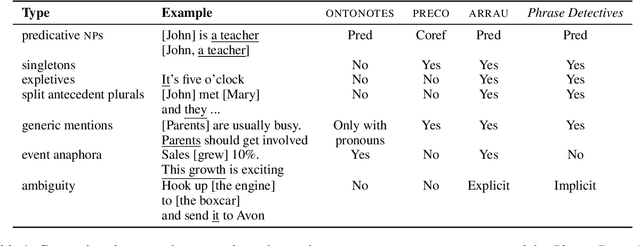


Although several datasets annotated for anaphoric reference/coreference exist, even the largest such datasets have limitations in terms of size, range of domains, coverage of anaphoric phenomena, and size of documents included. Yet, the approaches proposed to scale up anaphoric annotation haven't so far resulted in datasets overcoming these limitations. In this paper, we introduce a new release of a corpus for anaphoric reference labelled via a game-with-a-purpose. This new release is comparable in size to the largest existing corpora for anaphoric reference due in part to substantial activity by the players, in part thanks to the use of a new resolve-and-aggregate paradigm to 'complete' markable annotations through the combination of an anaphoric resolver and an aggregation method for anaphoric reference. The proposed method could be adopted to greatly speed up annotation time in other projects involving games-with-a-purpose. In addition, the corpus covers genres for which no comparable size datasets exist (Fiction and Wikipedia); it covers singletons and non-referring expressions; and it includes a substantial number of long documents (> 2K in length).
Scoring Coreference Chains with Split-Antecedent Anaphors
May 24, 2022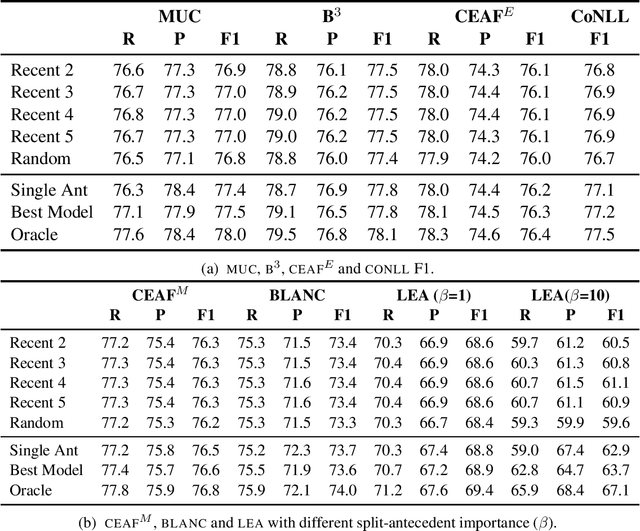


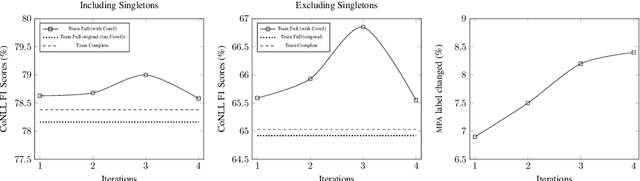
Anaphoric reference is an aspect of language interpretation covering a variety of types of interpretation beyond the simple case of identity reference to entities introduced via nominal expressions covered by the traditional coreference task in its most recent incarnation in ONTONOTES and similar datasets. One of these cases that go beyond simple coreference is anaphoric reference to entities that must be added to the discourse model via accommodation, and in particular split-antecedent references to entities constructed out of other entities, as in split-antecedent plurals and in some cases of discourse deixis. Although this type of anaphoric reference is now annotated in many datasets, systems interpreting such references cannot be evaluated using the Reference coreference scorer Pradhan et al. (2014). As part of the work towards a new scorer for anaphoric reference able to evaluate all aspects of anaphoric interpretation in the coverage of the Universal Anaphora initiative, we propose in this paper a solution to the technical problem of generalizing existing metrics for identity anaphora so that they can also be used to score cases of split-antecedents. This is the first such proposal in the literature on anaphora or coreference, and has been successfully used to score both split-antecedent plural references and discourse deixis in the recent CODI/CRAC anaphora resolution in dialogue shared tasks.
Stay Together: A System for Single and Split-antecedent Anaphora Resolution
Apr 12, 2021



