 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.
Multi-Objective Mobile Damped Wave Algorithm (MOMDWA): A Novel Approach For Quantum System Control
Feb 06, 2025



In this paper, we introduce a novel multi-objective optimization algorithm, the Multi-Objective Mobile Damped Wave Algorithm (MOMDWA), specifically designed to address complex quantum control problems. Our approach extends the capabilities of the original Mobile Damped Wave Algorithm (MDWA) by incorporating multiple objectives, enabling a more comprehensive optimization process. We applied MOMDWA to three quantum control scenarios, focusing on optimizing the balance between control fidelity, energy consumption, and control smoothness. The results demonstrate that MOMDWA significantly enhances quantum control efficiency and robustness, achieving high fidelity while minimizing energy use and ensuring smooth control pulses. This advancement offers a valuable tool for quantum computing and other domains requiring precise, multi-objective control.
Aggregating Crowdsourced and Automatic Judgments to Scale Up a Corpus of Anaphoric Reference for Fiction and Wikipedia Texts
Oct 11, 2022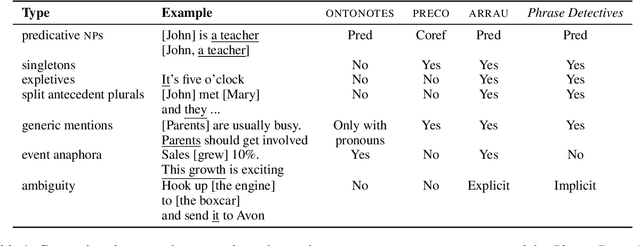


Although several datasets annotated for anaphoric reference/coreference exist, even the largest such datasets have limitations in terms of size, range of domains, coverage of anaphoric phenomena, and size of documents included. Yet, the approaches proposed to scale up anaphoric annotation haven't so far resulted in datasets overcoming these limitations. In this paper, we introduce a new release of a corpus for anaphoric reference labelled via a game-with-a-purpose. This new release is comparable in size to the largest existing corpora for anaphoric reference due in part to substantial activity by the players, in part thanks to the use of a new resolve-and-aggregate paradigm to 'complete' markable annotations through the combination of an anaphoric resolver and an aggregation method for anaphoric reference. The proposed method could be adopted to greatly speed up annotation time in other projects involving games-with-a-purpose. In addition, the corpus covers genres for which no comparable size datasets exist (Fiction and Wikipedia); it covers singletons and non-referring expressions; and it includes a substantial number of long documents (> 2K in length).
Scoring Coreference Chains with Split-Antecedent Anaphors
May 24, 2022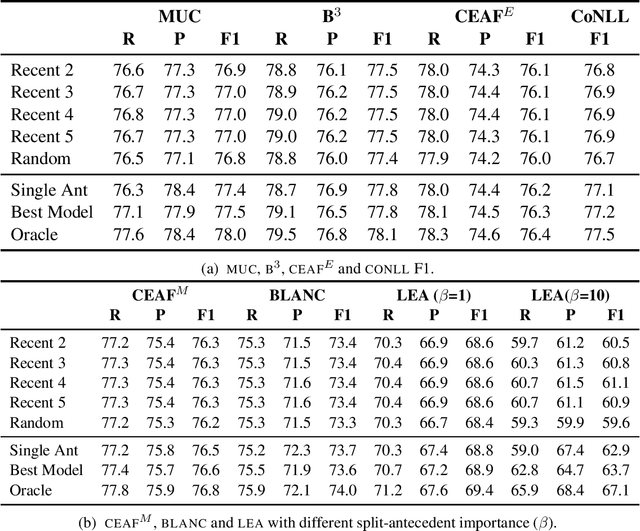

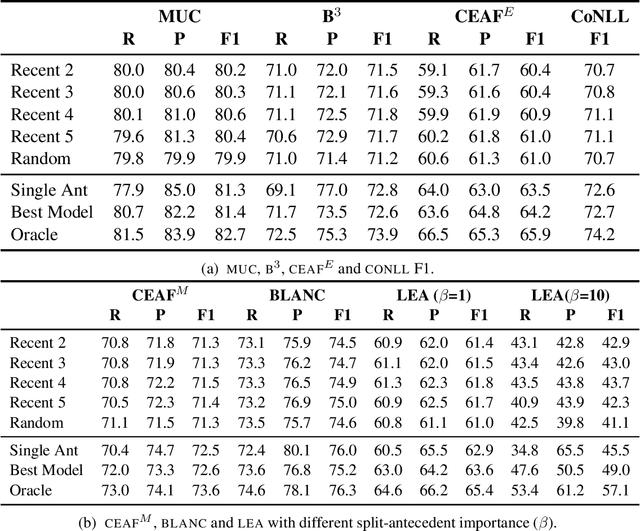

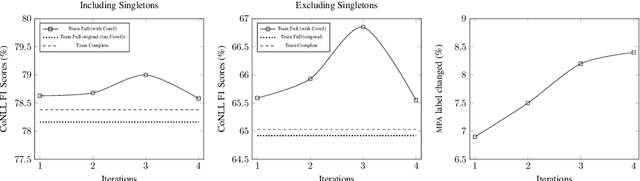
Anaphoric reference is an aspect of language interpretation covering a variety of types of interpretation beyond the simple case of identity reference to entities introduced via nominal expressions covered by the traditional coreference task in its most recent incarnation in ONTONOTES and similar datasets. One of these cases that go beyond simple coreference is anaphoric reference to entities that must be added to the discourse model via accommodation, and in particular split-antecedent references to entities constructed out of other entities, as in split-antecedent plurals and in some cases of discourse deixis. Although this type of anaphoric reference is now annotated in many datasets, systems interpreting such references cannot be evaluated using the Reference coreference scorer Pradhan et al. (2014). As part of the work towards a new scorer for anaphoric reference able to evaluate all aspects of anaphoric interpretation in the coverage of the Universal Anaphora initiative, we propose in this paper a solution to the technical problem of generalizing existing metrics for identity anaphora so that they can also be used to score cases of split-antecedents. This is the first such proposal in the literature on anaphora or coreference, and has been successfully used to score both split-antecedent plural references and discourse deixis in the recent CODI/CRAC anaphora resolution in dialogue shared tasks.
Stay Together: A System for Single and Split-antecedent Anaphora Resolution
Apr 12, 2021



The state-of-the-art on basic, single-antecedent anaphora has greatly improved in recent years. Researchers have therefore started to pay more attention to more complex cases of anaphora such as split-antecedent anaphora, as in Time-Warner is considering a legal challenge to Telecommunications Inc's plan to buy half of Showtime Networks Inc-a move that could lead to all-out war between the two powerful companies. Split-antecedent anaphora is rarer and more complex to resolve than single-antecedent anaphora; as a result, it is not annotated in many datasets designed to test coreference, and previous work on resolving this type of anaphora was carried out in unrealistic conditions that assume gold mentions and/or gold split-antecedent anaphors are available. These systems also focus on split-antecedent anaphors only. In this work, we introduce a system that resolves both single and split-antecedent anaphors, and evaluate it in a more realistic setting that uses predicted mentions. We also start addressing the question of how to evaluate single and split-antecedent anaphors together using standard coreference evaluation metrics.
Neural Coreference Resolution for Arabic
Oct 31, 2020
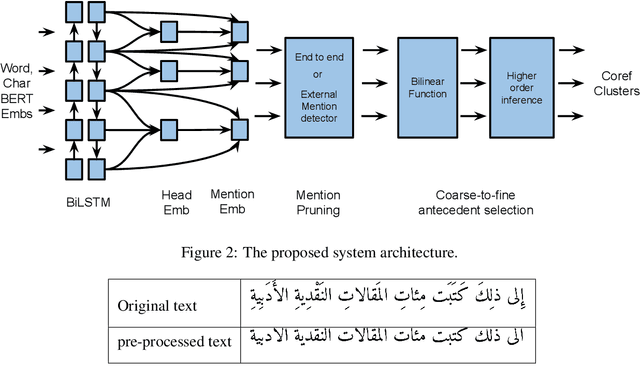
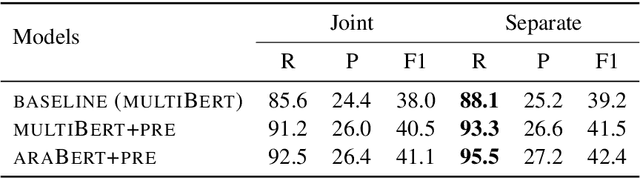
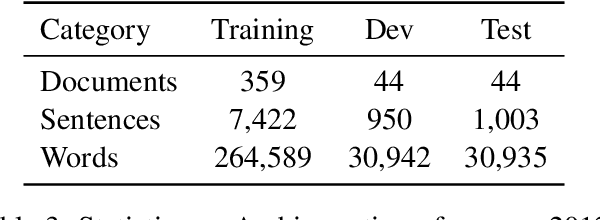
No neural coreference resolver for Arabic exists, in fact we are not aware of any learning-based coreference resolver for Arabic since (Bjorkelund and Kuhn, 2014). In this paper, we introduce a coreference resolution system for Arabic based on Lee et al's end to end architecture combined with the Arabic version of bert and an external mention detector. As far as we know, this is the first neural coreference resolution system aimed specifically to Arabic, and it substantially outperforms the existing state of the art on OntoNotes 5.0 with a gain of 15.2 points conll F1. We also discuss the current limitations of the task for Arabic and possible approaches that can tackle these challenges.
Free the Plural: Unrestricted Split-Antecedent Anaphora Resolution
Oct 31, 2020