The state-of-the-art on basic, single-antecedent anaphora has greatly improved in recent years. Researchers have therefore started to pay more attention to more complex cases of anaphora such as split-antecedent anaphora, as in Time-Warner is considering a legal challenge to Telecommunications Inc's plan to buy half of Showtime Networks Inc-a move that could lead to all-out war between the two powerful companies. Split-antecedent anaphora is rarer and more complex to resolve than single-antecedent anaphora; as a result, it is not annotated in many datasets designed to test coreference, and previous work on resolving this type of anaphora was carried out in unrealistic conditions that assume gold mentions and/or gold split-antecedent anaphors are available. These systems also focus on split-antecedent anaphors only. In this work, we introduce a system that resolves both single and split-antecedent anaphors, and evaluate it in a more realistic setting that uses predicted mentions. We also start addressing the question of how to evaluate single and split-antecedent anaphors together using standard coreference evaluation metrics.
Free the Plural: Unrestricted Split-Antecedent Anaphora Resolution
Oct 31, 2020

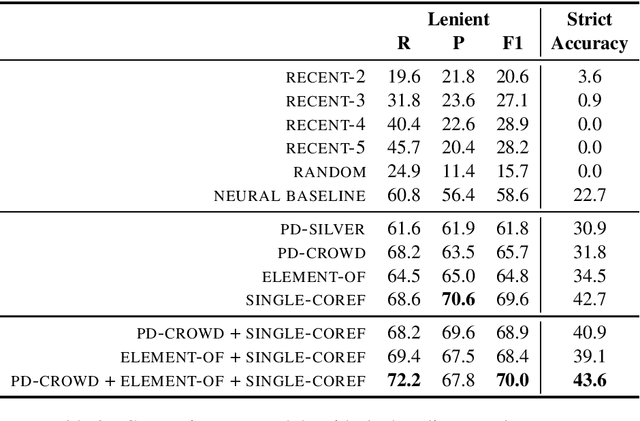
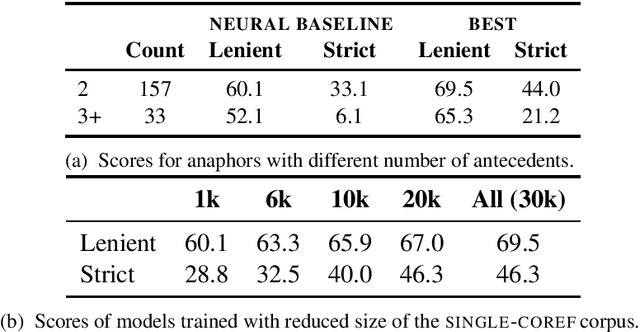
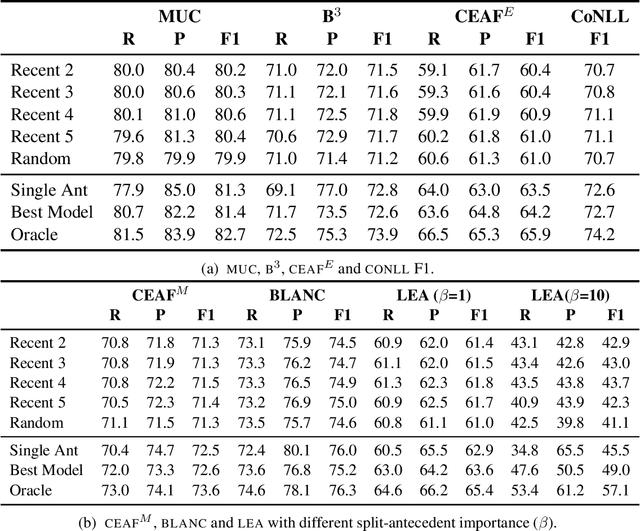
Now that the performance of coreference resolvers on the simpler forms of anaphoric reference has greatly improved, more attention is devoted to more complex aspects of anaphora. One limitation of virtually all coreference resolution models is the focus on single-antecedent anaphors. Plural anaphors with multiple antecedents-so-called split-antecedent anaphors (as in John met Mary. They went to the movies) have not been widely studied, because they are not annotated in ONTONOTES and are relatively infrequent in other corpora. In this paper, we introduce the first model for unrestricted resolution of split-antecedent anaphors. We start with a strong baseline enhanced by BERT embeddings, and show that we can substantially improve its performance by addressing the sparsity issue. To do this, we experiment with auxiliary corpora where split-antecedent anaphors were annotated by the crowd, and with transfer learning models using element-of bridging references and single-antecedent coreference as auxiliary tasks. Evaluation on the gold annotated ARRAU corpus shows that the out best model uses a combination of three auxiliary corpora achieved F1 scores of 70% and 43.6% when evaluated in a lenient and strict setting, respectively, i.e., 11 and 21 percentage points gain when compared with our baseline.