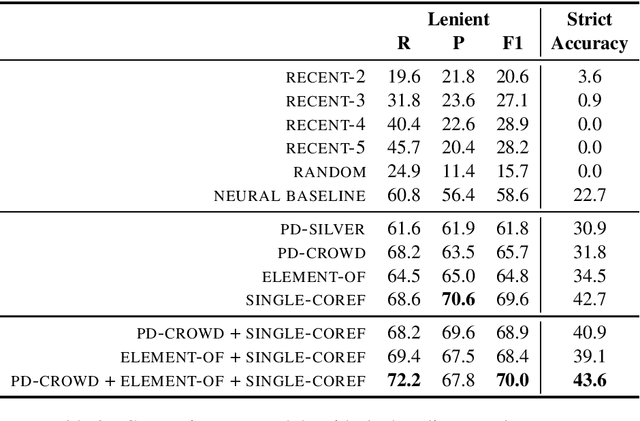
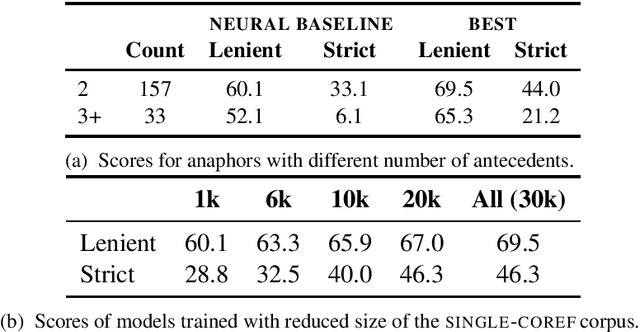
Now that the performance of coreference resolvers on the simpler forms of anaphoric reference has greatly improved, more attention is devoted to more complex aspects of anaphora. One limitation of virtually all coreference resolution models is the focus on single-antecedent anaphors. Plural anaphors with multiple antecedents-so-called split-antecedent anaphors (as in John met Mary. They went to the movies) have not been widely studied, because they are not annotated in ONTONOTES and are relatively infrequent in other corpora. In this paper, we introduce the first model for unrestricted resolution of split-antecedent anaphors. We start with a strong baseline enhanced by BERT embeddings, and show that we can substantially improve its performance by addressing the sparsity issue. To do this, we experiment with auxiliary corpora where split-antecedent anaphors were annotated by the crowd, and with transfer learning models using element-of bridging references and single-antecedent coreference as auxiliary tasks. Evaluation on the gold annotated ARRAU corpus shows that the out best model uses a combination of three auxiliary corpora achieved F1 scores of 70% and 43.6% when evaluated in a lenient and strict setting, respectively, i.e., 11 and 21 percentage points gain when compared with our baseline.
Named Entity Recognition as Dependency Parsing
Jun 13, 2020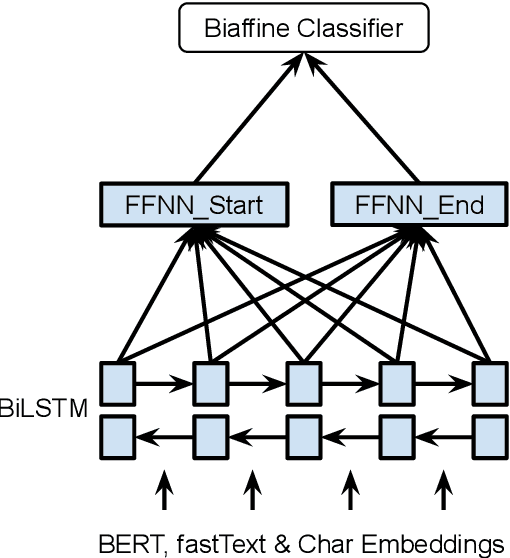



Named Entity Recognition (NER) is a fundamental task in Natural Language Processing, concerned with identifying spans of text expressing references to entities. NER research is often focused on flat entities only (flat NER), ignoring the fact that entity references can be nested, as in [Bank of [China]] (Finkel and Manning, 2009). In this paper, we use ideas from graph-based dependency parsing to provide our model a global view on the input via a biaffine model (Dozat and Manning, 2017). The biaffine model scores pairs of start and end tokens in a sentence which we use to explore all spans, so that the model is able to predict named entities accurately. We show that the model works well for both nested and flat NER through evaluation on 8 corpora and achieving SoTA performance on all of them, with accuracy gains of up to 2.2 percentage points.
Multi-task Learning Based Neural Bridging Reference Resolution
Mar 07, 2020



We propose a multi task learning-based neural model for bridging reference resolution tackling two key challenges faced by bridging reference resolution. The first challenge is the lack of large corpora annotated with bridging references. To address this, we use multi-task learning to help bridging reference resolution with coreference resolution. We show that substantial improvements of up to 8 p.p. can be achieved on full bridging resolution with this architecture. The second challenge is the different definitions of bridging used in different corpora, meaning that hand-coded systems or systems using special features designed for one corpus do not work well with other corpora. Our neural model only uses a small number of corpus independent features, thus can be applied easily to different corpora. Evaluations with very different bridging corpora (ARRAU, ISNOTES, BASHI and SCICORP) suggest that our architecture works equally well on all corpora, and achieves the SoTA results on full bridging resolution for all corpora, outperforming the best reported results by up to 34.9 percentage points.